1、什么是LLVM
LLVM最初是Low Level Virtual Machine的缩写,定位是一个比较底层的虚拟机。但是LLVM本身并不是一个完整的编译器,LLVM是一个编译器基础架构(infrastructure,把很多编译器需要的功能以可调用的模块形式实现出来并包装成库,供其他编译器实现者可以根据自己的需要选择使用或者扩展。主要聚焦于编译器后端功能,如代码生成、代码优化、JIT等。
可以参考官网的解释

LLVM最初是在2000年由伊利诺伊大学香槟分校(UUIC)的学生Chris Lattner及其硕士顾问Vikram Adve创建的研究项目,并在2003年发布第一个正式版本,目的是提供一种基于SSA的现代编译策略,这种策略能够支持任何编程语言的静态和动态编译。
2、架构区别
传统的编译器架构

- Frontend:前端
词法分析、语法分析、语义分析、生成中间代码 - Optimizer:优化器
中间代码优化 - Backend:后端
生成机器码
LLVM架构
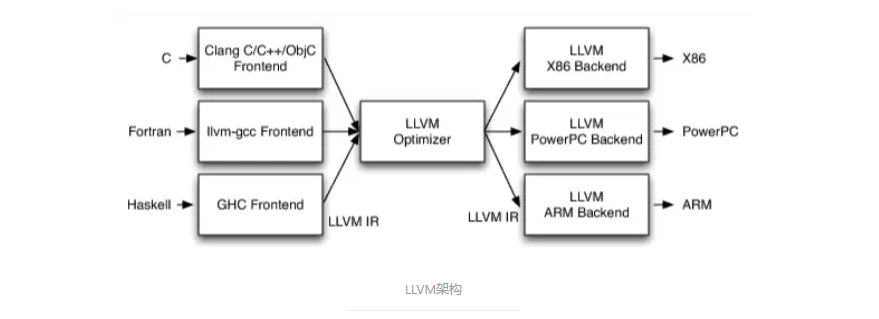
不同的前端后端使用统一的中间代码LLVM Intermediate Representation (LLVM IR)
如果需要支持一种新的编程语言,那么只需要实现一个新的前端
如果需要支持一种新的硬件设备,那么只需要实现一个新的后端
优化阶段是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改
相比之下,GCC的前端和后端没分得太开,前端后端耦合在了一起。所以GCC为了支持一门新的语言,或者为了支持一个新的目标平台,就变得特别困难
LLVM现在被作为实现各种静态和运行时编译语言的通用基础结构(GCC家族、Java、.NET、Python、Ruby、Scheme、Haskell、D等)
3、什么是Clang
LLVM项目的一个子项目,基于LLVM架构的C/C++/Objective-C编译器前端。
相比于GCC,Clang的优点
- 编译速度快:在某些平台上,Clang的编译速度显著的快过GCC(Debug模式下编译OC速度比GGC快3倍)
- 占用内存小:Clang生成的AST所占用的内存是GCC的五分之一左右
- 模块化设计:Clang采用基于库的模块化设计,易于 IDE 集成及其他用途的重用
- 诊断信息可读性强:在编译过程中,Clang创建并保留了大量详细的元数据 (metadata),有利于调试和错误报告
- 设计清晰简单,容易理解,易于扩展增强
Clang与LLVM关系
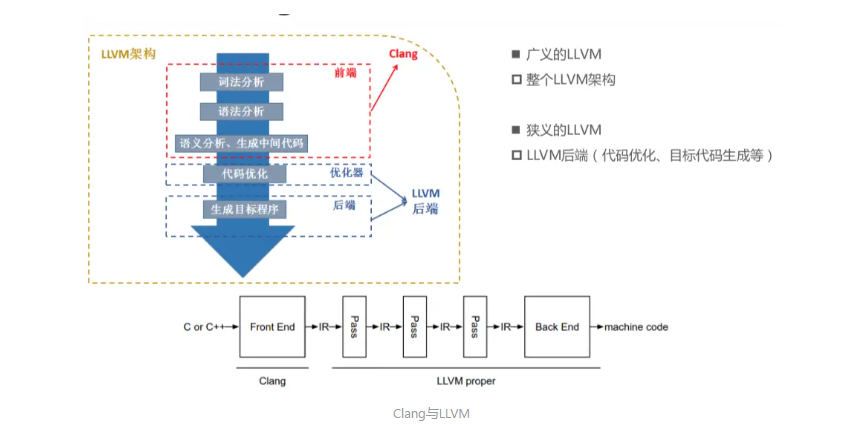
LLVM整体架构,前端用的是clang。
广义的LLVM是指整个LLVM架构,一般狭义的LLVM指的是LLVM后端(包含代码优化和目标代码生成)。
源代码(c/c++)经过clang–> 中间代码(经过一系列的优化,优化用的是Pass) –> 机器码
这里的Pass是做优化,而对于ollvm来说就是在pass时对ir进行混淆
4、代码混淆
定义:代码混淆是将计算机程序的代码,转换成一种功能上等价,但是难以阅读和理解的形式的行为。
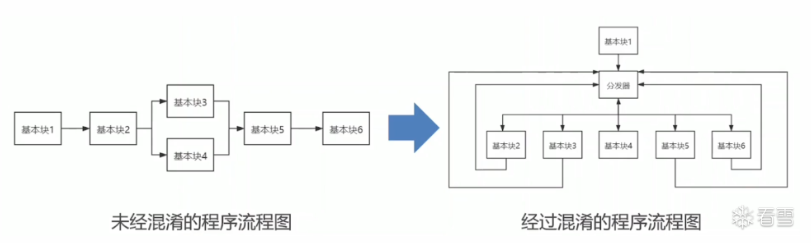
代码执行由顺序图转为分发器控制,使难以分清原来程序的逻辑。
学习混淆的意义
对于软件开发者:一定程度上防止代码被逆向破解
对于逆向工程师:帮助我们研究反混淆技术
OLLVM是什么
OLLVM(Obfuscator-LLVM)是瑞士西北应用科技大学安全实验室于2010年6月份发起的一个项目,这个项目的目标是提供一个LLVM编译套件的开源分支,能够通过代码混淆和防篡改,增加对逆向工程的难度,提供更高的软件安全性。目前,OLLVM已经支持LLVM-4.0.1版本。
OLLVM的混淆操作就是在中间表示IR层,通过编写Pass来混淆IR,然后后端依据IR来生成的目标代码也就被混淆了。得益于LLVM的设计,OLLVM适用LLVM支持的所有语言(C, C++, Objective-C, Ada 和 Fortran)和目标平台(x86, x86-64, PowerPC, PowerPC-64, ARM, Thumb, SPARC, Alpha, CellSPU,MIPS, MSP430, SystemZ, 和 XCore)
5、LLVM环境搭建
第一步:下载 LLVM-Core 和 Clang源代码
可以看到llvm的最新版本
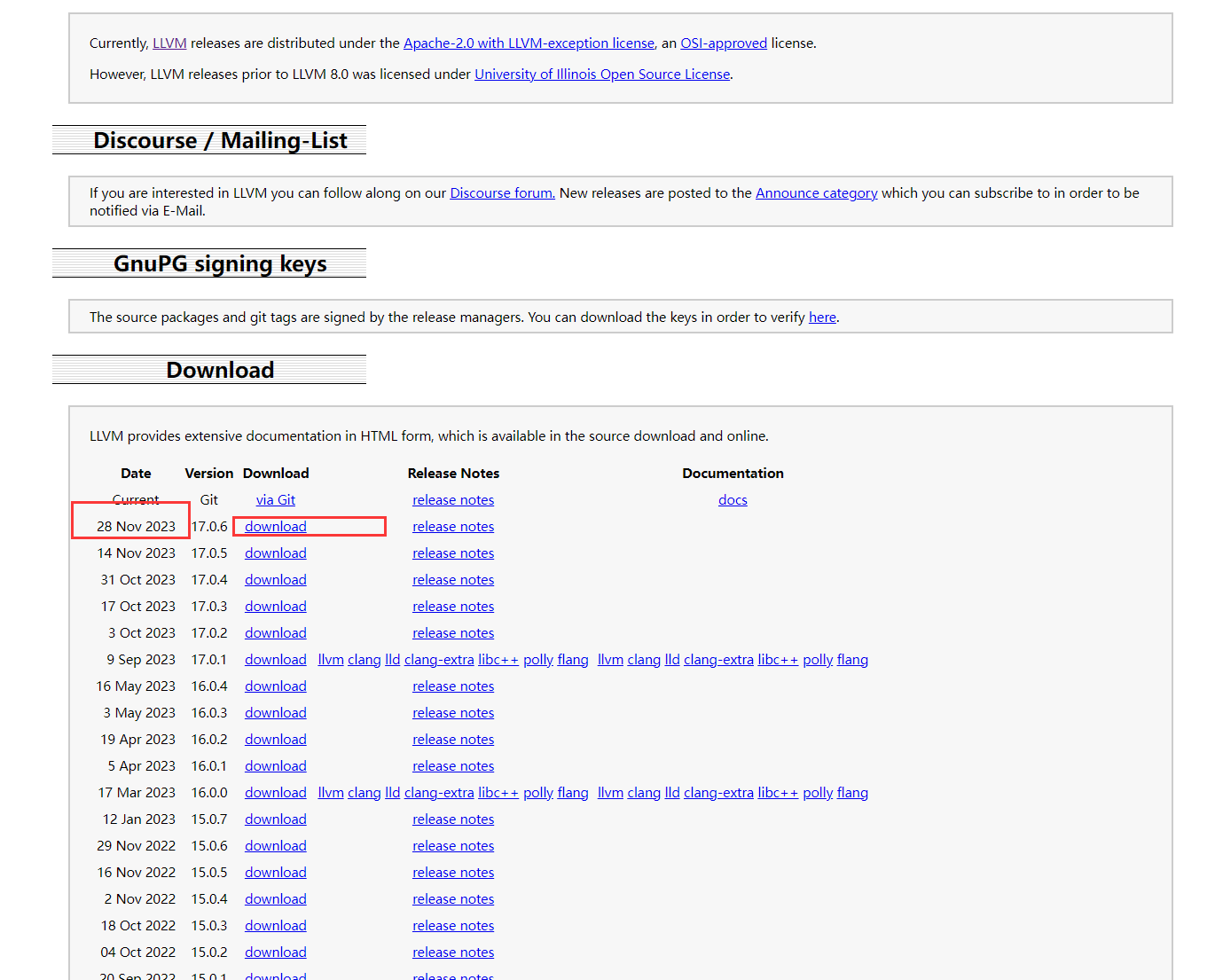
我们以9.0.1为例
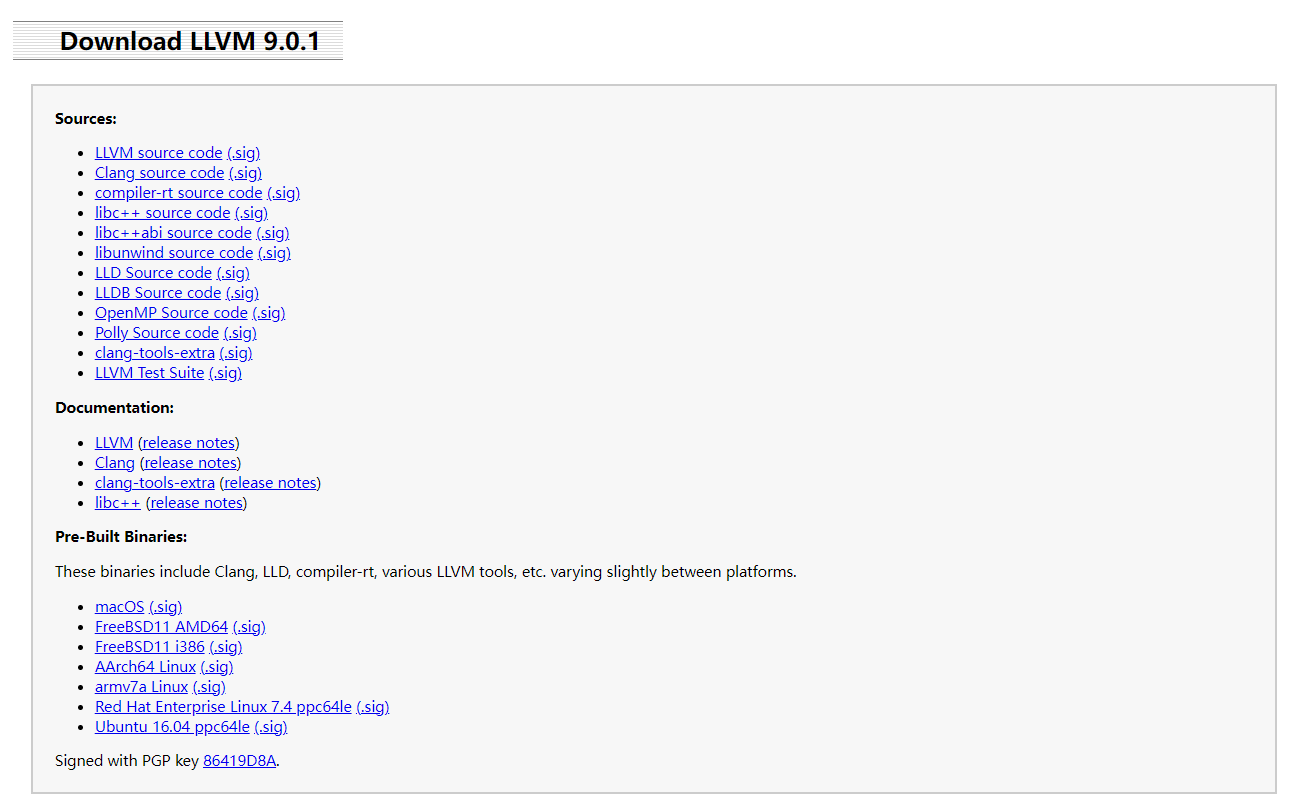
可以看到有源代码链接、文档链接以及预编译好的文件
总项目在最上面

这个地址:https://github.com/llvm/llvm-project.git
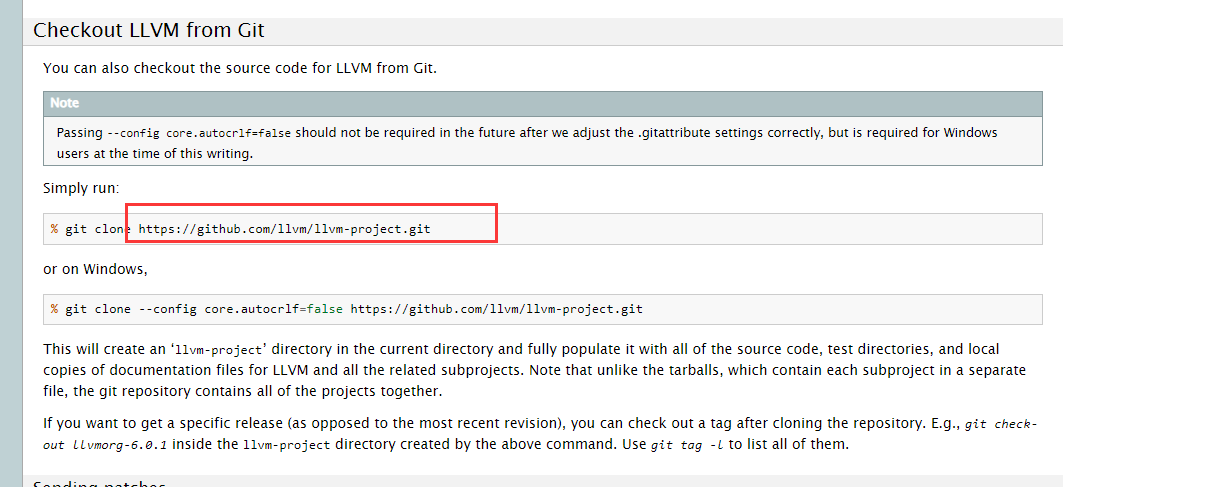
这里面就有clang和llvm的源码,右边是打包好的
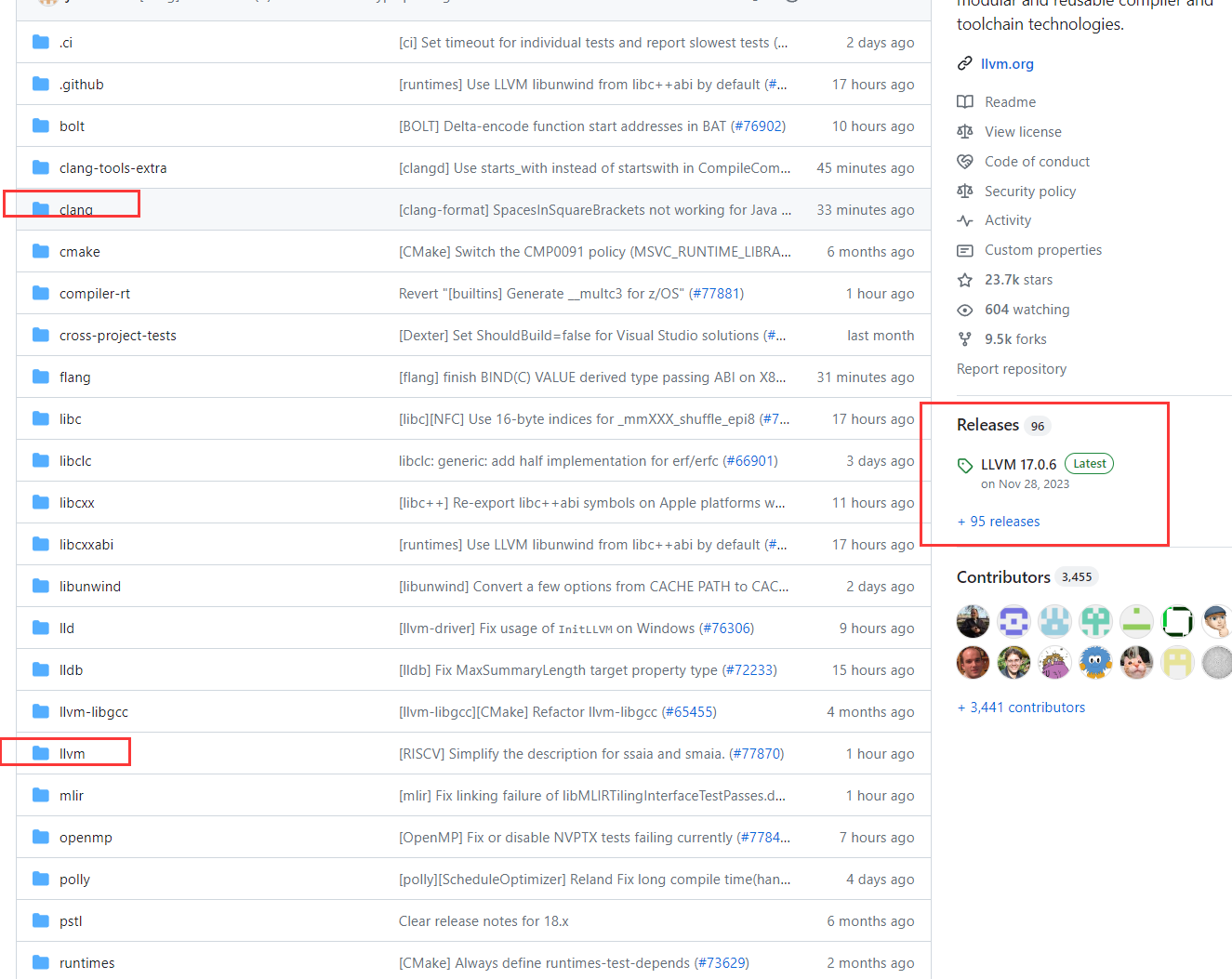
由于后续要给安卓的ndk使用,我们先看看安卓ndk里的llvm版本

ndk的路径如上图,看到clang的版本是14.0.7,所以我们下载的llvm版本也得是14.0
这里选择了14.0.6
选择源代码下载

下载完移动到Ubuntu解压
第二步:安装编译环境
不过在编译之前我们还需要提前安装一些环境
https://llvm.org/docs/GettingStarted.html
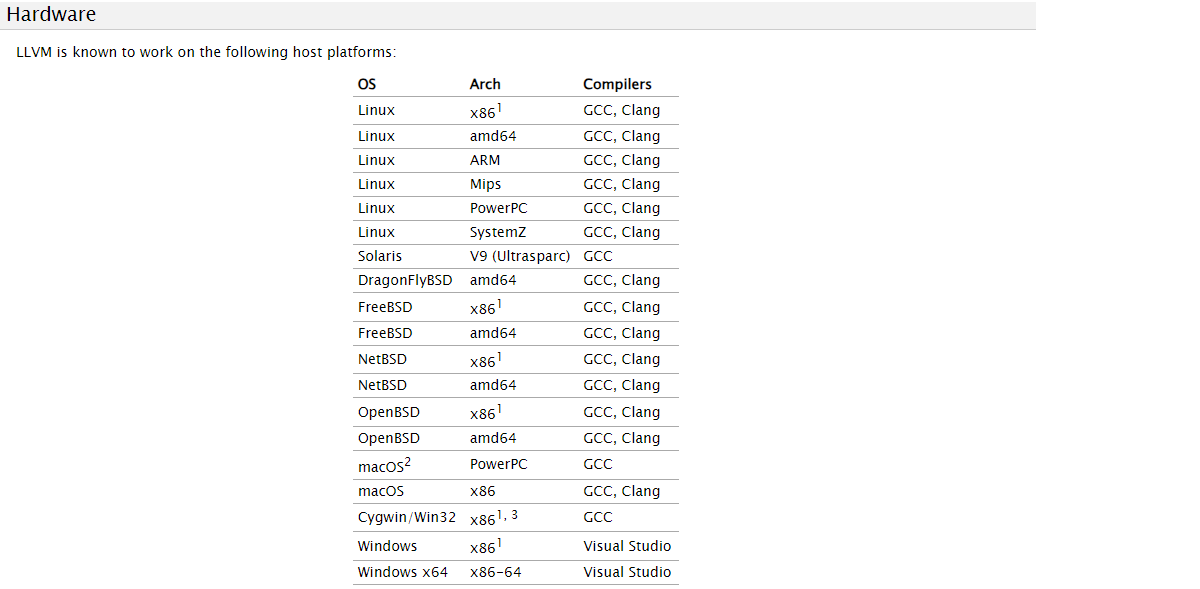
硬件需求
软件需求
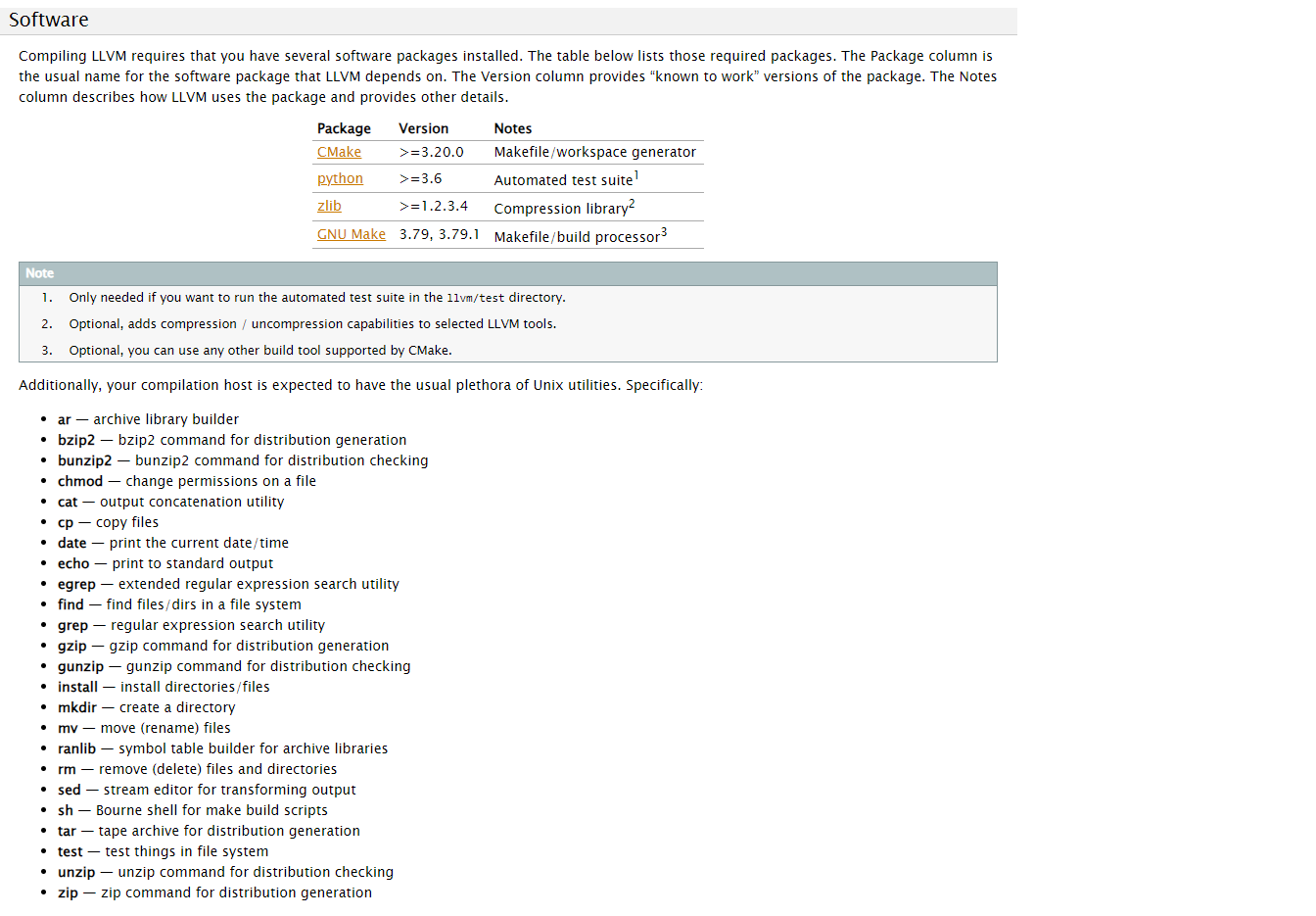
对于这些软件需求和编译aosp差不多,我们可以参考安卓的
https://source.android.com/docs/setup/build/initializing?hl=zh-cn
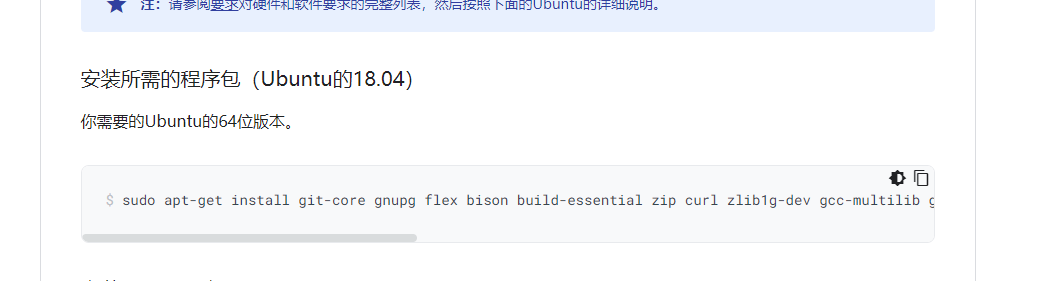
sudo apt-get install git-core gnupg flex bison build-essential zip curl zlib1g-dev gcc-multilib g++-multilib libc6-dev-i386 libncurses5 lib32ncurses5-dev x11proto-core-dev libx11-dev lib32z1-dev libgl1-mesa-dev libxml2-utils xsltproc unzip fontconfig第三步:编译
参考:https://llvm.org/docs/GettingStarted.html#below

sudo apt-get install g++
sudo apt-get install make
sudo apt-get install cmake
sudo apt install ninja-build
cd llvm-project
sudo cmake -S llvm -B build -G Ninja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_PROJECTS="clang"
cd build
ninja -j8
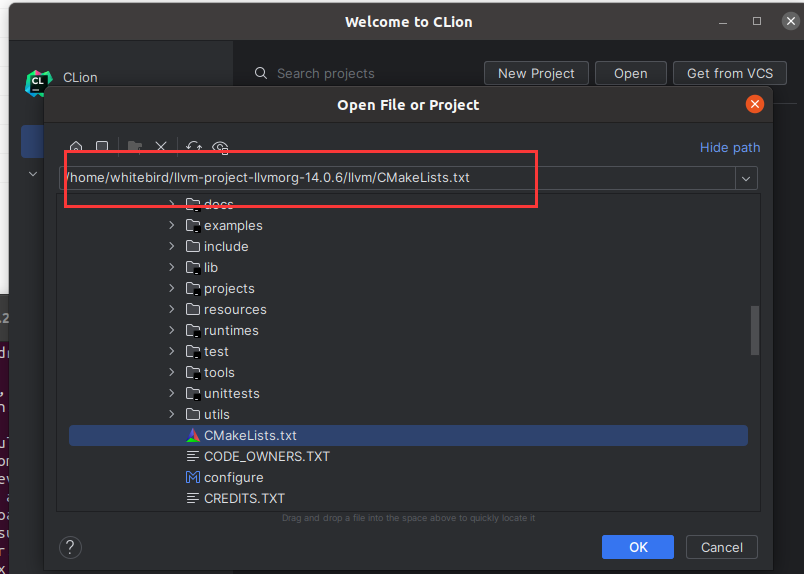
第四步:将llvm源码导入CLION进行编译
找到llvm目录下的CMakeLists.txt打开
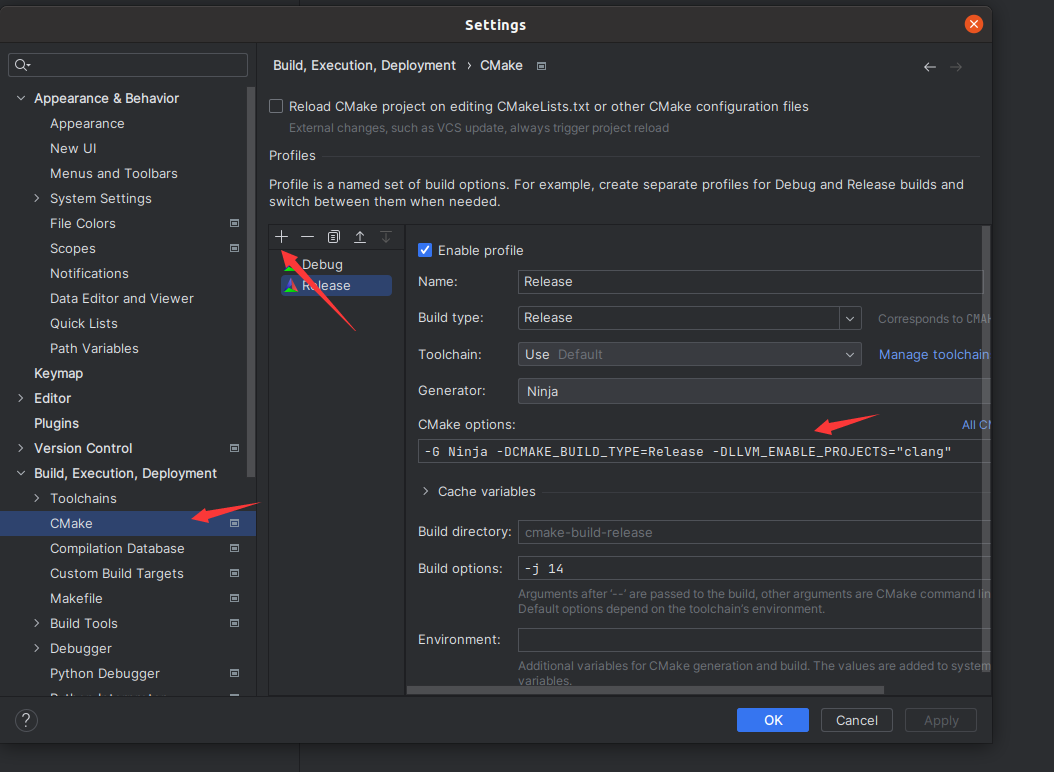
然后设置编译参数
进入settings,然后CMake里点击+会添加Release版本,我们需要在CMake options里填上我们之前编译时用的命令
多了两个目录
用clion编译会比较慢,因为clion占内存,我们可以进到目录下自己编译
在llvm目录下有新创建的cmake-build-debug和cmake-build-release
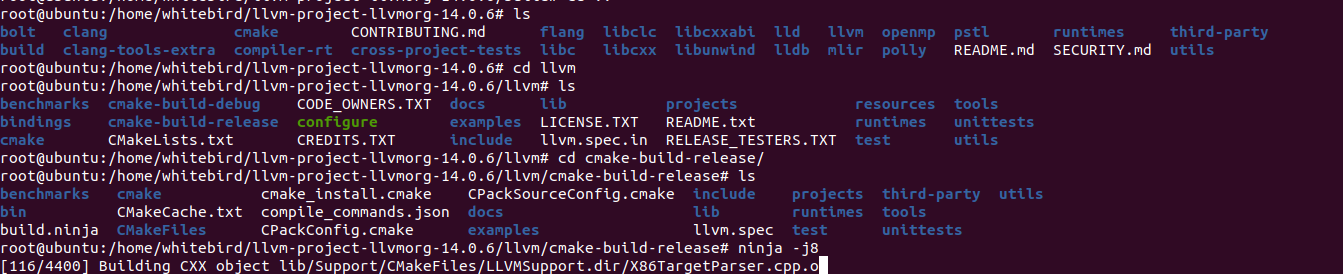
直接ninja -j线程数就行了
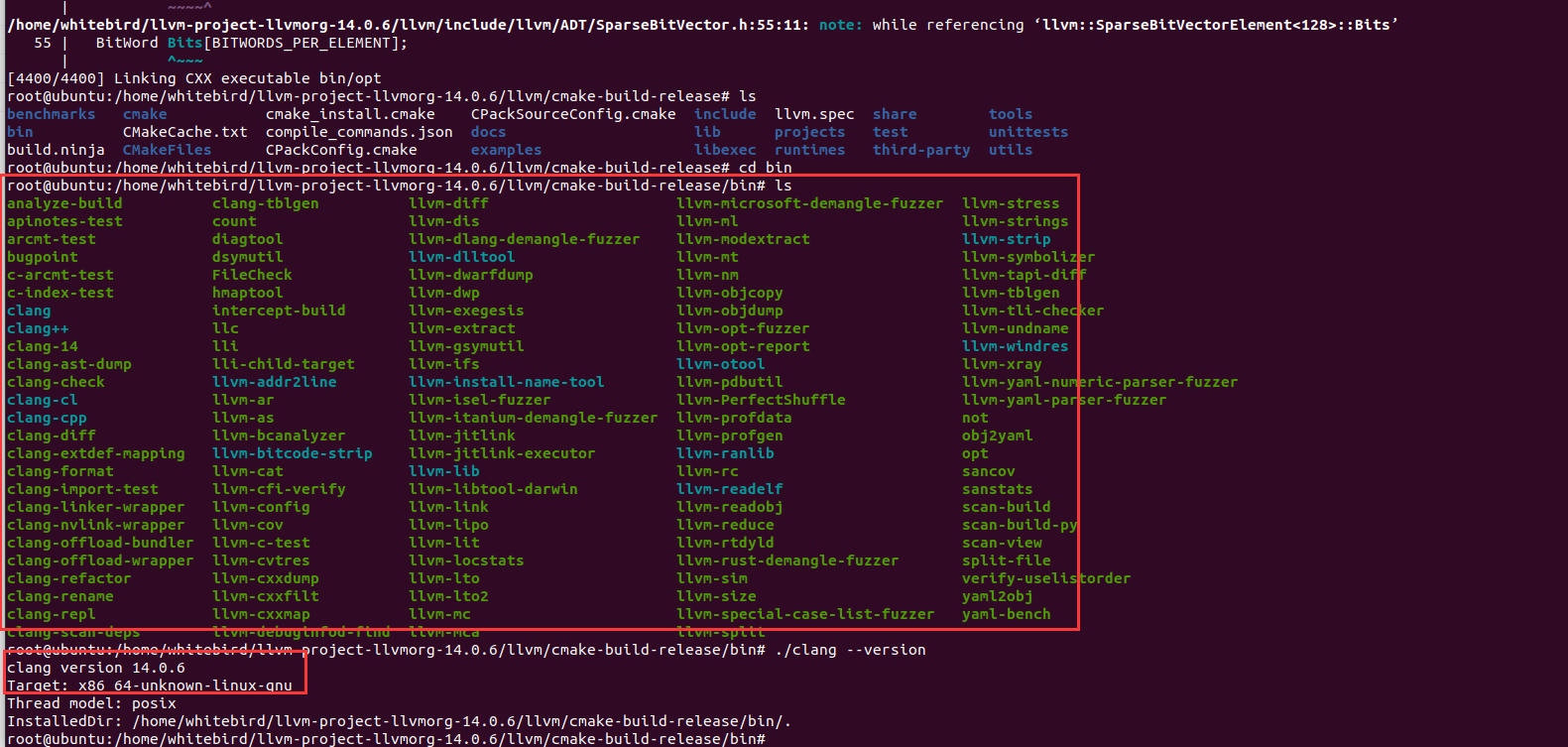
编译成功
6、利用clang进行编译c语言源码
先写了一个demo
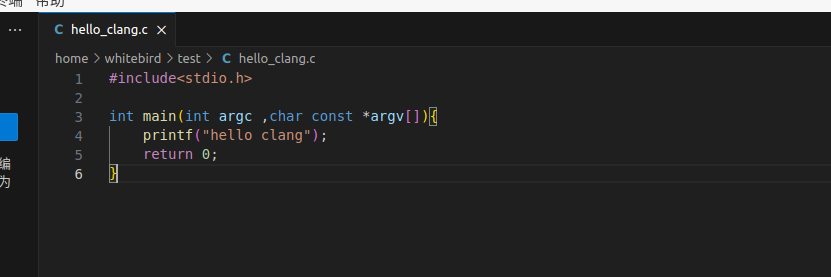
#include<stdio.h>
int main(int argc ,char const *argv[]){
printf("hello clang");
return 0;
}我们用gcc编译一下

我们用clang是没有的,需要设置环境变量

export PATH=/home/whitebird/llvm-project-llvmorg-14.0.6/llvm/cmake-build-release/bin:$PATH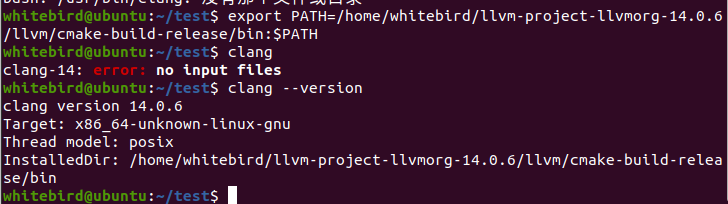
clang hello_clang.c -o hello_clang
7、用CLION调试clang
根据路径找到main位置
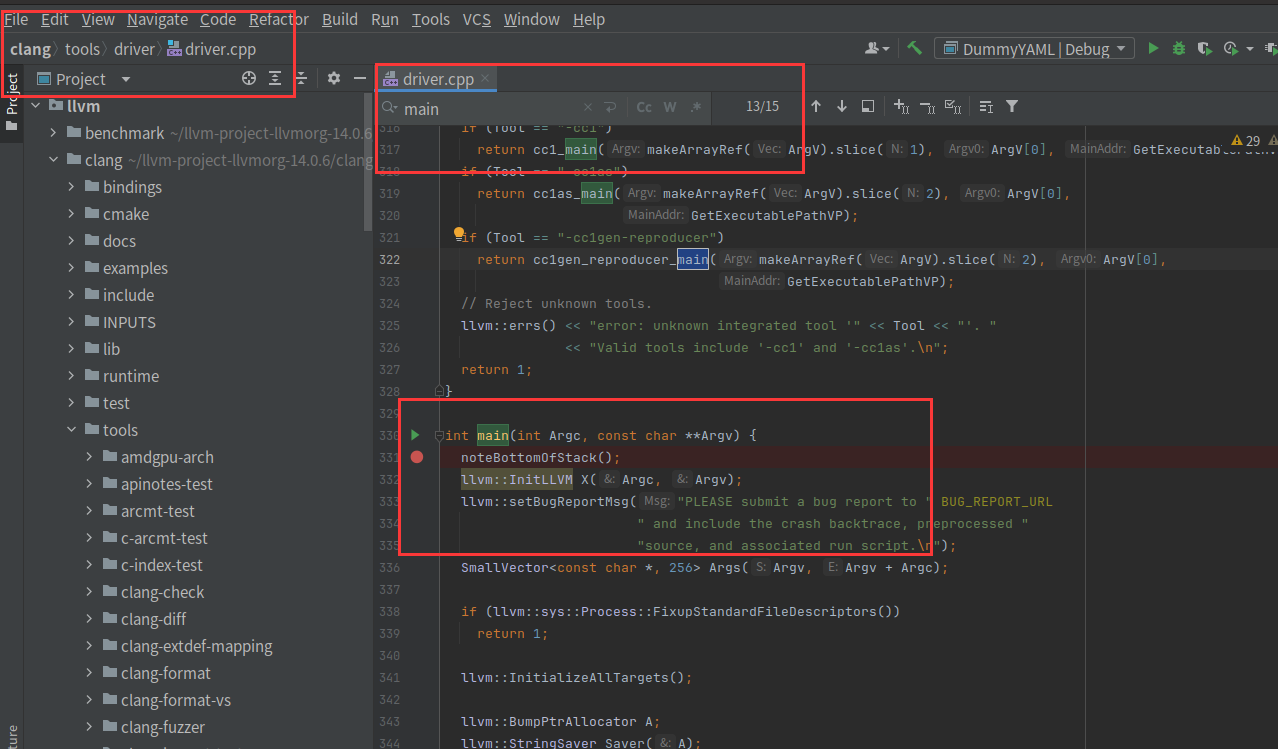
然后设置一下,比较多可以直接搜索clang
设置运行参数
/home/whitebird/test/hello_clang.c -o /home/whitebird/test/hello_clang_clion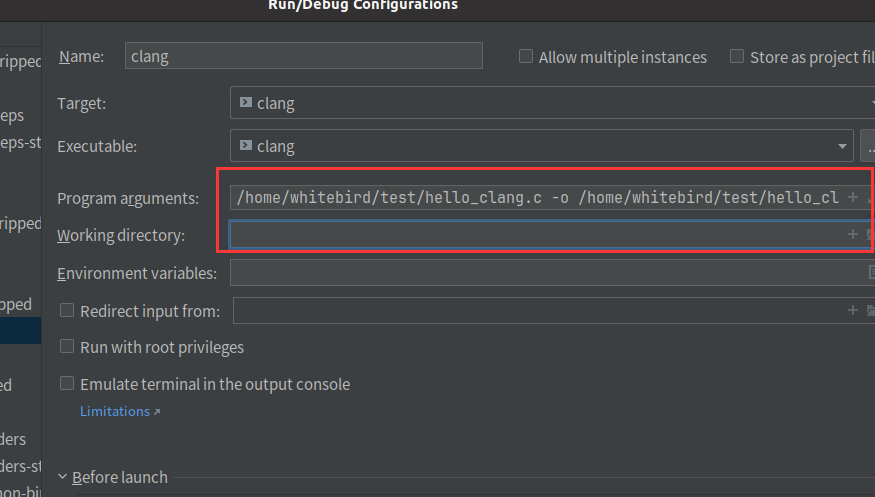
直接运行

文件夹下也有产物

8、llvm相关工具使用
https://llvm.org/docs/GettingStarted.html#llvm-tools
将C语言代码转换成LLVM IR
clang -emit-llvm -S hello_clang.c -o hello_clang.ll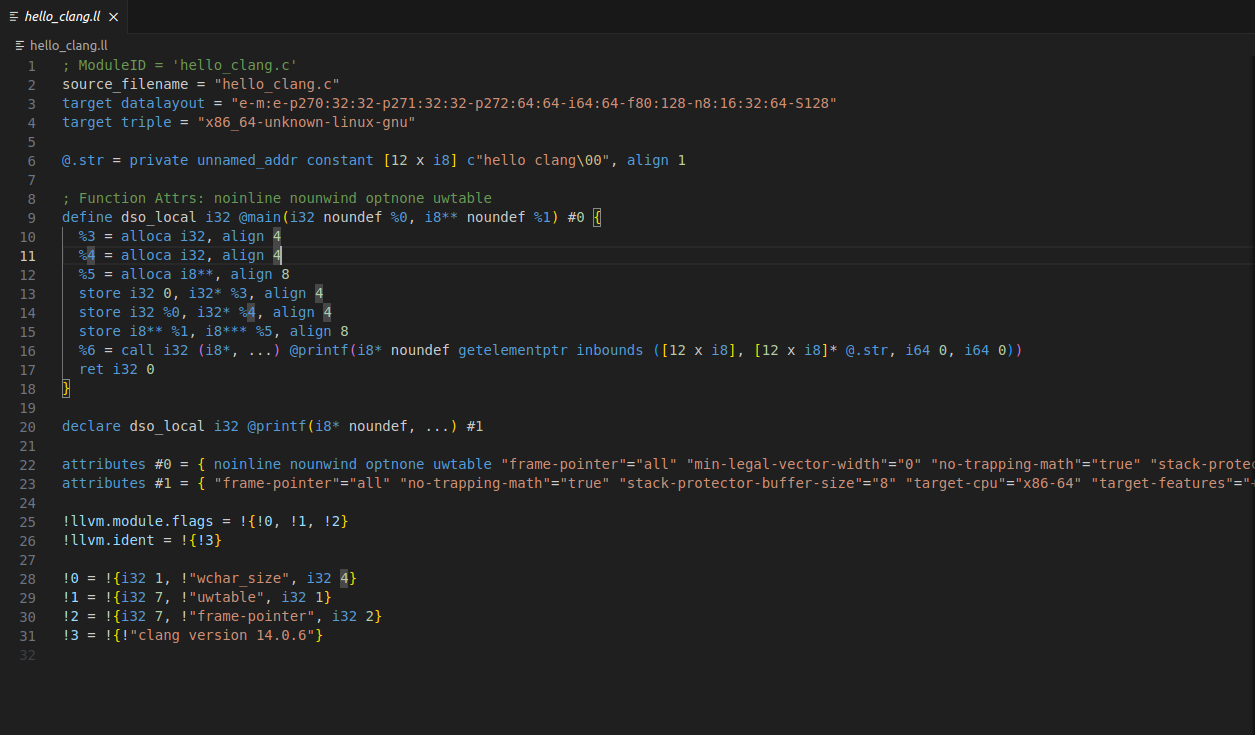
这是一种用户可读的IR中间码
执行该文件
lli hello_clang.ll
参考解释,这里还不是bitcode,所以应该充当即使编译器的效果

将LLVM IR转换成bitcode

根据解释我们选择llvm-as
llvm-as hello_clang.ll -o hello_clang.bc此时人就不能正常解析代码了
将LLVM bitcode转换成汇编

llc hello_clang.bc -o hello_clang.s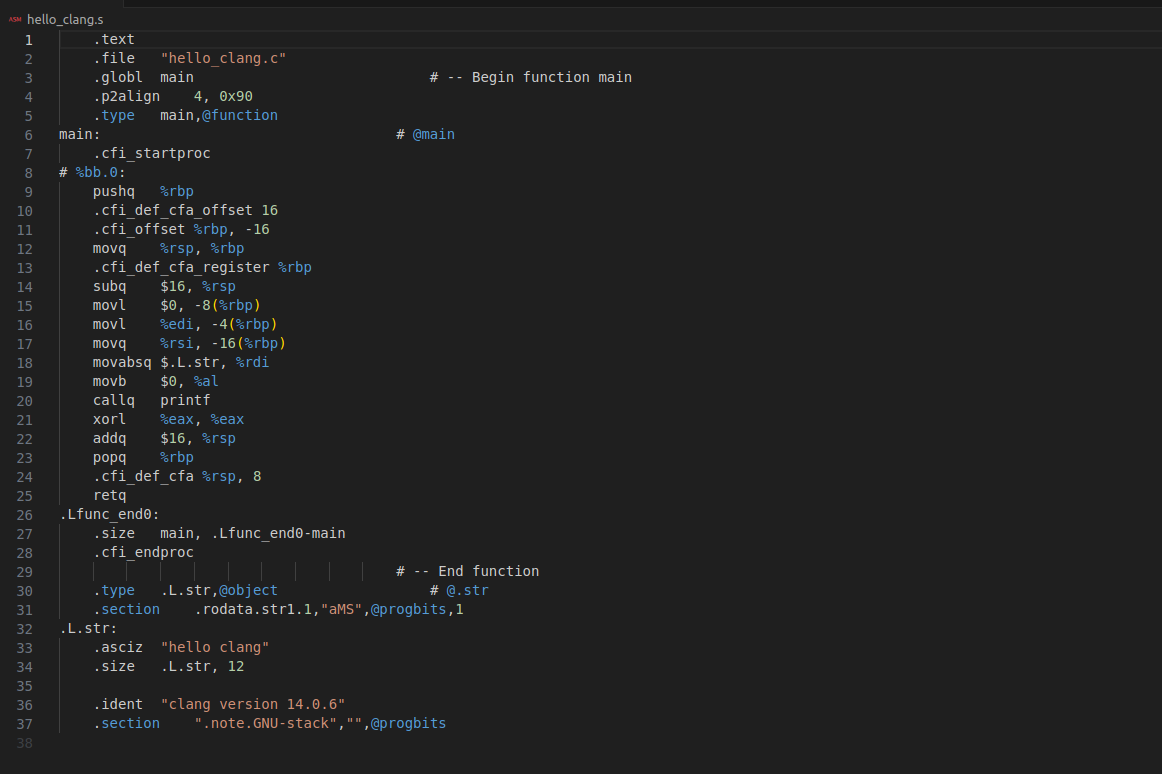
将汇编转换成可执行程序
clang hello_clang.s -o hello_clang_asm
将LLVM bitcode转换成LLVM IR

llvm-dis hello_clang.bc -o hello_clang_dis.ll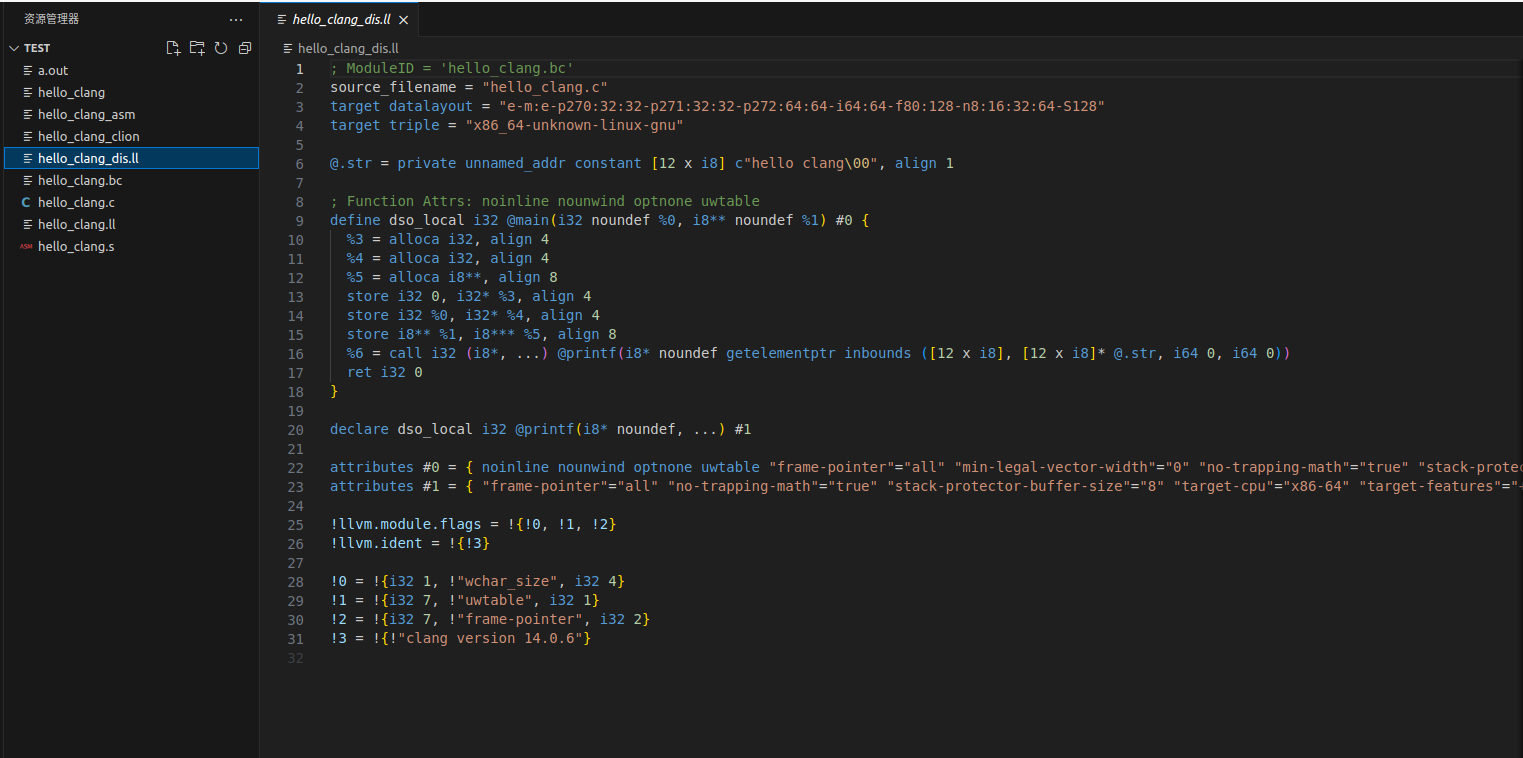
opt使用pass
opt用来读取bitcode,然后执行一些pass,pass就是优化器

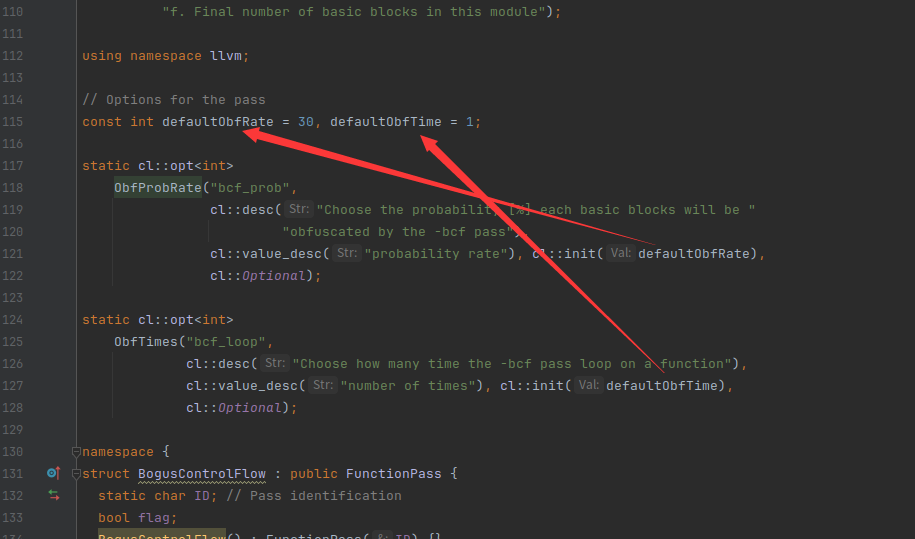
opt --help
对于正常的优化器都是对代码进行精简优化,而ollvm就是在这里把代码变复杂
opt --print-callgraph hello_clang.bc
opt --print-callgraph hello_clang.ll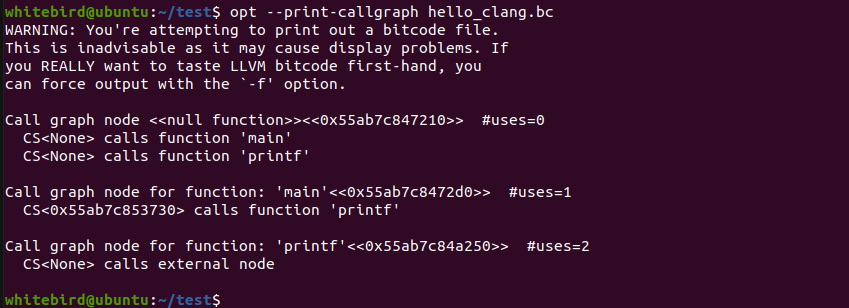
9、关于pass的相关知识
可以参考文档:https://llvm.org/docs/WritingAnLLVMPass.html#quick-start-writing-hello-world

我们查看一下PASS类
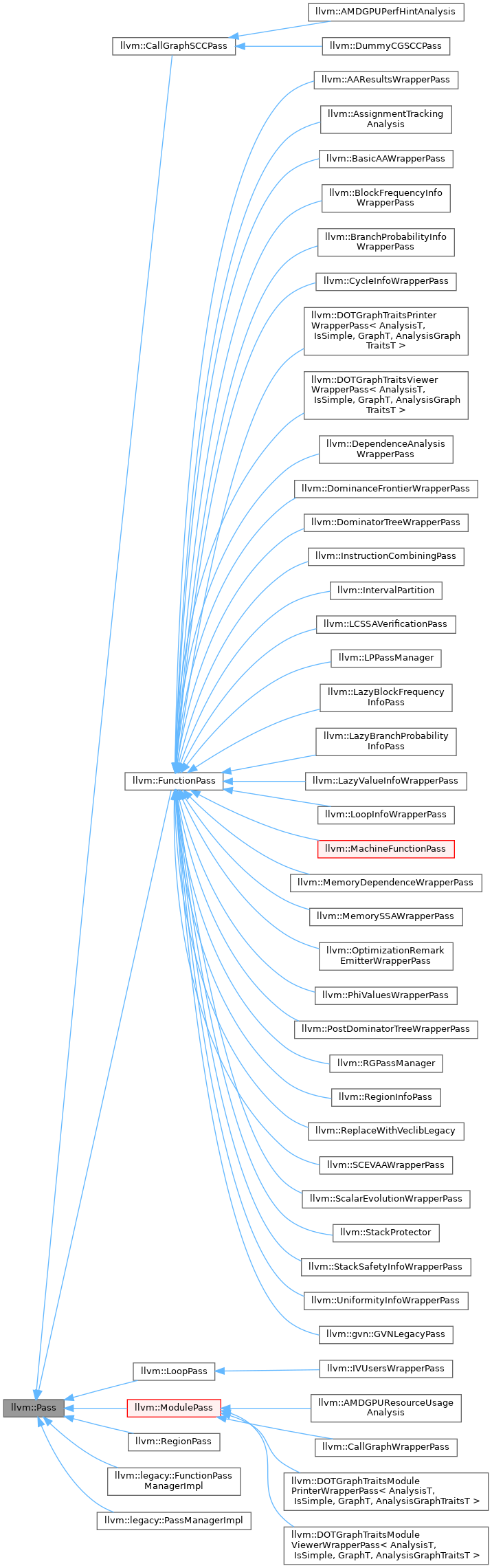
基本上用的最多的就是FunctionPass
FunctionPass
可以参考文档:https://llvm.org/docs/WritingAnLLVMPass.html#writing-an-llvm-pass-functionpass
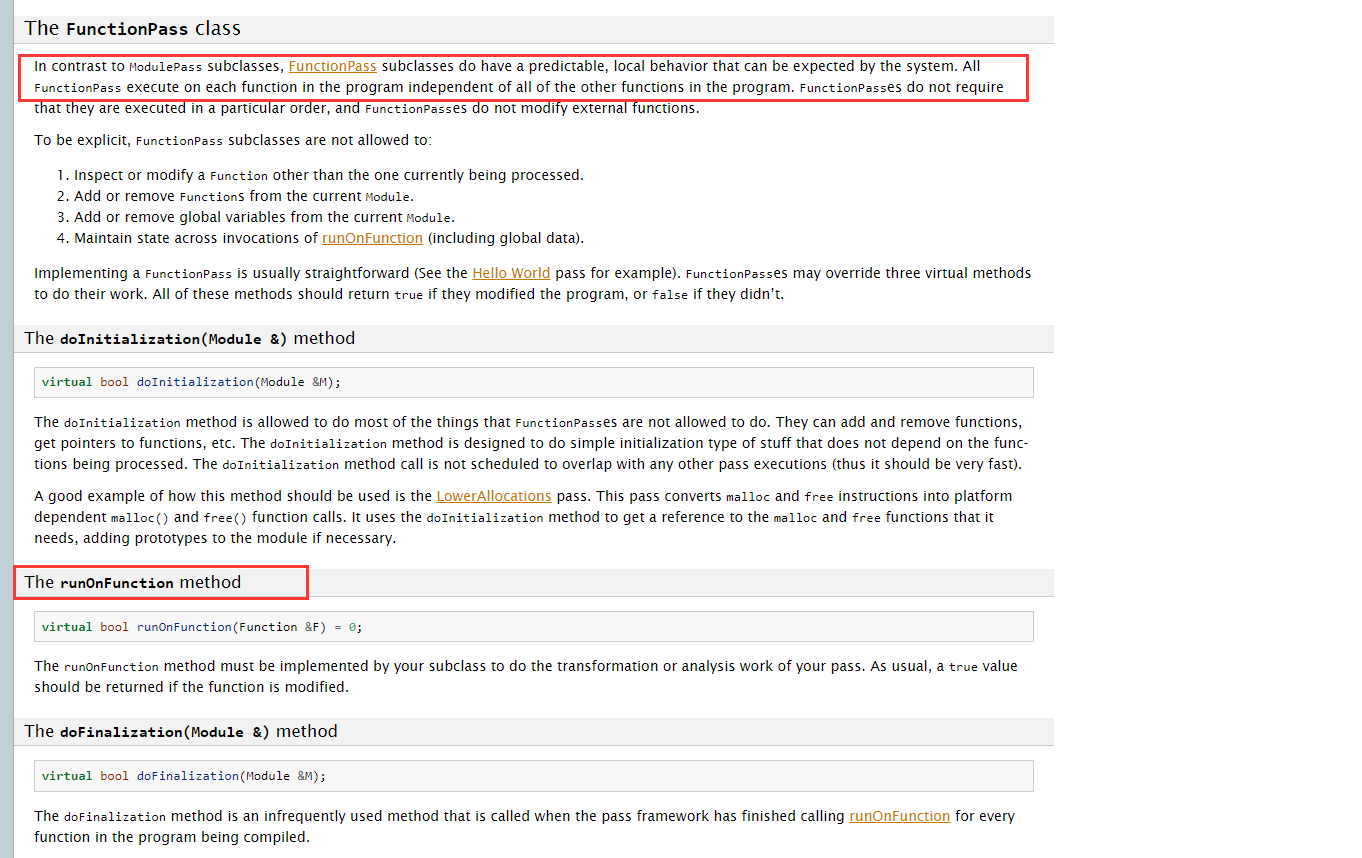
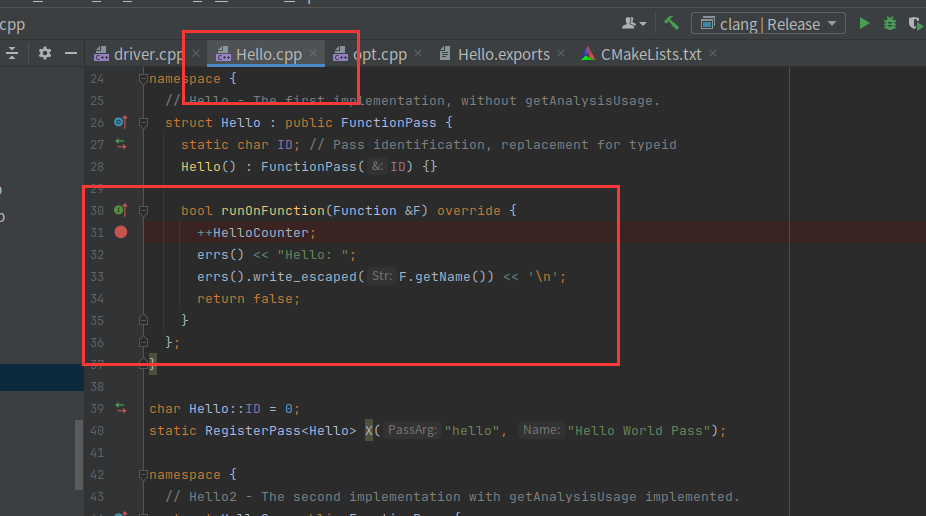
这里介绍了所有的函数都会执行FunctionPass,重点在于runOnFunction方法,所有的函数都会传入这个函数里
我们看个例子,是llvm自带的pass,路径如下
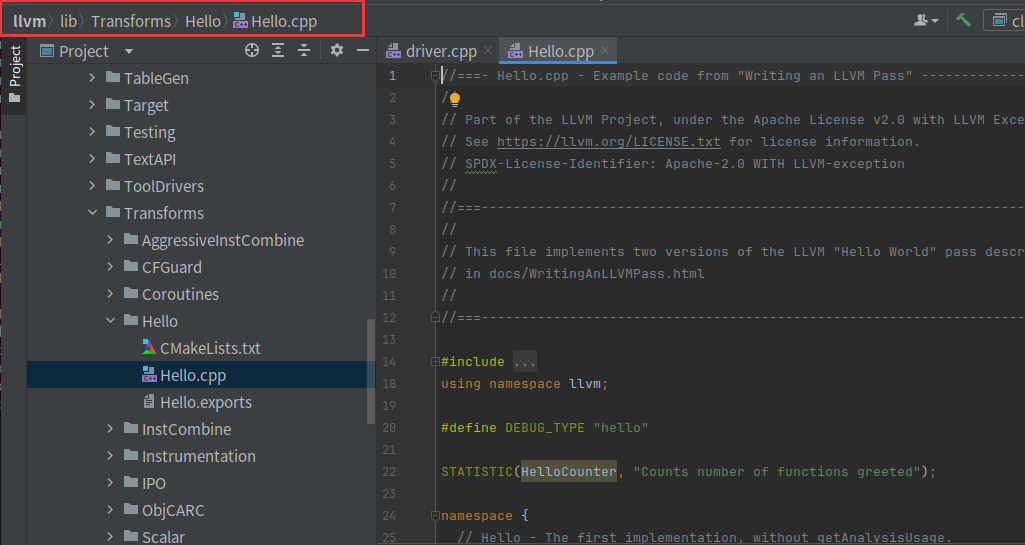
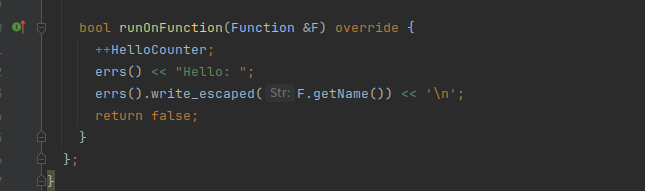
这里所做的操作就是当执行一个函数时,就输出Hello和函数名
编译好的pass存在位置如下,是一个库文件
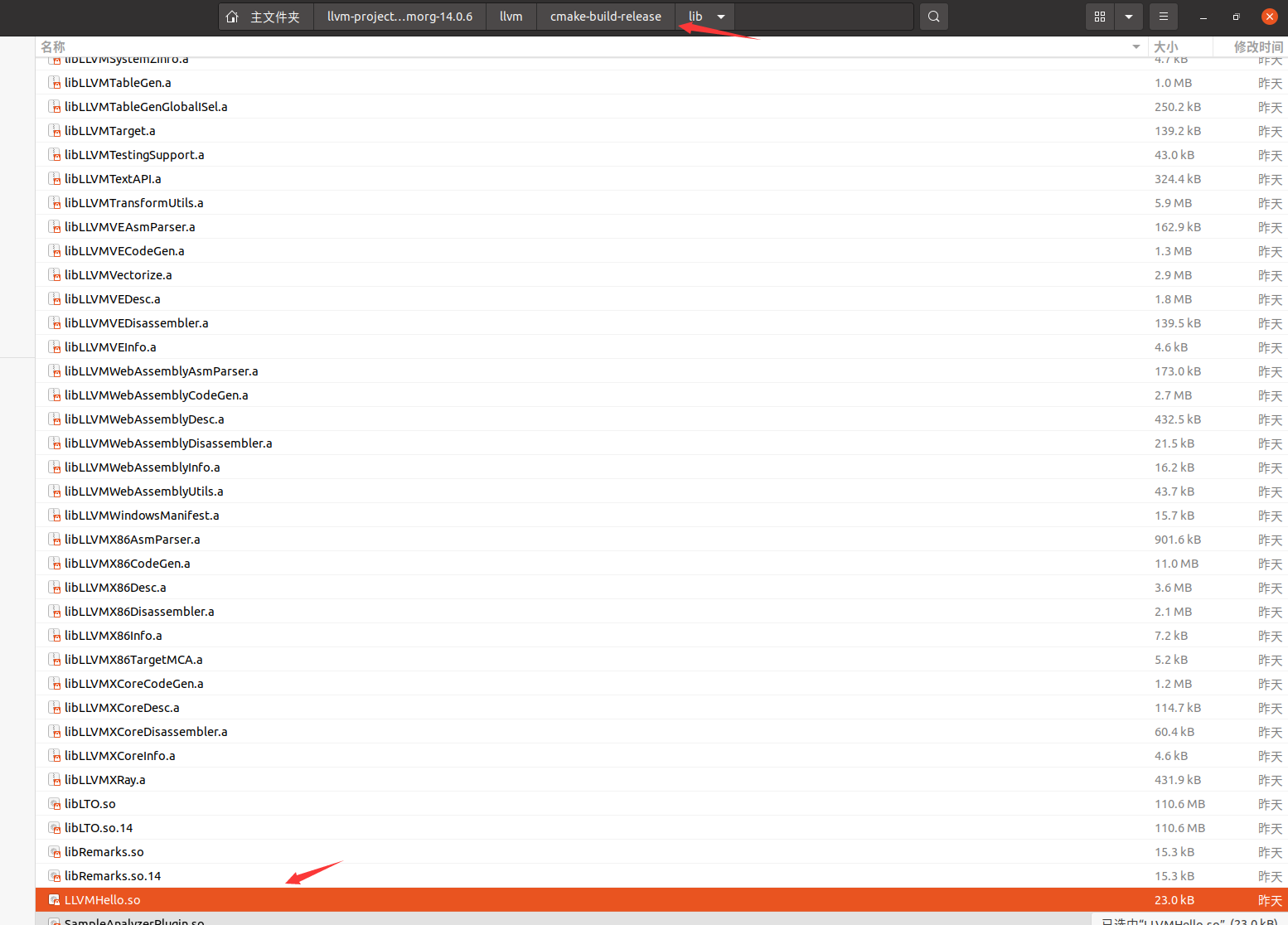
我们如何使用它呢
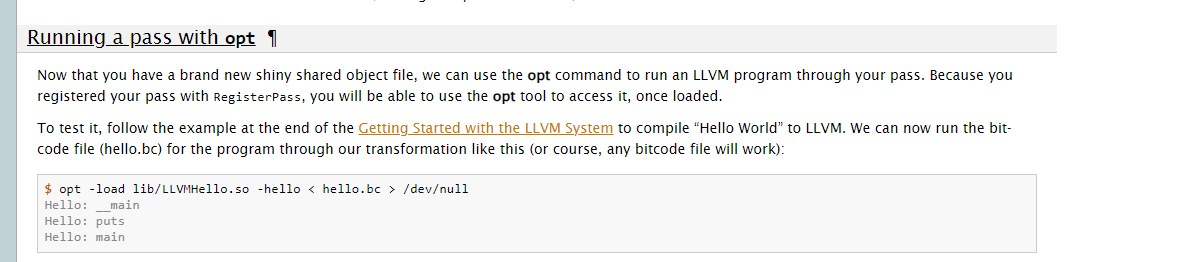
opt -load /home/whitebird/llvm-project-llvmorg-14.0.6/llvm/cmake-build-release/lib/LLVMHello.so -help |grep hello先查看一下pass是否加载成功

opt -load /home/whitebird/llvm-project-llvmorg-14.0.6/llvm/cmake-build-release/lib/LLVMHello.so --hello hello_clang.ll但是发生了报错,没有打印出来

解决方法:需要添加-enable-new-pm=0选项。如果想使用 opt 工具中旧的 Pass 管理器(the legacy pass manager),请添加 -enable-new-pm=0 选项。
opt -load /home/whitebird/llvm-project-llvmorg-14.0.6/llvm/cmake-build-release/lib/LLVMHello.so --hello -enable-new-pm=0 hello_clang.bc
多测试几个函数
#include<stdio.h>
void test_hello1(){
printf("test_hello1\n");
return ;
}
void test_hello2(){
printf("test_hello2\n");
return ;
}
int main(int argc ,char const *argv[]){
printf("hello clang\n");
return 0;
}
调换一下顺序
#include<stdio.h>
void test_hello2(){
printf("test_hello2\n");
return ;
}
int main(int argc ,char const *argv[]){
printf("hello clang\n");
return 0;
}
void test_hello1(){
printf("test_hello1\n");
return ;
}
打印顺序按照代码实现的顺序来的
10、用CLION调试opt和pass
先找到opt的源码
在main函数下个断点
然后我们给pass也下个断点
设置调试参数
-load /home/whitebird/llvm-project-llvmorg-14.0.6/llvm/cmake-build-release/lib/LLVMHello.so --hello -enable-new-pm=0 /home/whitebird/test/hello_clang.ll 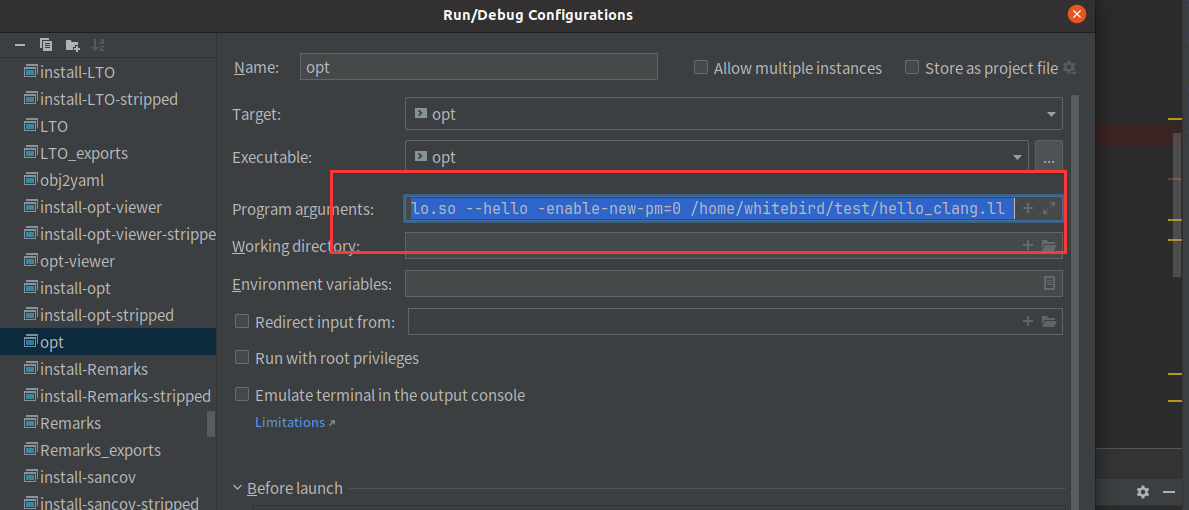
注意选择debug,release直接执行完了,点下面图标进行调试
对于debug的文件编译还是有点慢的,因为文件很大
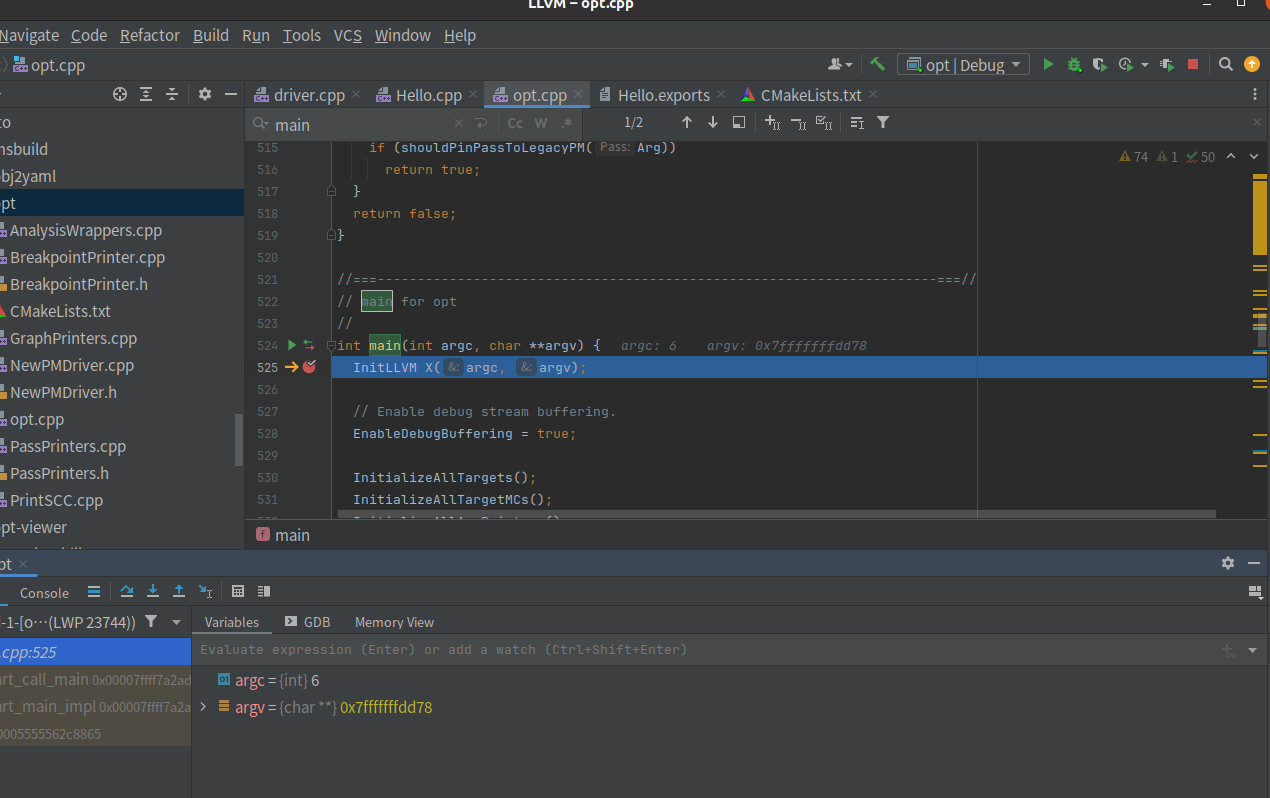
直接F9跑到pass,不过好像没断下来,目前还没有解决这个问题
11、写一个PASS-函数名加密
每个版本的写法不太一样,我们先看一下老板的
https://llvm.org/docs/WritingAnLLVMPass.html
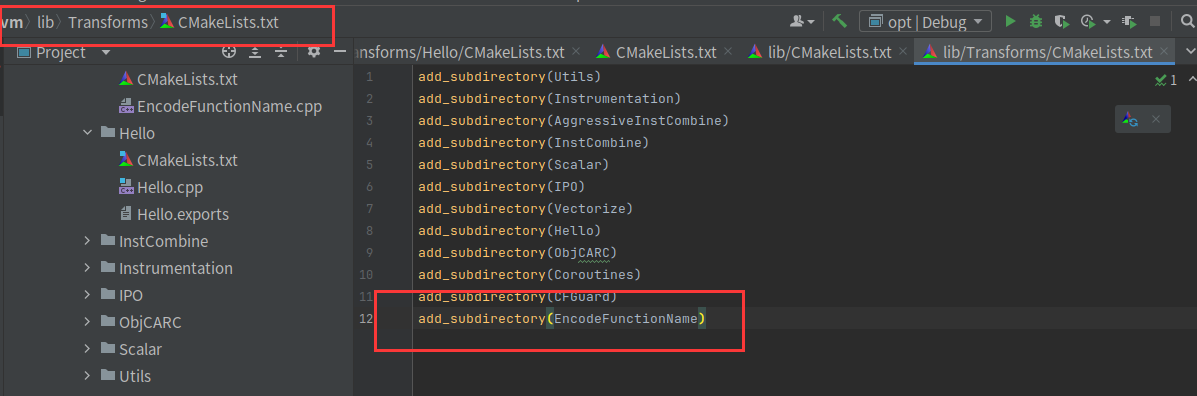
我们创建一个目录EncodeFunctionName,有EncodeFunctionName.cpp和CMakeLists.txt
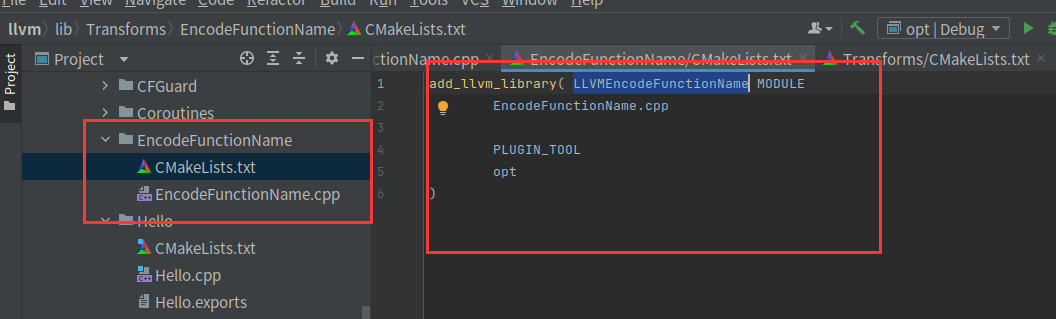
按照模板改为EncodeFunctionName.cpp和LLVMEncodeFunctionName
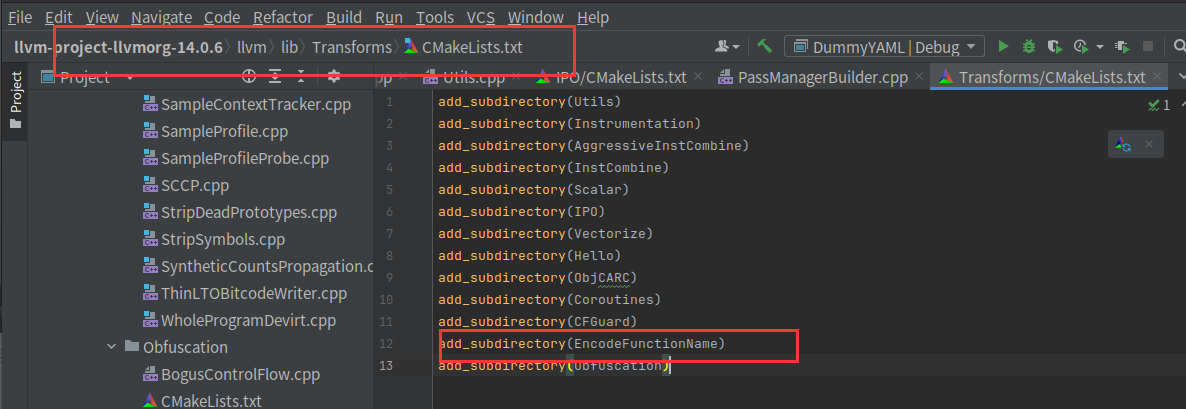
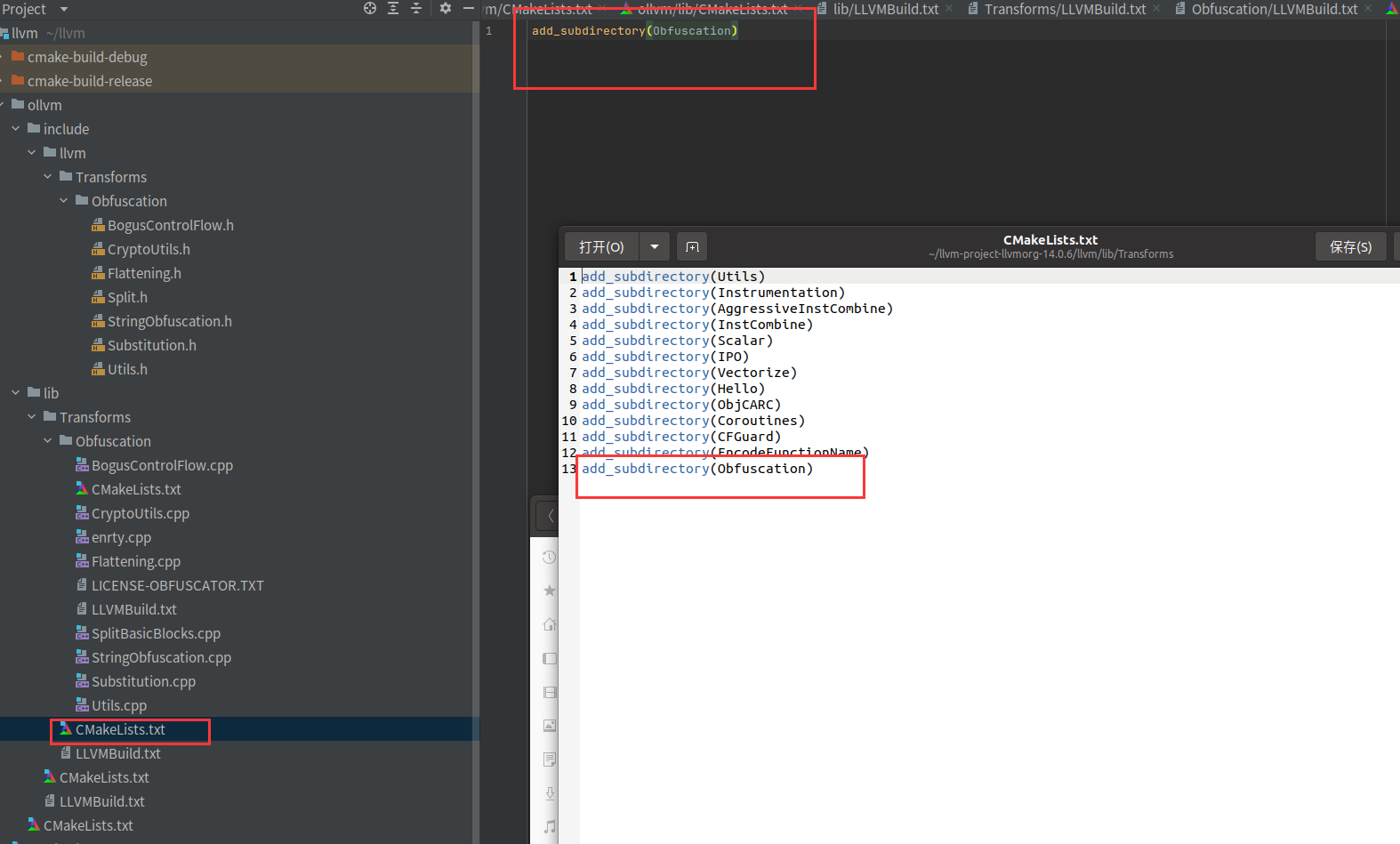
然后在lib/Transforms/CMakeLists.txt写上add_subdirectory(EncodeFunctionName)
cpp代码根据文档来
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
namespace {
struct EncodeFunctionName : public FunctionPass {
static char ID;
EncodeFunctionName() : FunctionPass(ID) {}
bool runOnFunction(Function &F) override {
errs() << "EncodeFunctionName: ";
errs().write_escaped(F.getName()) << '\n';
return false;
}
}; // end of struct Hello
} // end of anonymous namespace
char EncodeFunctionName::ID = 0;
static RegisterPass<EncodeFunctionName> X("encode", "Hello EncodeFunctionName Pass",
false /* Only looks at CFG */,
false /* Analysis Pass */);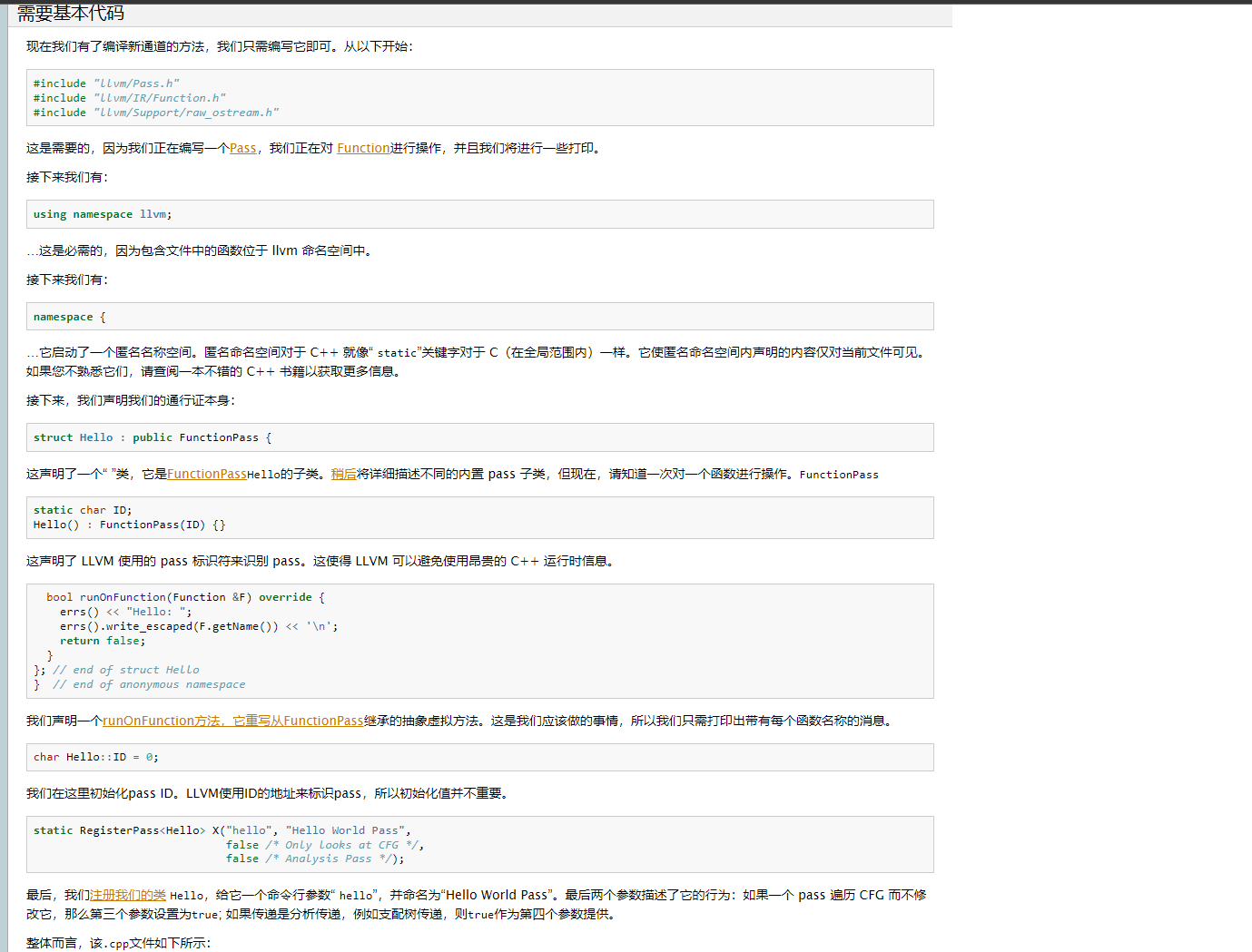
现在我们需要去编译一下这个pass,首先加载一下cmakelist
或者勾选上
进行ninja LLVMEncodeFunctionName

我们用一下这个pass
opt -load /home/whitebird/llvm-project-llvmorg-14.0.6/llvm/cmake-build-release/lib/LLVMEncodeFunctionName.so --encode -enable-new-pm=0 hello_clang.ll -o hello_clang.bc
我们现在稍微修改一下代码
bool runOnFunction(Function &F) override {
errs() << "EncodeFunctionName before: "<<F.getName()<<'\n';
if (F.getName().compare("test_hello2")==0){
F.setName("whitebird_function");
}
errs() << "EncodeFunctionName after: "<<F.getName()<<'\n';
return false;
}主要是对test_hello2进行比较,如果是的就利用setName把函数名改为whitebird_function
我们重新编译,再运行一次pass
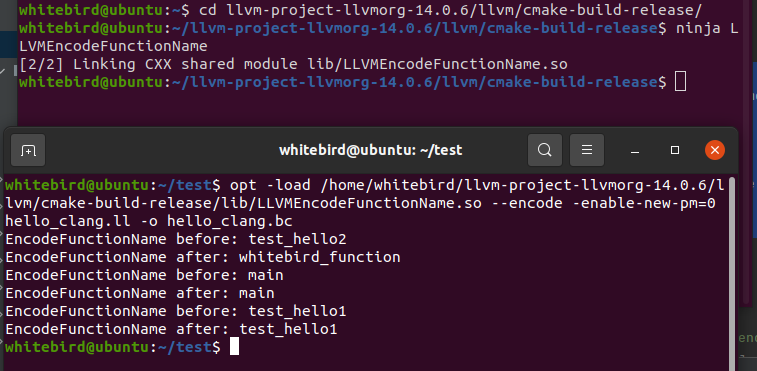
我们用clang编译一次可执行文件,去ida再看看
clang hello_clang.bc -o hello_clangbc文件是我们刚才优化完的产物,此时的函数名已经变了
我们再写一个复杂一点的,用一下llvm自带的MD5加密
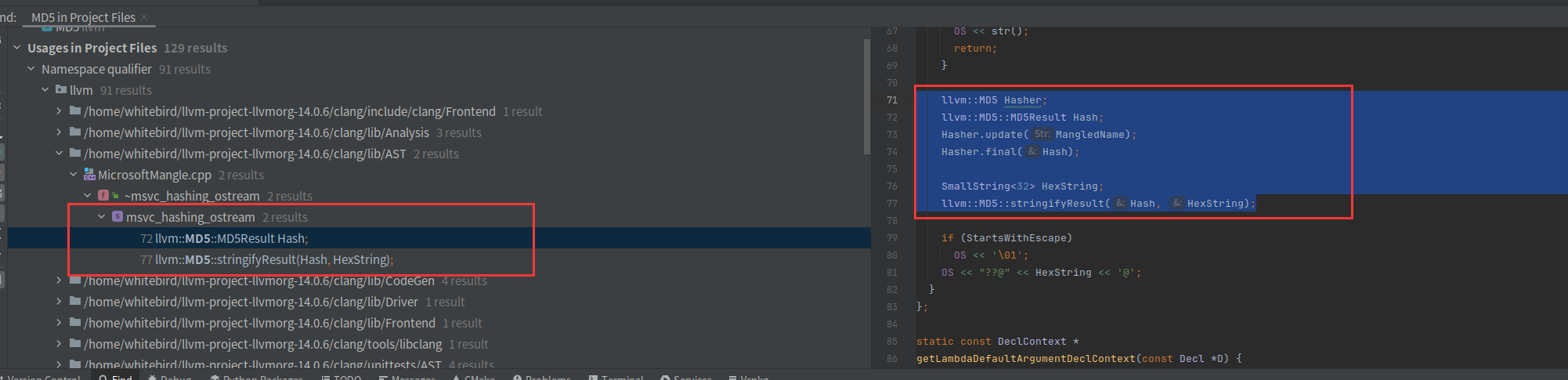
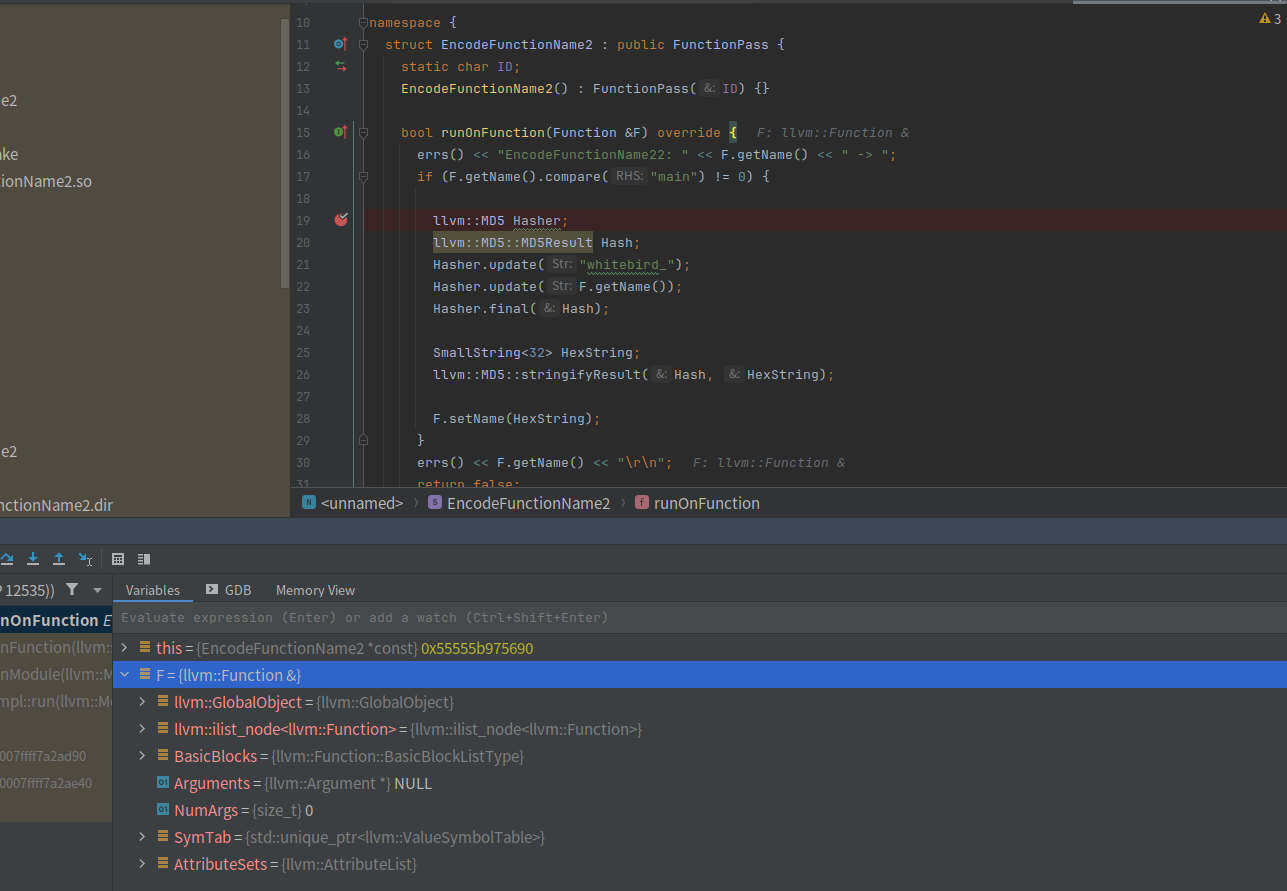
bool runOnFunction(Function &F) override {
if (F.getName().compare("main")!=0){
errs() << "EncodeFunctionName before: "<<F.getName()<<'\n';
llvm::MD5 Hasher;
llvm::MD5::MD5Result Hash;
Hasher.update("whitebird_");
Hasher.update(F.getName());
Hasher.final(Hash);
SmallString<32> HexString;
llvm::MD5::stringifyResult(Hash, HexString);
F.setName(HexString);
errs() << "EncodeFunctionName after: "<<HexString<<'\n';
}
return false;
}把函数名改为whitebird_xxx,然后进行md5
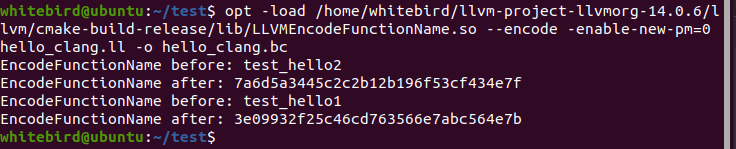
再编译一次可执行文件,去IDA看看
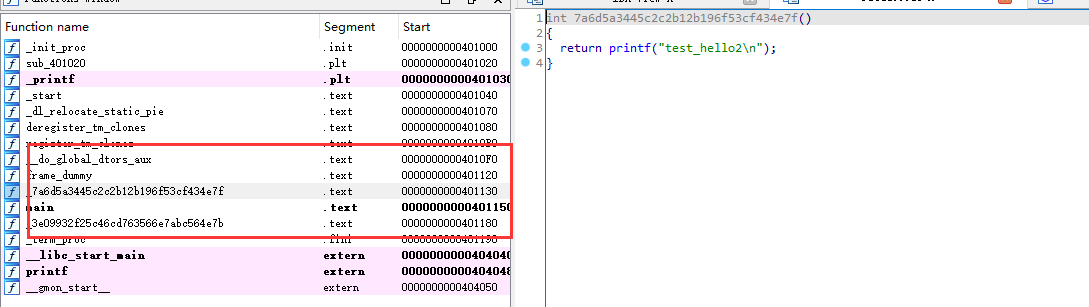
12、在LLVM源码外开发PASS
前面的pass是在llvm源码里写的,有时候可能比较麻烦,有一种方法可以脱离LLVM源码
参考:https://releases.llvm.org/8.0.1/docs/CMake.html#developing-llvm-passes-out-of-source
因为llvm14已经是新的写法了,所以我们采用老版本的文档来写
不过有一些报错需要处理
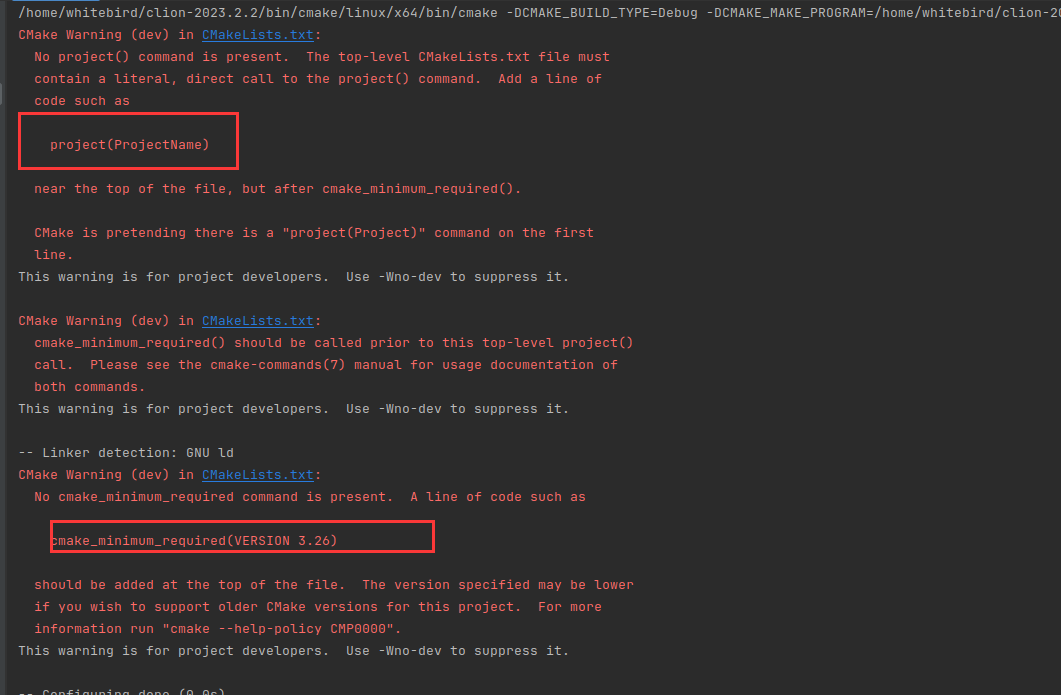
效果如下
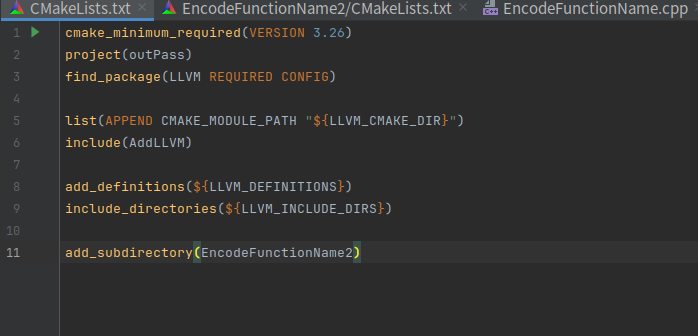
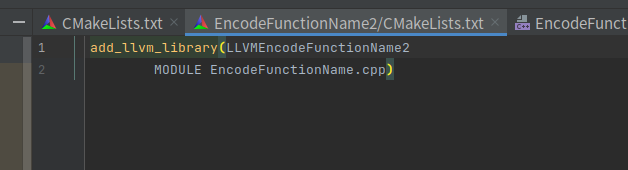
子目录的CMakeLists.txt
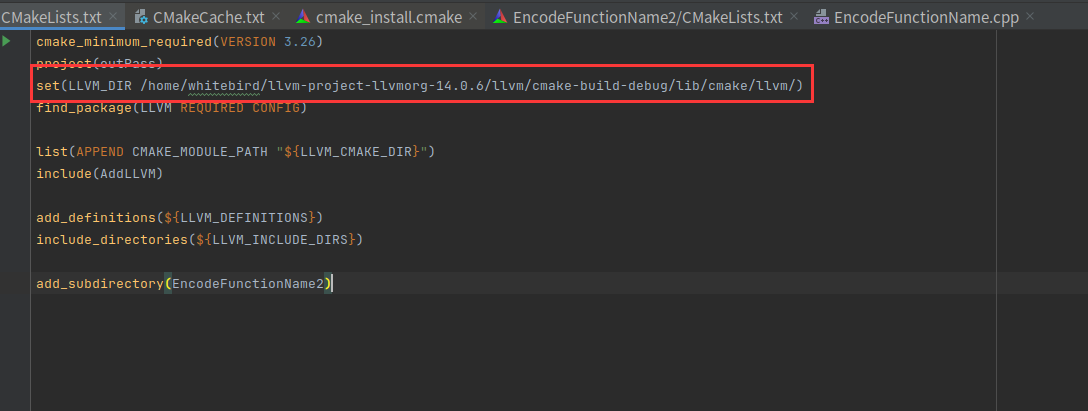
此时还有点问题,需要设置LLVM_DIR,告诉CMake去寻找LLVMConfig.cmake配置文件。这个配置文件包含了LLVM库、头文件等必要的信息。
编译测试
opt -load /home/whitebird/outPass/cmake-build-release/EncodeFunctionName2/LLVMEncodeFunctionName2.so --encode -enable-new-pm=0 hello_clang.ll -o hello_clang.bc
13、通过clang加载pass
首先得注册一下
参考https://releases.llvm.org/9.0.1/docs/WritingAnLLVMPass.html
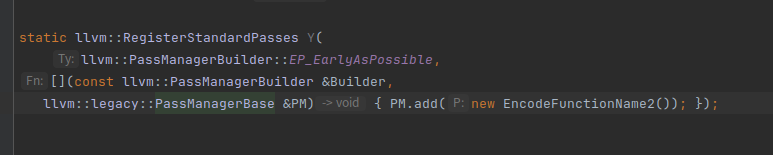
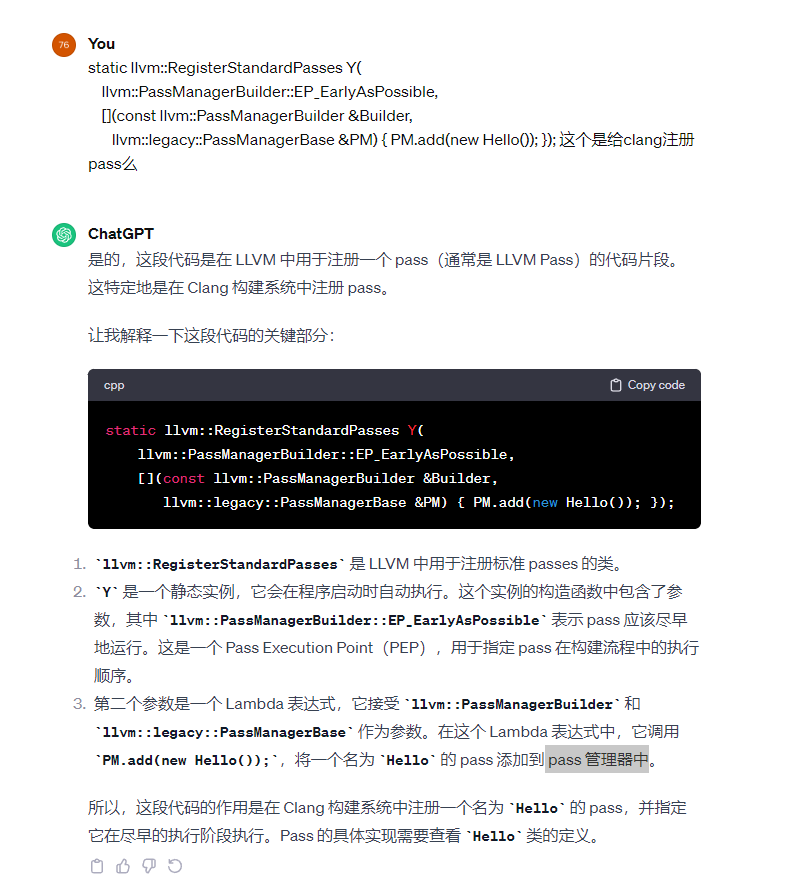
clang -Xclang -load -Xclang /home/whitebird/outPass/cmake-build-release/EncodeFunctionName2/LLVMEncodeFunctionName2.so -flegacy-pass-manager hello_clang.ll -o hello_clang.bc
clang -Xclang -load -Xclang /home/whitebird/outPass/cmake-build-release/EncodeFunctionName2/LLVMEncodeFunctionName2.so -flegacy-pass-manager hello_clang.ll -o hello_clang_t也可以编译成可执行文件
还有种注册的方法,直接加入clang的命令行
//
// Created by whitebird on 24-1-15.
//
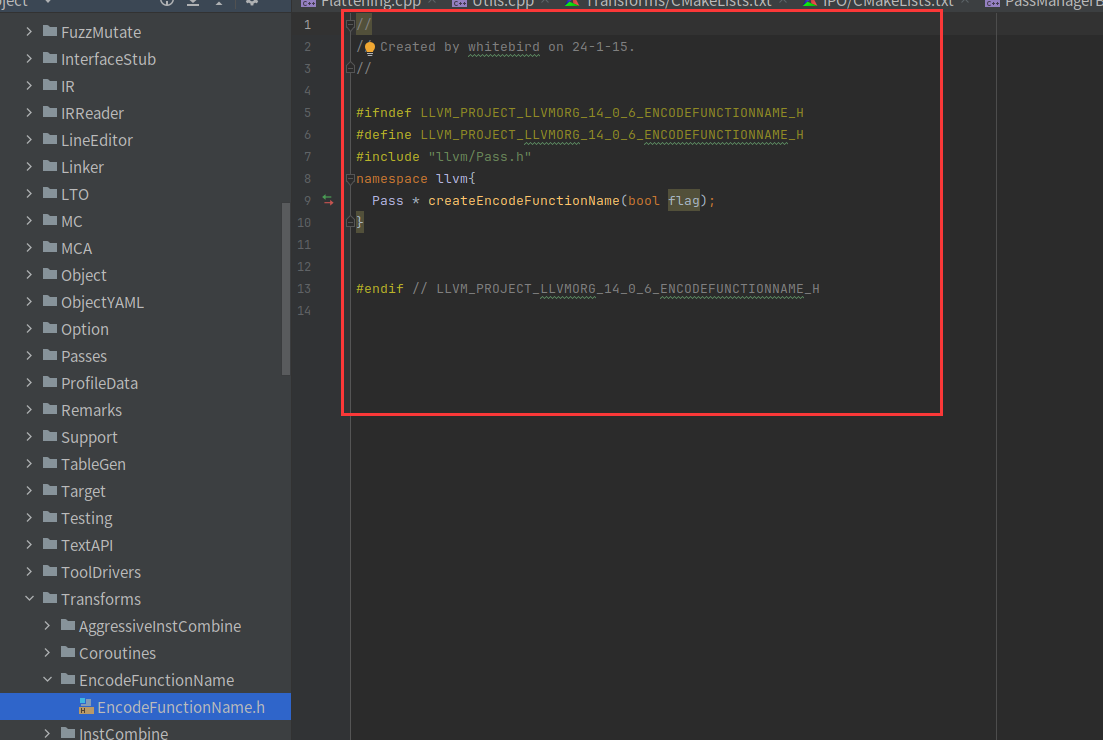
#ifndef LLVM_PROJECT_LLVMORG_14_0_6_ENCODEFUNCTIONNAME_H
#define LLVM_PROJECT_LLVMORG_14_0_6_ENCODEFUNCTIONNAME_H
#include "llvm/Pass.h"
namespace llvm{
Pass * createEncodeFunctionName(bool flag);
}
#endif // LLVM_PROJECT_LLVMORG_14_0_6_ENCODEFUNCTIONNAME_H
先搞个头文件,然后在EncodeFunctionName.cpp中实现,其实主要是对全局变量enable_flag赋值,然后通过enable_flag来执行我们函数名加密逻辑,而enable_flag其实是判断我们输入了命令行,如果输入了就是true,没输入就是false,对应着不执行
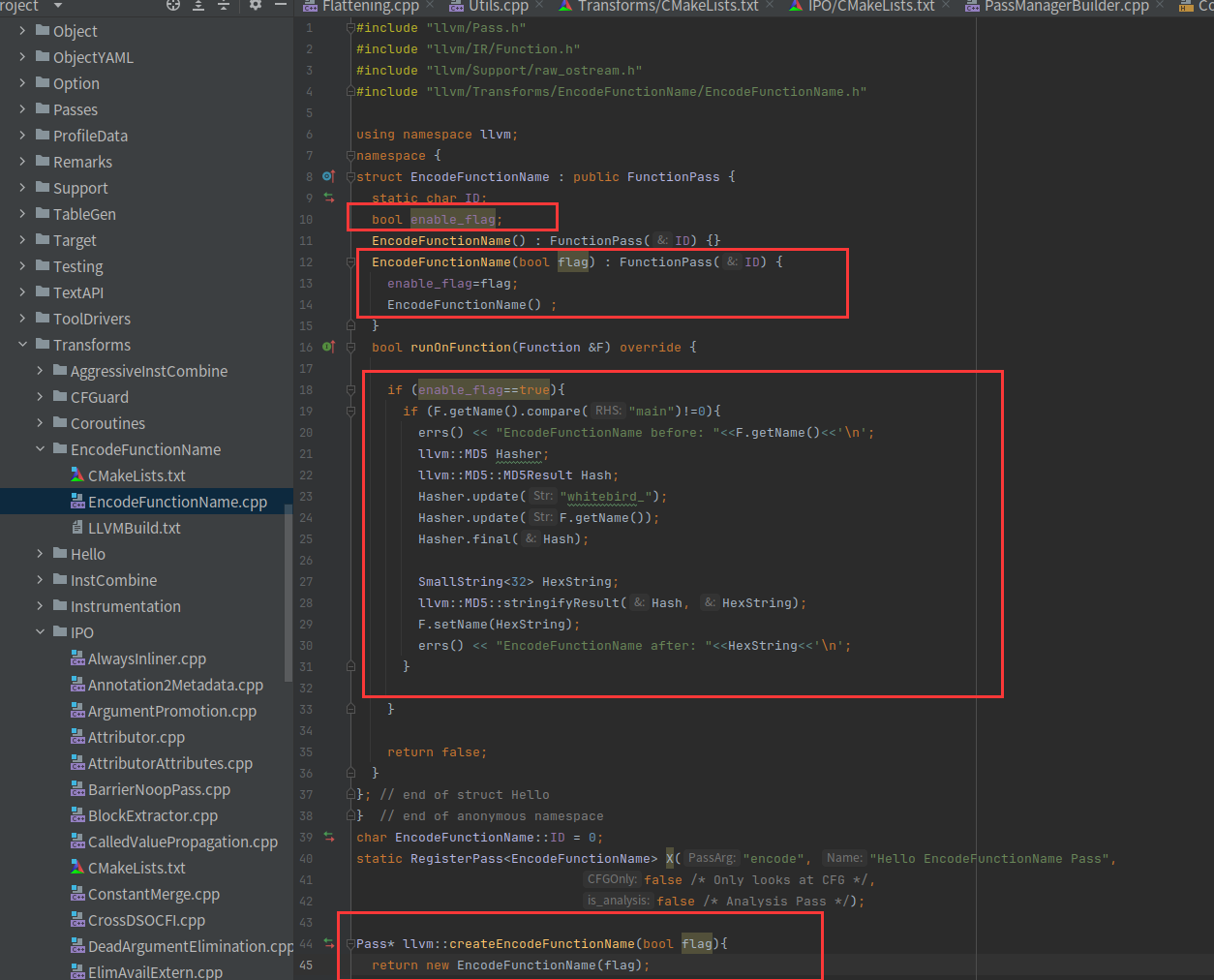
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Transforms/EncodeFunctionName/EncodeFunctionName.h"
using namespace llvm;
namespace {
struct EncodeFunctionName : public FunctionPass {
static char ID;
bool enable_flag;
EncodeFunctionName() : FunctionPass(ID) {}
EncodeFunctionName(bool flag) : FunctionPass(ID) {
enable_flag=flag;
EncodeFunctionName() ;
}
bool runOnFunction(Function &F) override {
if (enable_flag==true){
if (F.getName().compare("main")!=0){
errs() << "EncodeFunctionName before: "<<F.getName()<<'\n';
llvm::MD5 Hasher;
llvm::MD5::MD5Result Hash;
Hasher.update("whitebird_");
Hasher.update(F.getName());
Hasher.final(Hash);
SmallString<32> HexString;
llvm::MD5::stringifyResult(Hash, HexString);
F.setName(HexString);
errs() << "EncodeFunctionName after: "<<HexString<<'\n';
}
}
return false;
}
}; // end of struct Hello
} // end of anonymous namespace
char EncodeFunctionName::ID = 0;
static RegisterPass<EncodeFunctionName> X("encode", "Hello EncodeFunctionName Pass",
false /* Only looks at CFG */,
false /* Analysis Pass */);
Pass* llvm::createEncodeFunctionName(bool flag){
return new EncodeFunctionName(flag);
}EncodeFunctionName还需要两个比较重要的文件
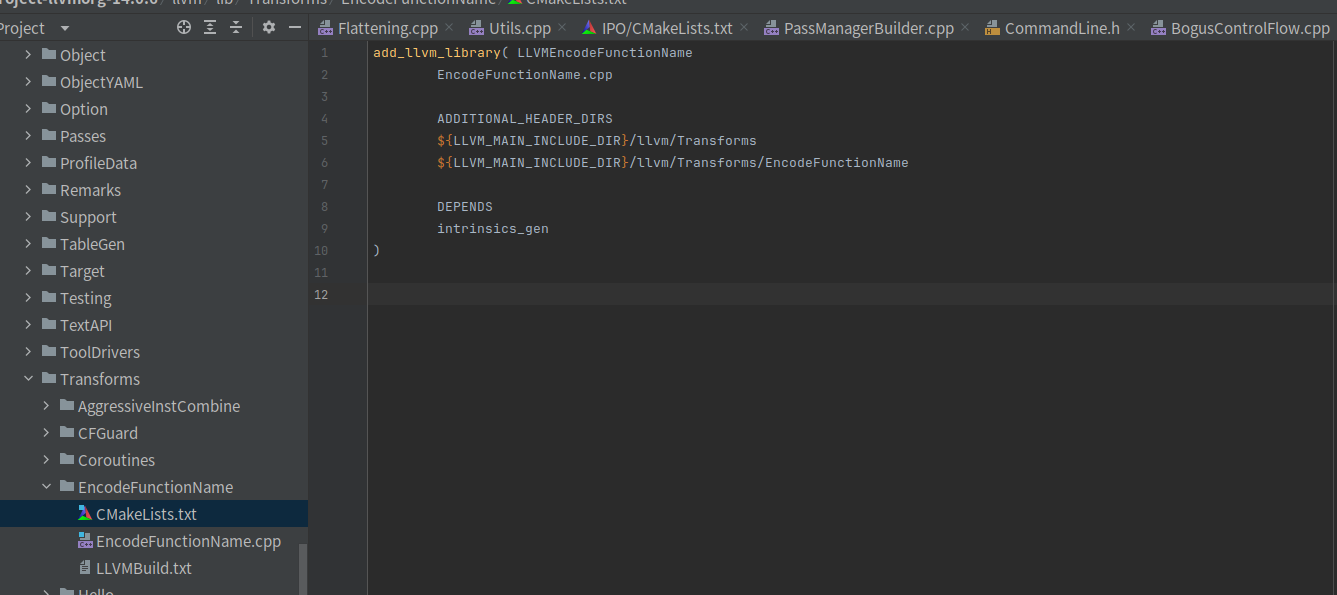
add_llvm_library( LLVMEncodeFunctionName
EncodeFunctionName.cpp
ADDITIONAL_HEADER_DIRS
${LLVM_MAIN_INCLUDE_DIR}/llvm/Transforms
${LLVM_MAIN_INCLUDE_DIR}/llvm/Transforms/EncodeFunctionName
DEPENDS
intrinsics_gen
)
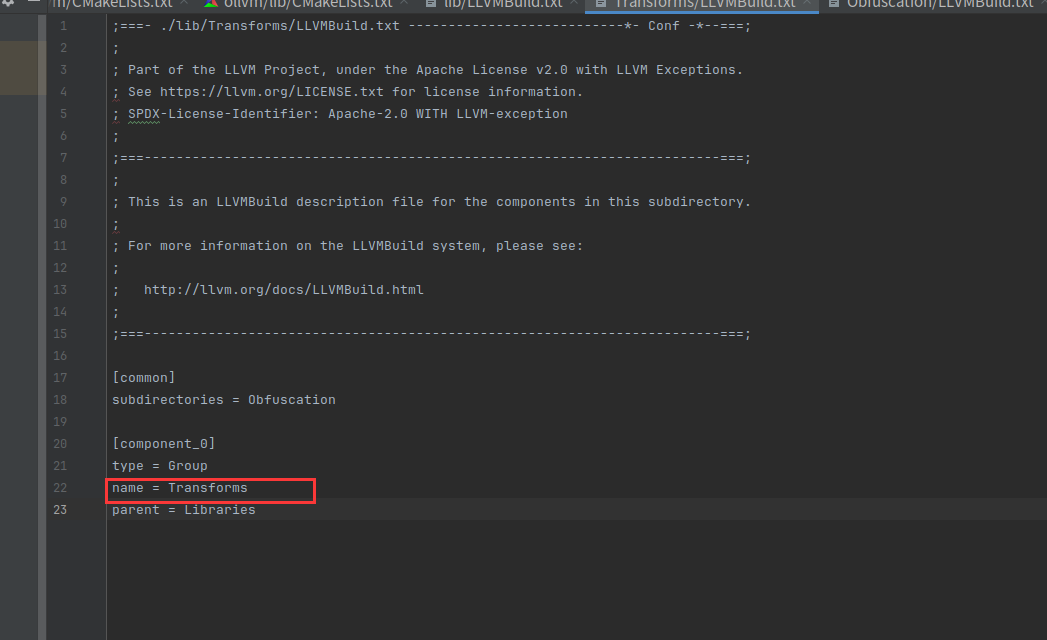
还有个LLVMBuild.txt,这个测试删了也没啥影响,好像是老版本才用到的
;===- ./lib/Transforms/Scalar/LLVMBuild.txt --------------------*- Conf -*--===;
;
; The LLVM Compiler Infrastructure
;
; This file is distributed under the University of Illinois Open Source
; License. See LICENSE.TXT for details.
;
;===------------------------------------------------------------------------===;
;
; This is an LLVMBuild description file for the components in this subdirectory.
;
; For more information on the LLVMBuild system, please see:
;
; http://llvm.org/docs/LLVMBuild.html
;
;===------------------------------------------------------------------------===;
[component_0]
type = Library
name = EncodeFunctionName
parent = Transforms
library_name = EncodeFunctionName
required_libraries = TransformUtils Analysis Core Support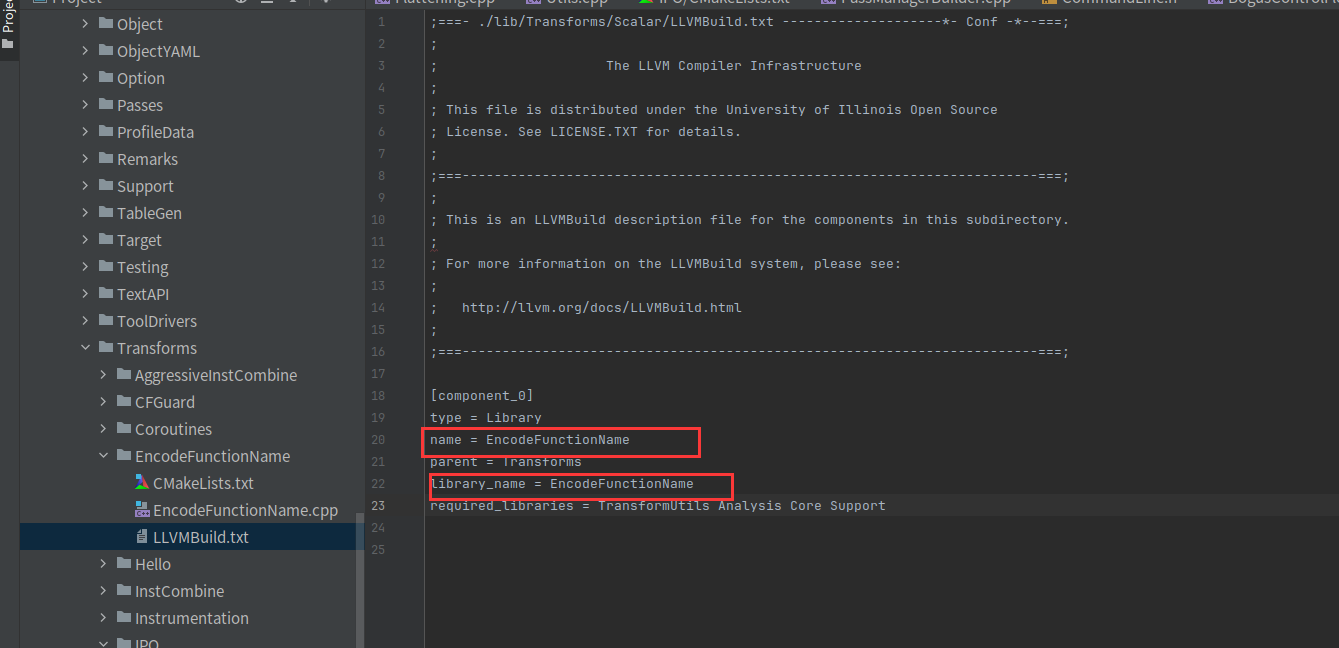
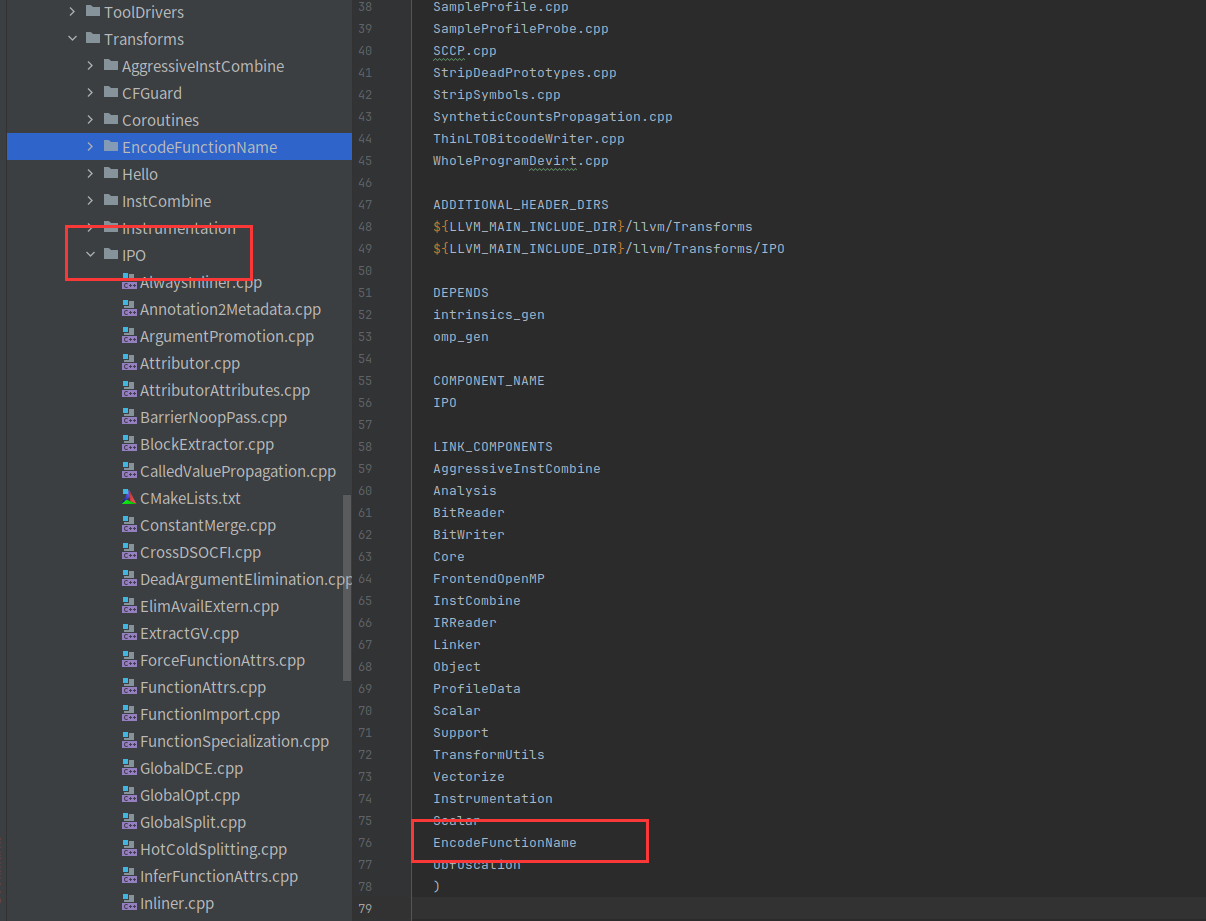
现在我们还需要把pass注册到clang的命令行,在IPO的CMakeLists.txt加入我们的pass模块
我们说了这么久,还不知道clang到底用什么参数来执行pass,现在来定义一下参数名,之后我们在使用clang时输入-encode 就可以执行我们的pass
//Flags for my pass
static cl::opt<bool> EncodeFunction("encode", cl::init(false),
cl::desc("Enable my pass"));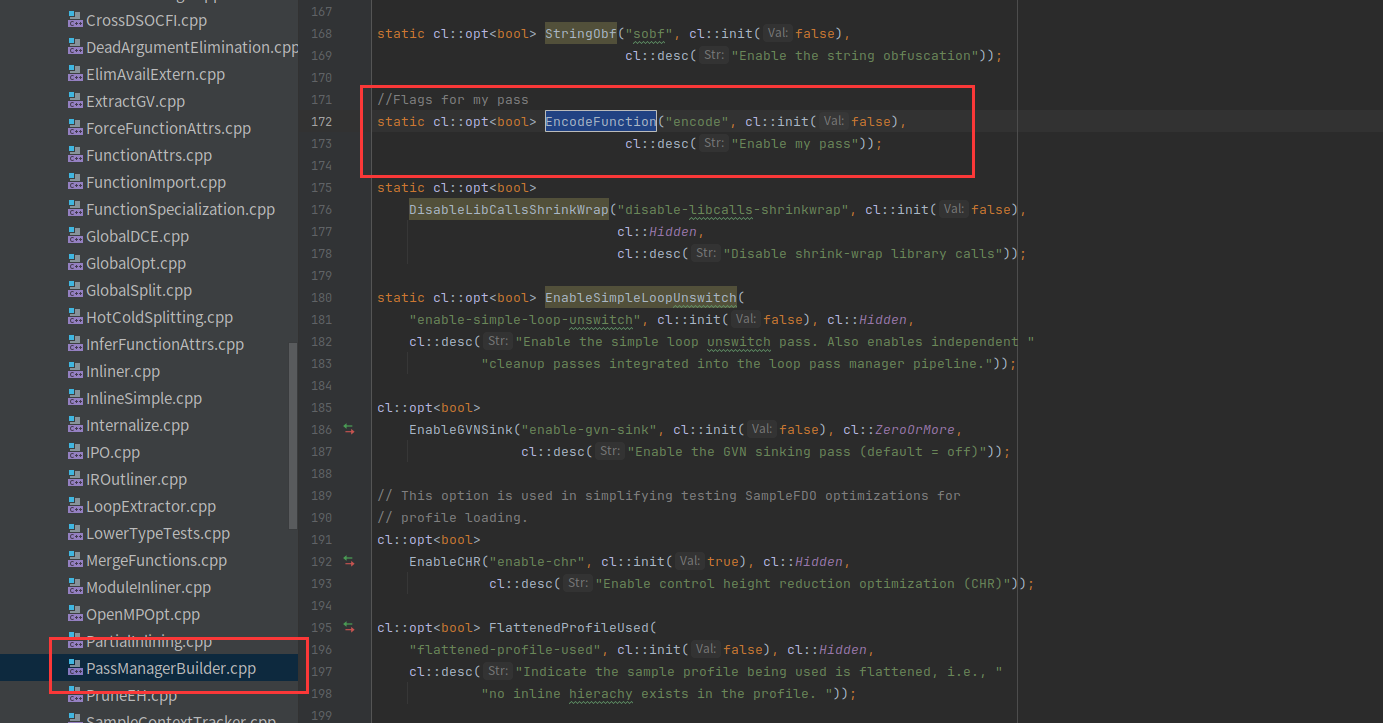
使用add把pass加入到manager,createEncodeFunctionName是我们之前定义的,参数是EncodeFunction,是我们上面定义的clang参数名,此时如果我们在clang中使用了-encode,EncodeFunction就表示true,也就是会执行pass
MPM.add(createEncodeFunctionName(EncodeFunction));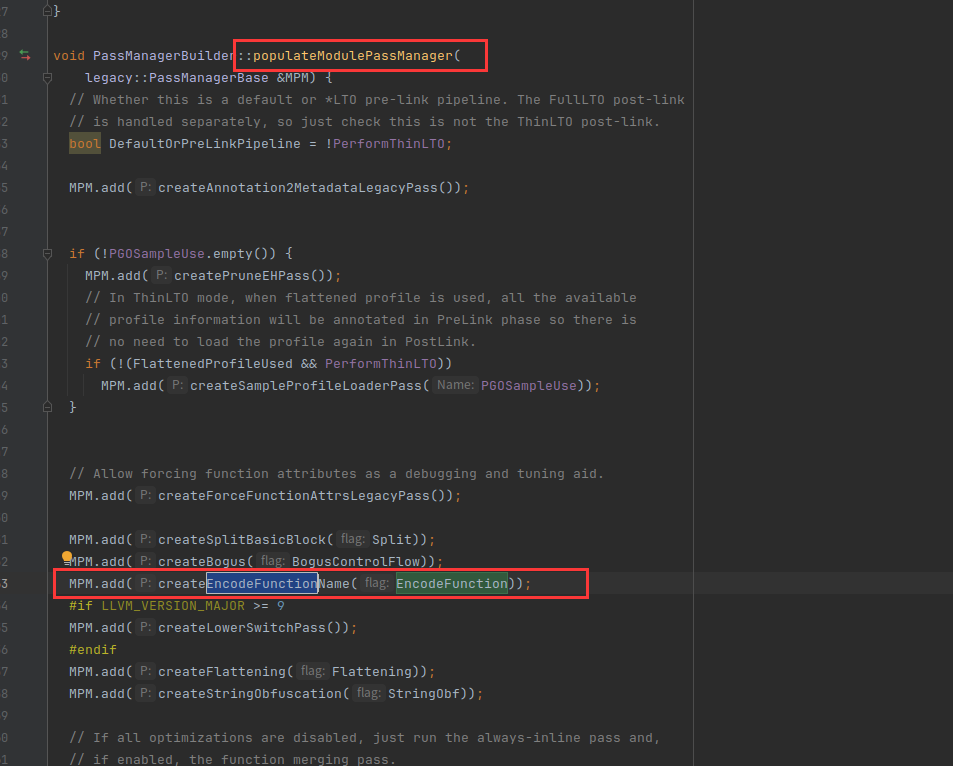
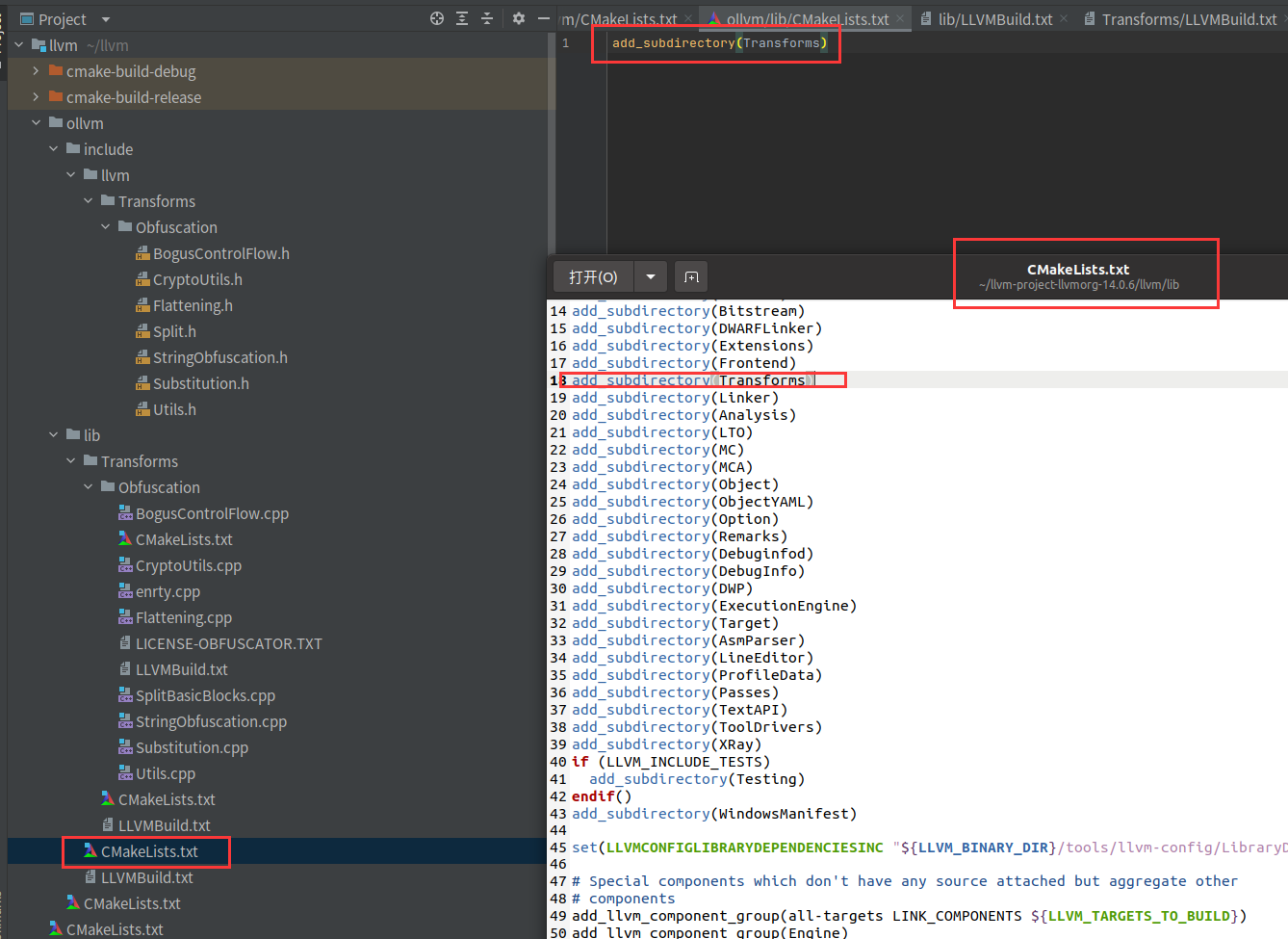
最外层的CMakeLists.txt也要修改
然后去编译,在llvm项目根目录下进行配置
sudo cmake -S llvm -B build -G Ninja -DLLVM_ENABLE_PROJECTS="clang" -DCMAKE_BUILD_TYPE=Release -DLLVM_INCLUDE_TESTS=OFF -DLLVM_ENABLE_NEW_PASS_MANAGER=OFF
编译
sudo cmake --build build -j16
编译好的clang在/llvm-project-llvmorg-14.0.6/build/bin下
测试效果

14、脱离源码调试opt和pass
接着用12的项目
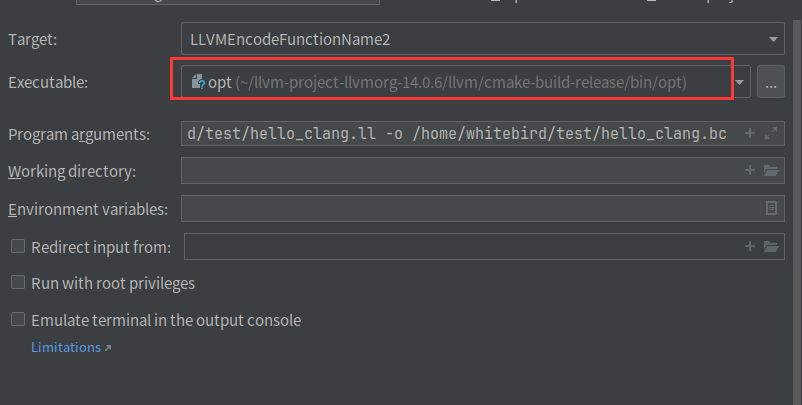
参数
-load /home/whitebird/outPass/cmake-build-debug/EncodeFunctionName2/LLVMEncodeFunctionName2.so -encode -enable-new-pm=0 /home/whitebird/test/hello_clang.ll -o /home/whitebird/test/hello_clang.bc 然后下断点就可以直接调试了
15、将OLLVM移植到LLVM14
最早的ollvm:https://github.com/obfuscator-llvm/obfuscator/tree/llvm-4.0
只支持到ollvm4.0,我们尝试把它移植到llvm14
项目参考:https://github.com/buffcow/ollvm-project/tree/14.x
可以直接下载编译,也可以看他修改了哪些地方
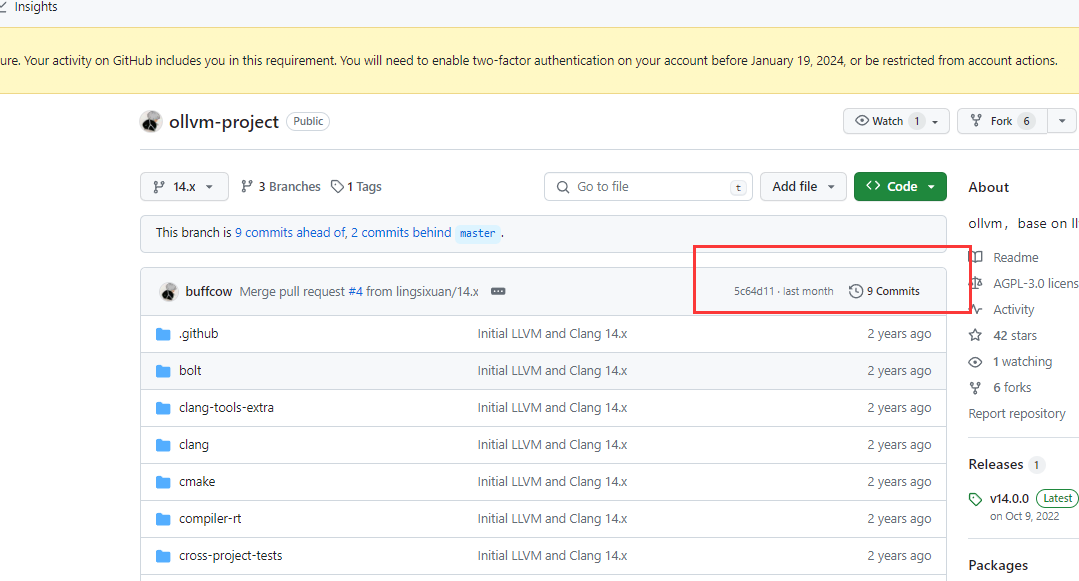
主要分为三步:添加ollvm的*.cpp代码、添加ollvm的*.h代码、注册到clang
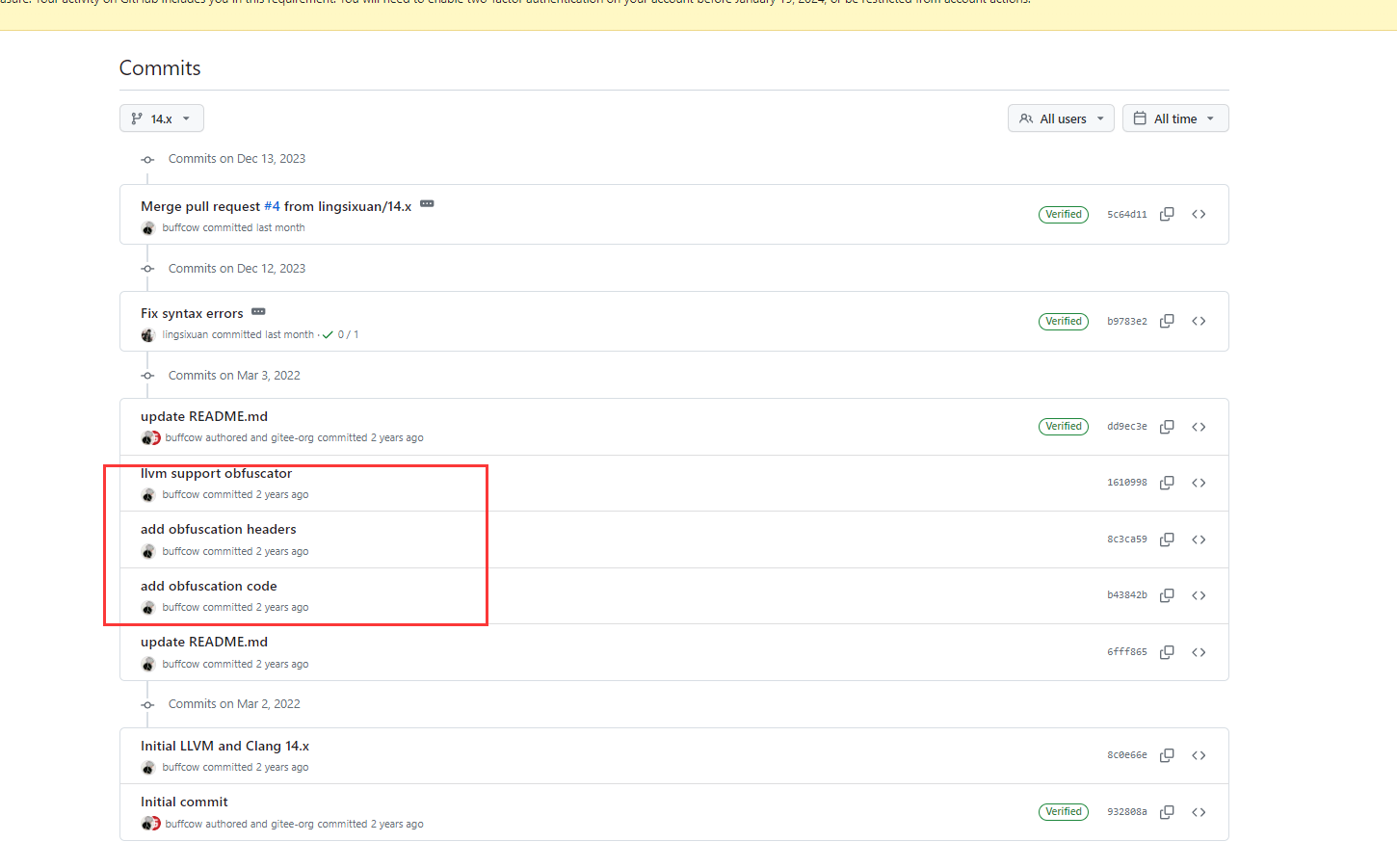
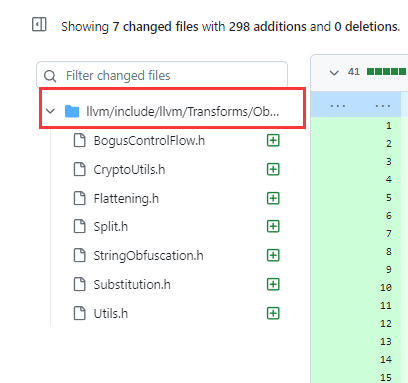
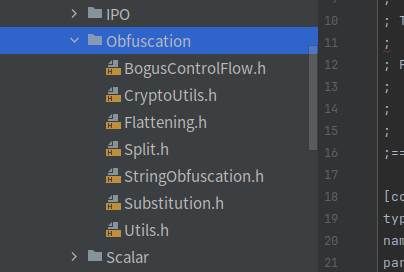
就是这些文件,放到图中的目录下
然后添加头
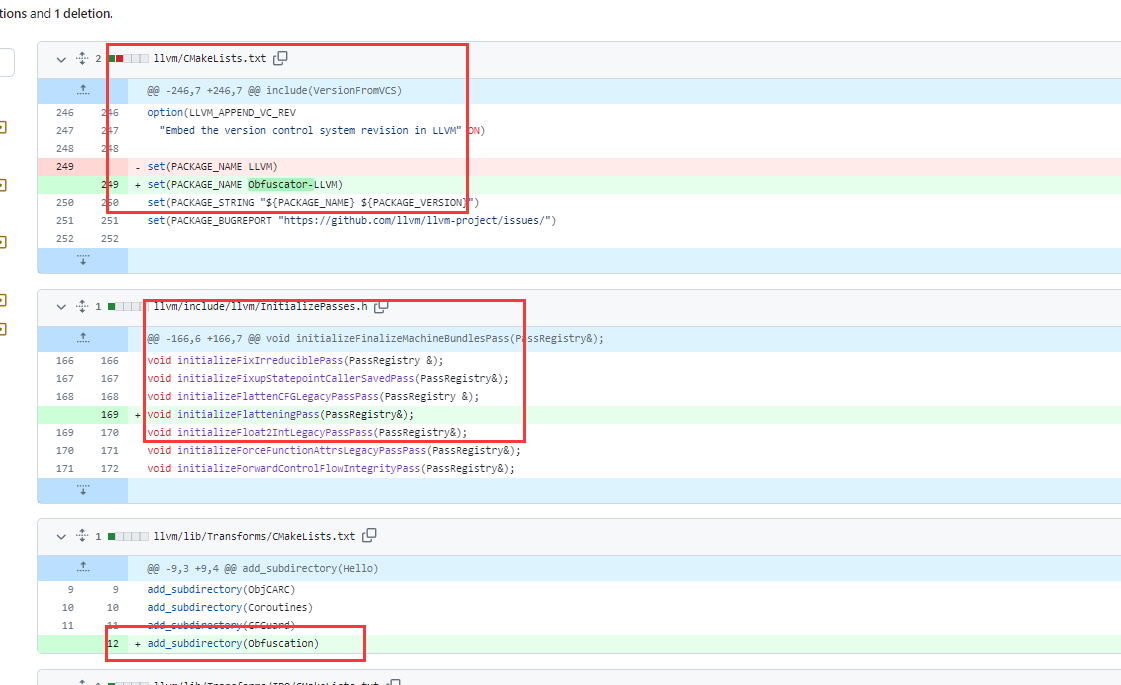
接着就是注册到clang,和之前我们自己写的pass注册差不多
都是对着改就行了
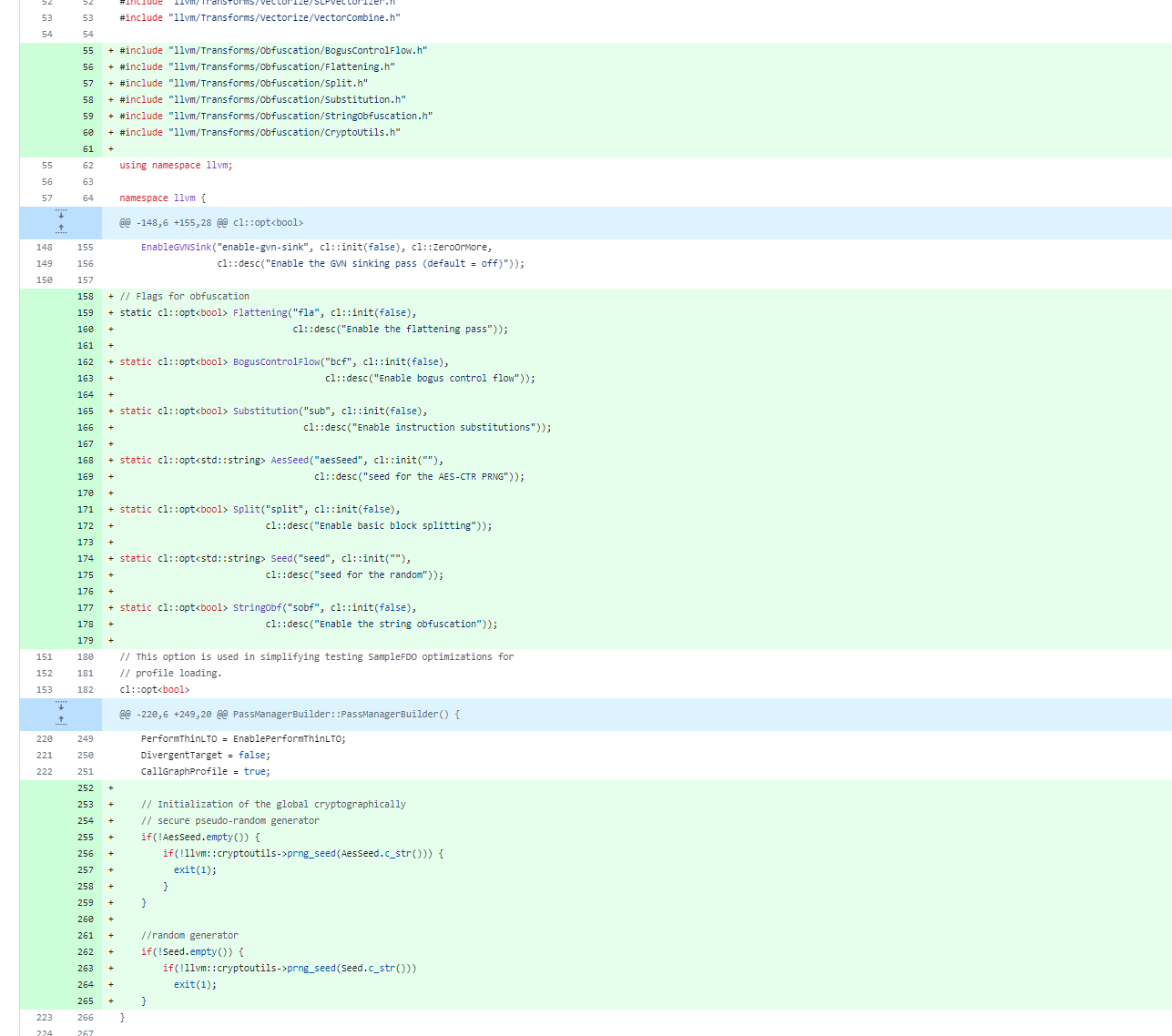
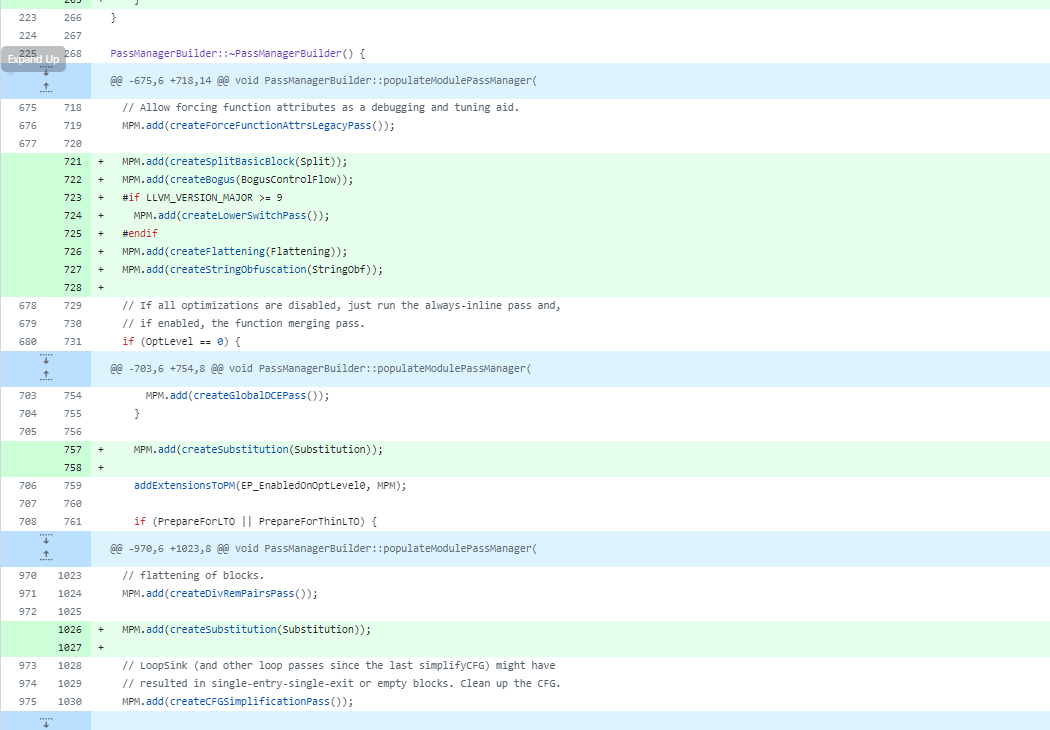
可以直接搜附近的官方代码进行定位
接着就是编译了
sudo cmake -S llvm -B build -G Ninja -DLLVM_ENABLE_PROJECTS="clang" -DCMAKE_BUILD_TYPE=Release -DLLVM_INCLUDE_TESTS=OFF -DLLVM_ENABLE_NEW_PASS_MANAGER=OFF
sudo cmake --build build -j16然后就可以正常使用了
16、OLLVM使用
https://github.com/obfuscator-llvm/obfuscator/wiki/Installation
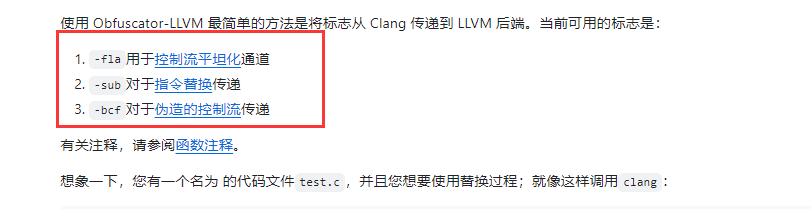
主要是这三种
-sub
描述
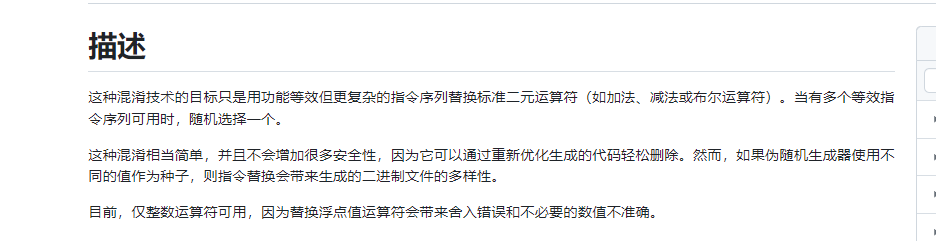
加法
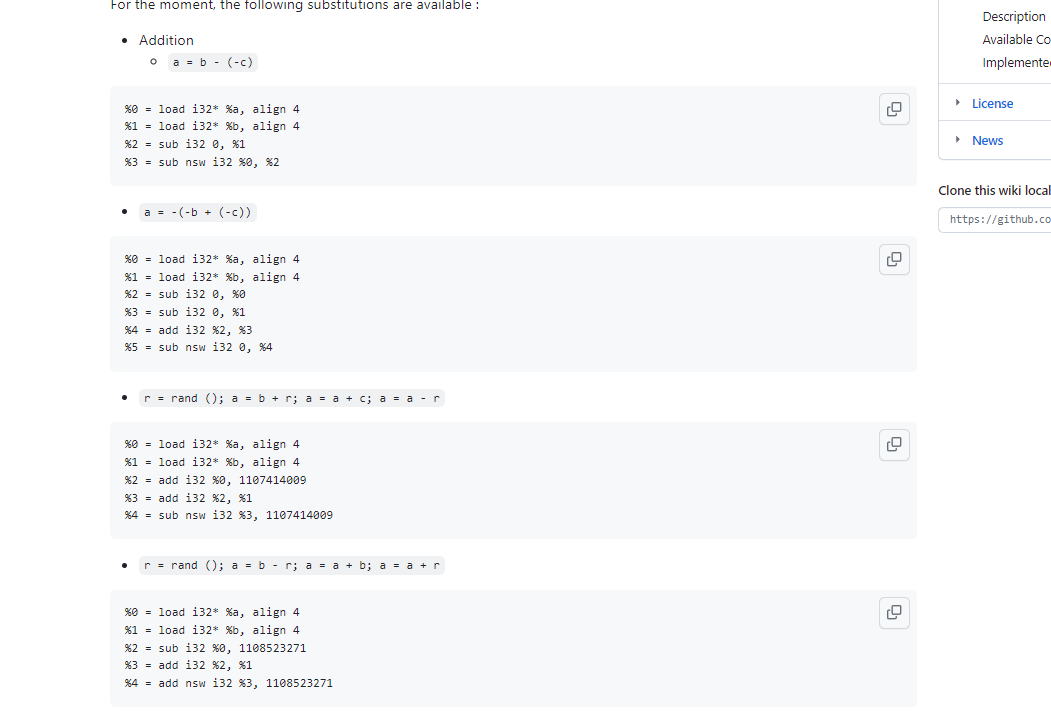
有好几种变换形式,对于有随机数的会复杂一点
1. a = b - (-c)
2. a = -(-b + (-c))
3. r = rand (); a = b + r; a = a + c; a = a - r
4. r = rand (); a = b - r; a = a + b; a = a + r减法
1. a = b + (-c)
2. r = rand (); a = b + r; a = a - c; a = a - r
3. r = rand (); a = b - r; a = a - c; a = a + rAND运算混淆
a = b & c => a = (b ^ ~c) & b
OR运算混淆
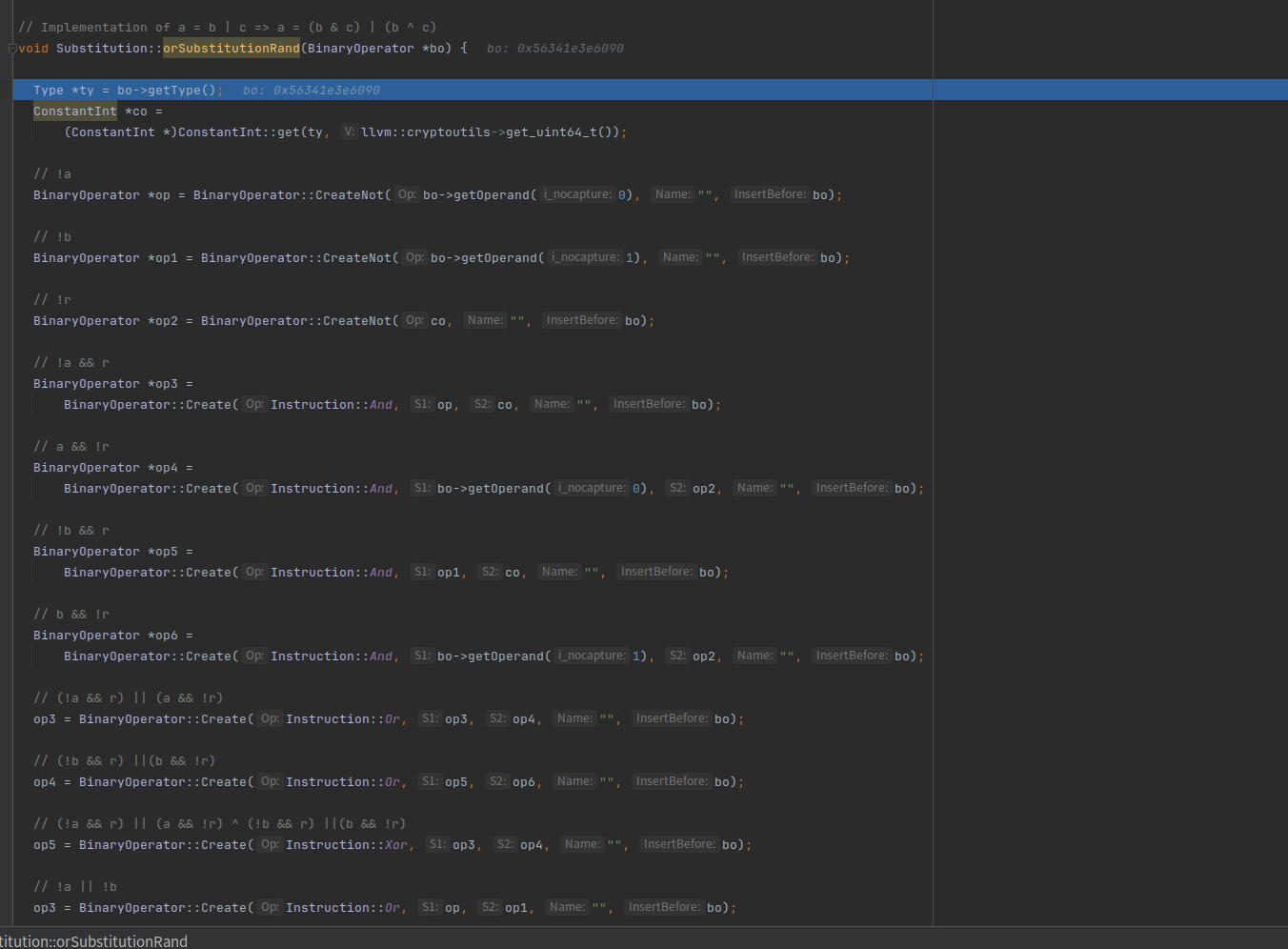
a = b | c => a = (b & c) | (b ^ c)
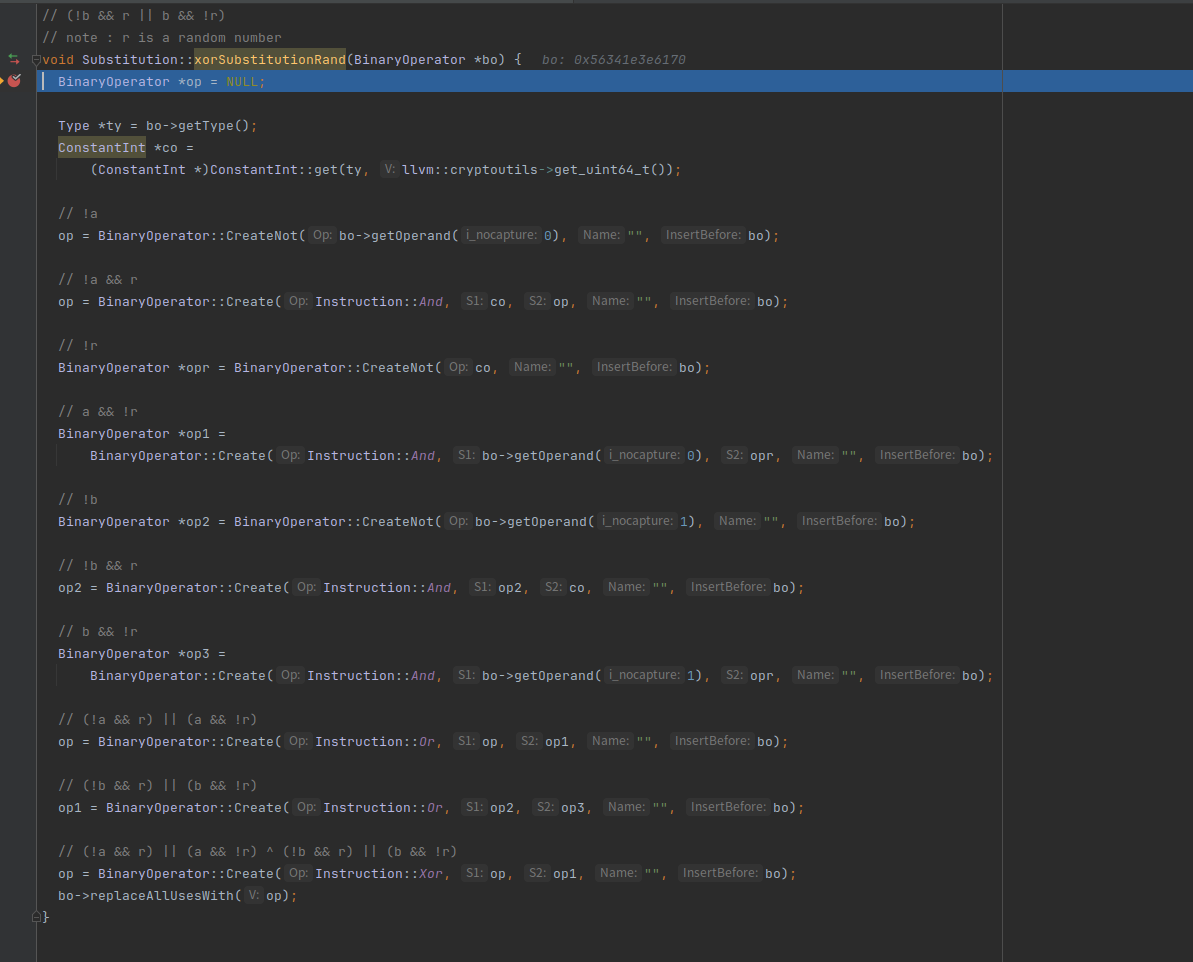
XOR运算混淆
a = a ^ b => a = (~a & b) | (a & ~b)
使用
有两种方法

-mllvm -sub
sudo ./clang -mllvm -sub hello.c -o hello_sub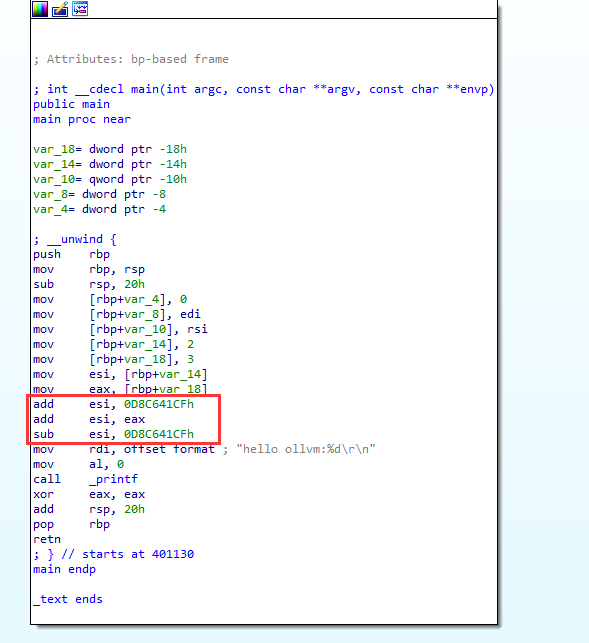
可以看到esi先加一个0D8C641CF,然后又减去0D8C641CF,没影响
F5的时候,IDA自动帮我们优化了
-mllvm -sub_loop
加个-mllvm -sub_loop=3试试
sudo ./clang -mllvm -sub -mllvm -sub_loop=3 hello.c -o hello_sub_loop汇编代码看起来稍微复杂了一些
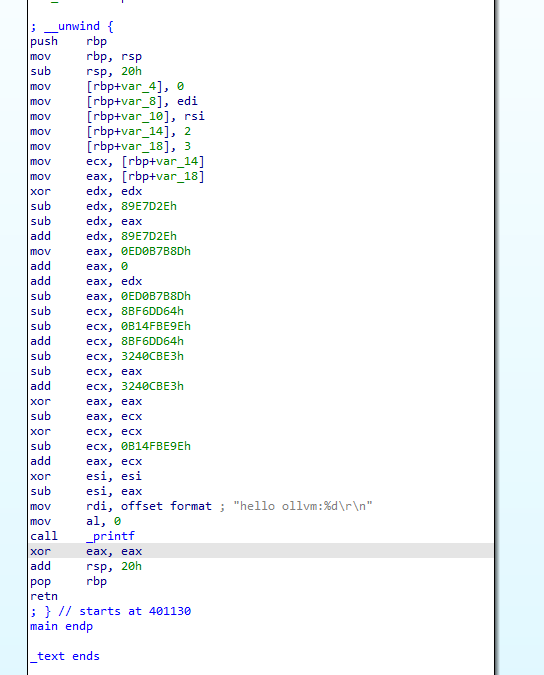
F5还是自动优化了
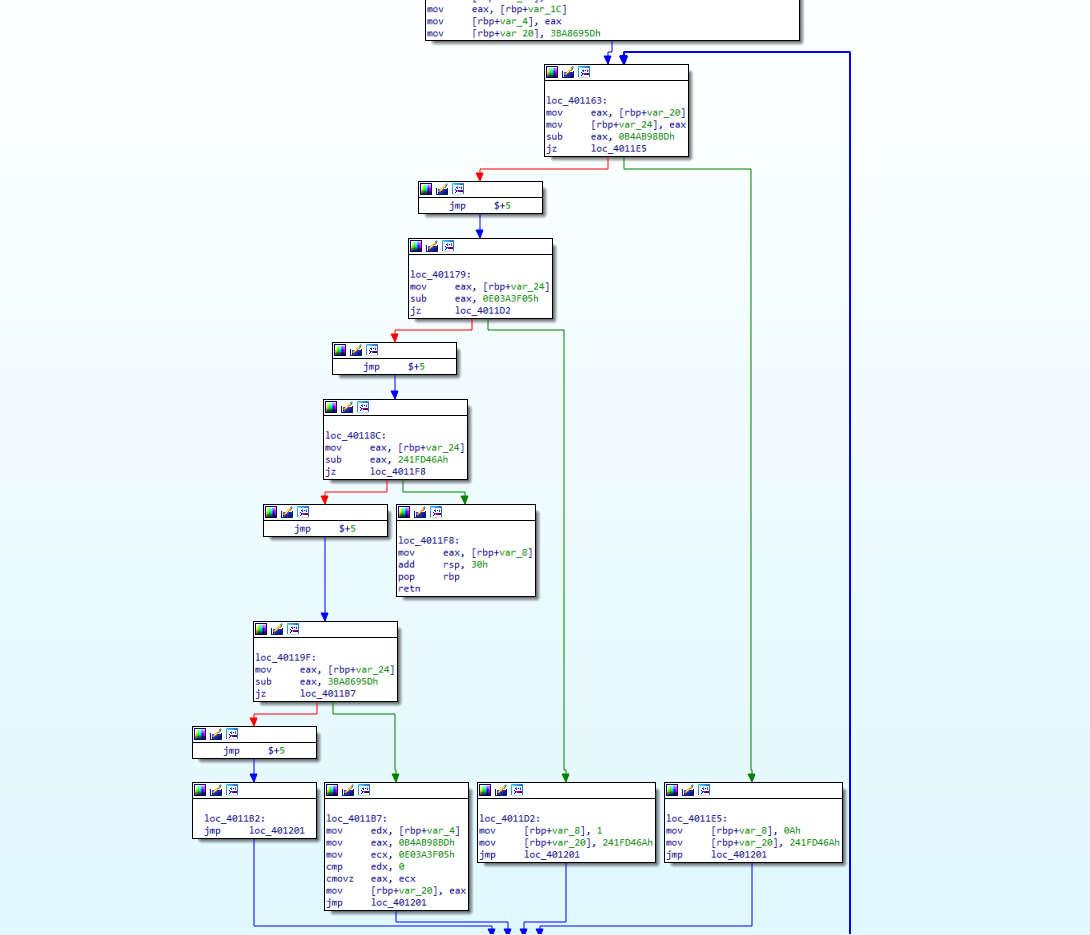
-bcf
描述

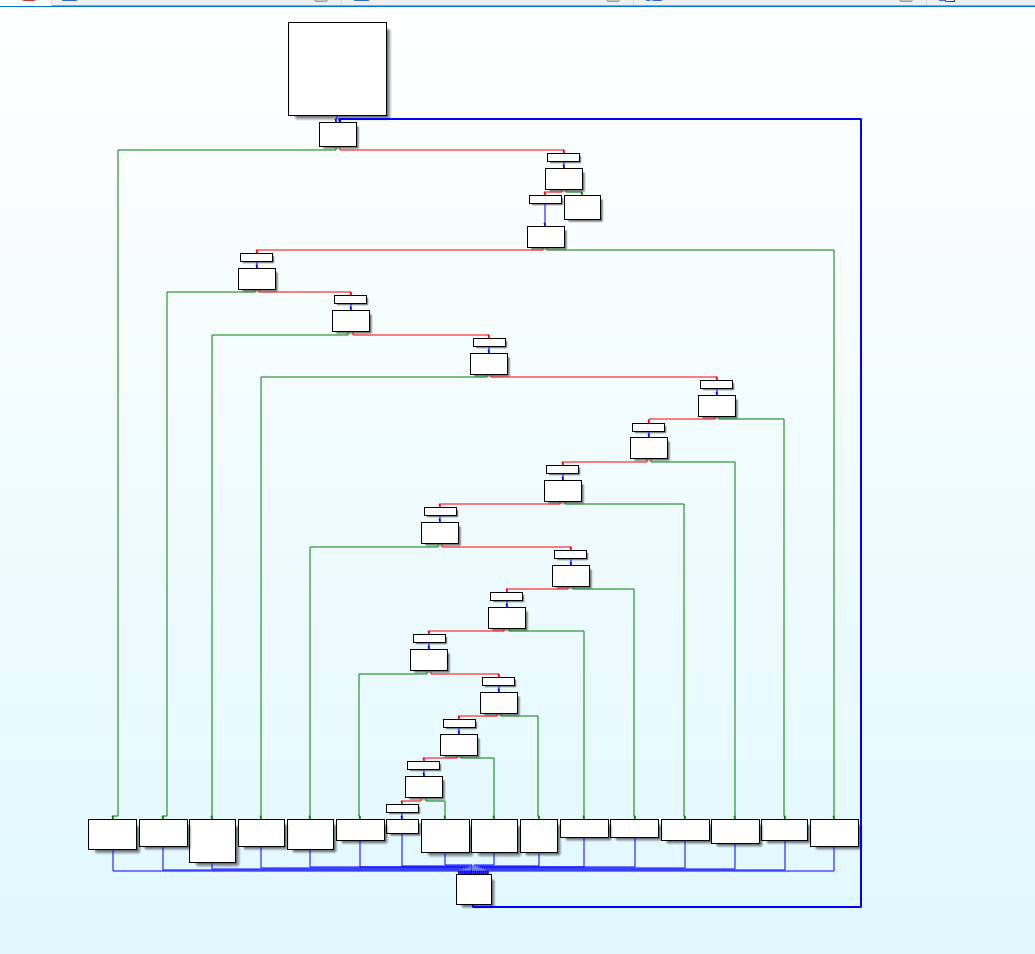
bogus control flow通过在源程序的控制流中添加一些基本块,这些基本块仅仅起了连接作用,并不影响实际的执行逻辑。
函数调用图
示例
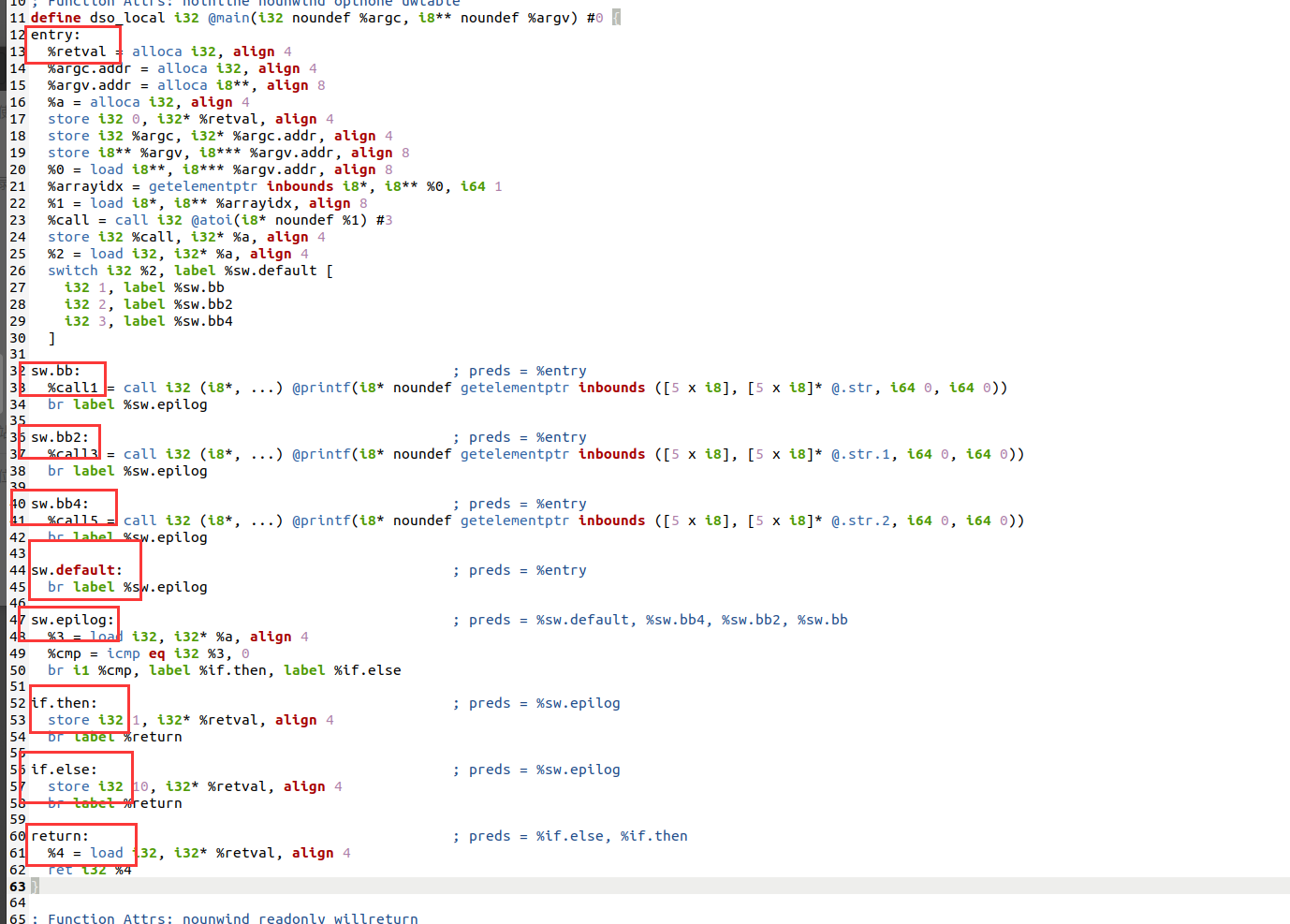
#include <stdlib.h>
int main(int argc, char** argv) {
int a = atoi(argv[1]);
if(a == 0)
return 1;
else
return 10;
return 0;
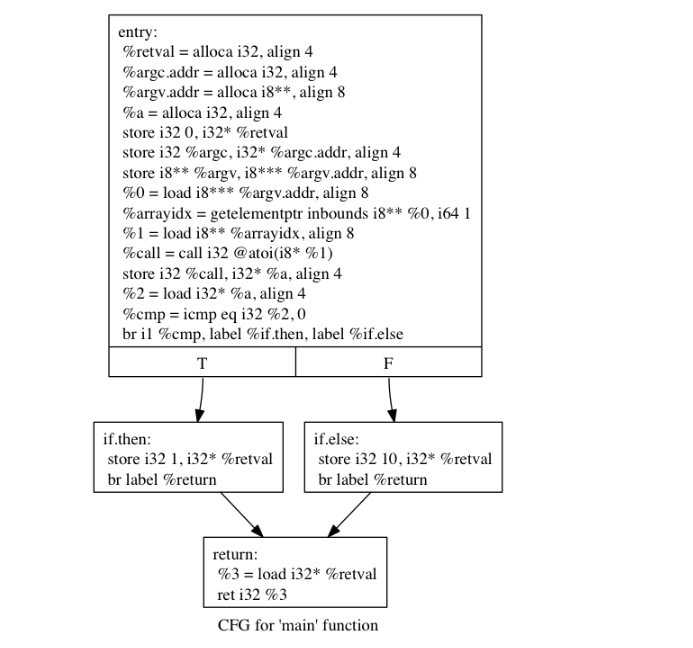
}看一下他的ir函数调用图
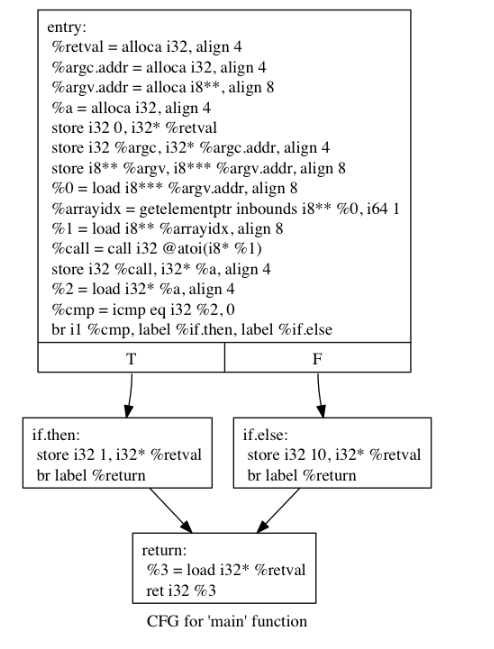
在伪造的控制流传递之后,我们可能会得到以下流程图
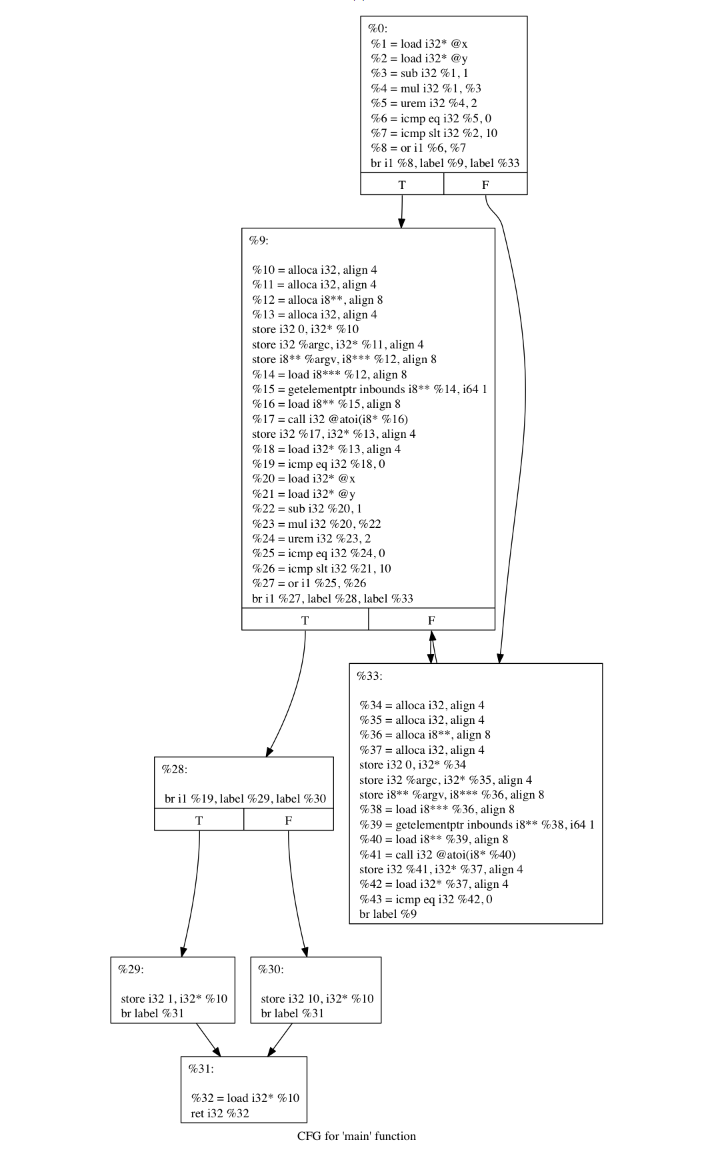
使用
可以使用的参数

-mllvm -bcf
sudo ./clang -mllvm -bcf hello.c -o hello_bcf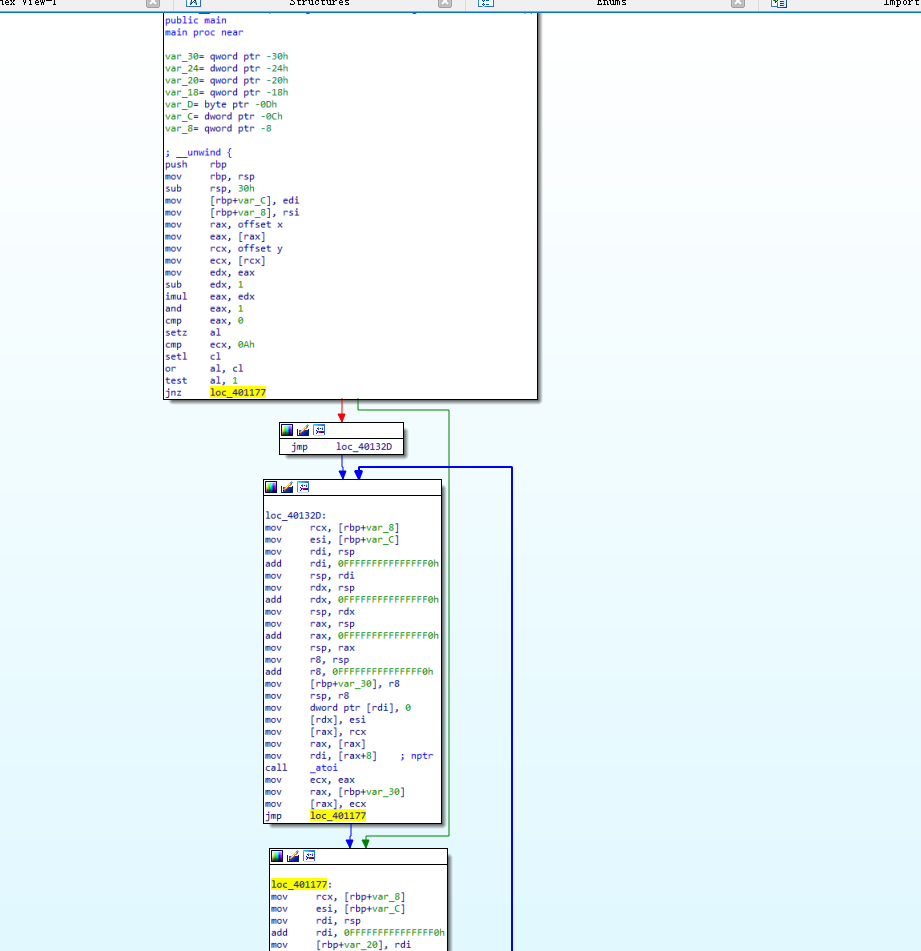
F5一下,有点难看了
-mllvm -bcf_loop
有一些基本块是虚假的,并不会执行。我们继续加参数
./clang -mllvm -bcf -mllvm -bcf_loop=3 hello.c -o hello_bcf_loop1已经很复杂很长了,对比最初的源码还是难看的
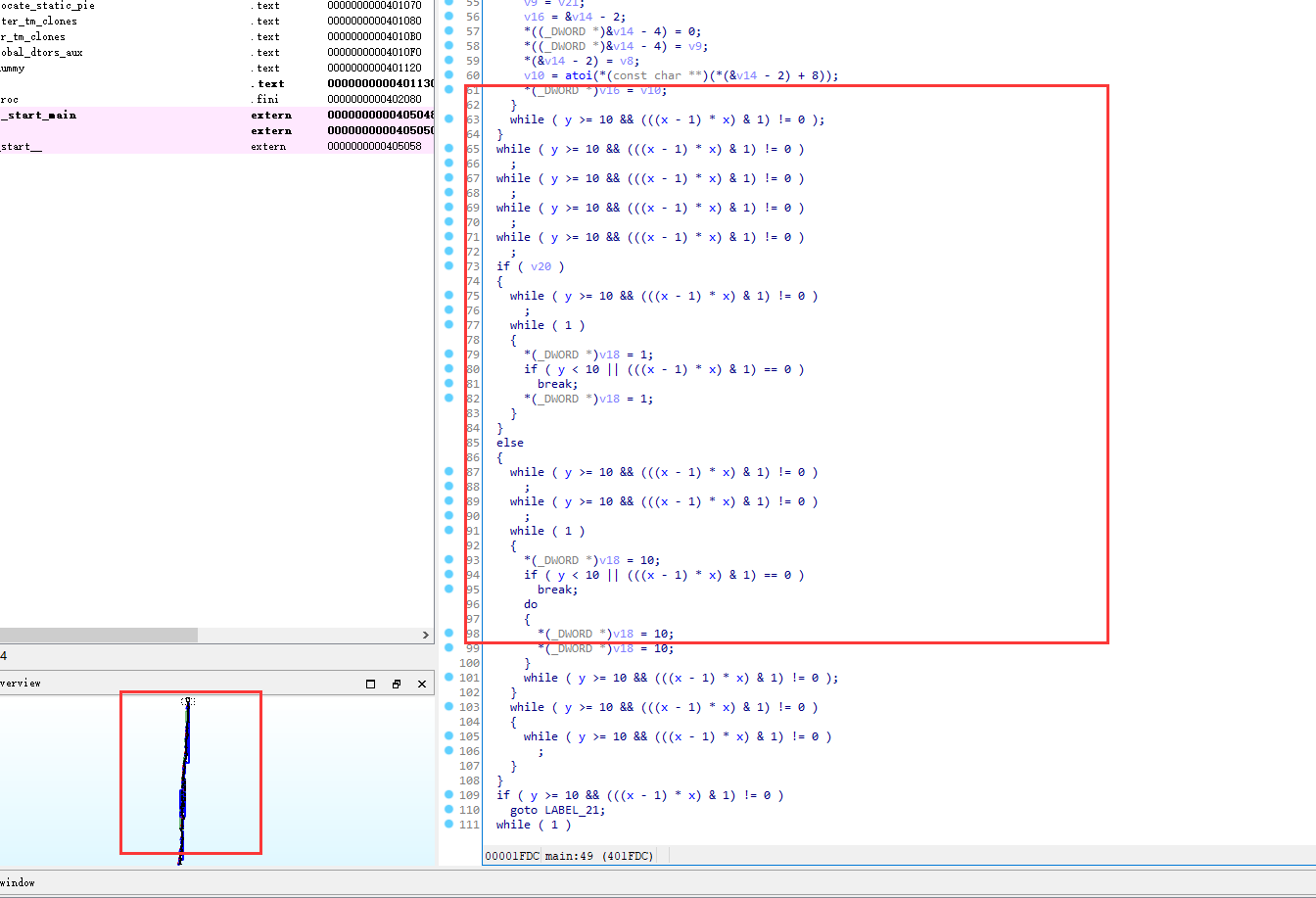
-mllvm -bcf_prob
./clang -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -bcf_prob=80 hello.c -o hello_bcf_loop_prob
-fla
描述

control flow flattening(控制流平坦化)通过多个case-swich结构将程序的控制流变成扁平形状,打破原有的逻辑结构,增加逆向的难度。
实例
源码如下
#include <stdlib.h>
int main(int argc, char** argv) {
int a = atoi(argv[1]);
if(a == 0)
return 1;
else
return 10;
return 0;
}平坦化过程将把这段代码转换成这样
#include <stdlib.h>
int main(int argc, char** argv) {
int a = atoi(argv[1]);
int b = 0;
while(1) {
switch(b) {
case 0:
if(a == 0)
b = 1;
else
b = 2;
break;
case 1:
return 1;
case 2:
return 10;
default:
break;
}
}
return 0;
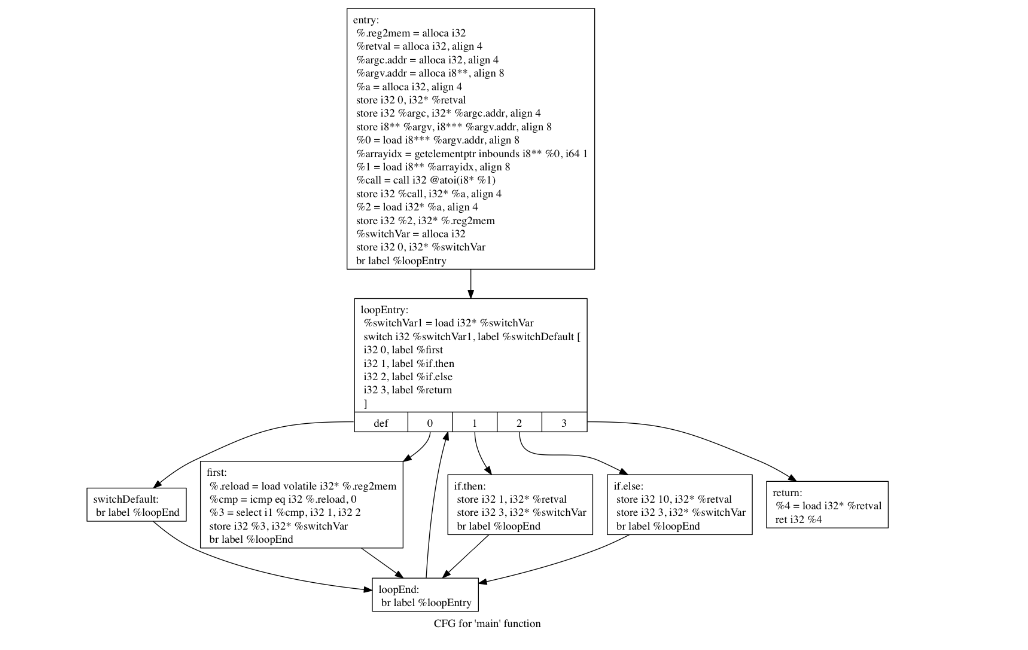
}可以看到,所有基本块都被分割并放入无限循环中,程序流程由 switch和变量b控制。
这是平坦化之前生成的控制流的样子
平坦化后,我们得到如下指令流程
使用
-mllvm -fla
./clang -mllvm -fla hello.c -o hello_fla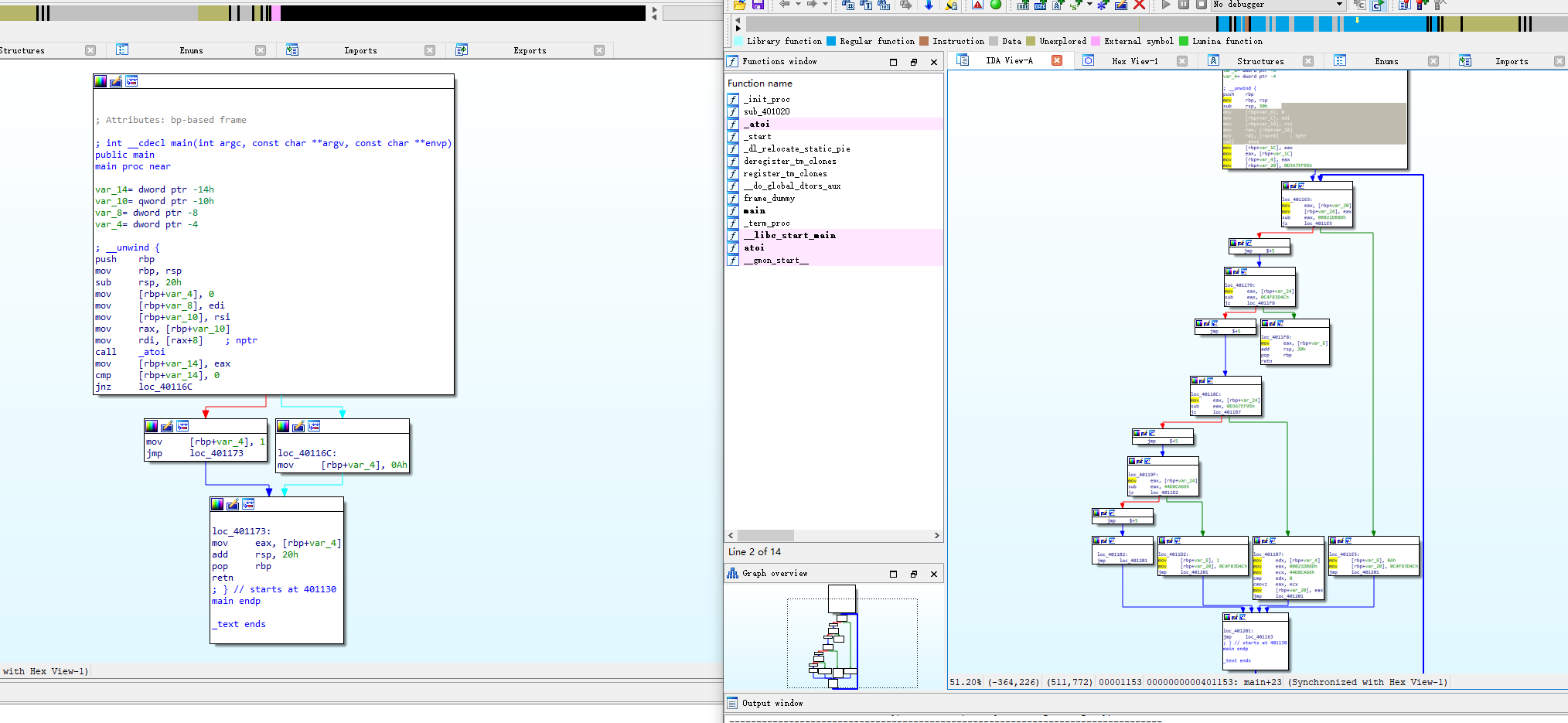
可以看到扁平化的特征,而且代码变复杂了
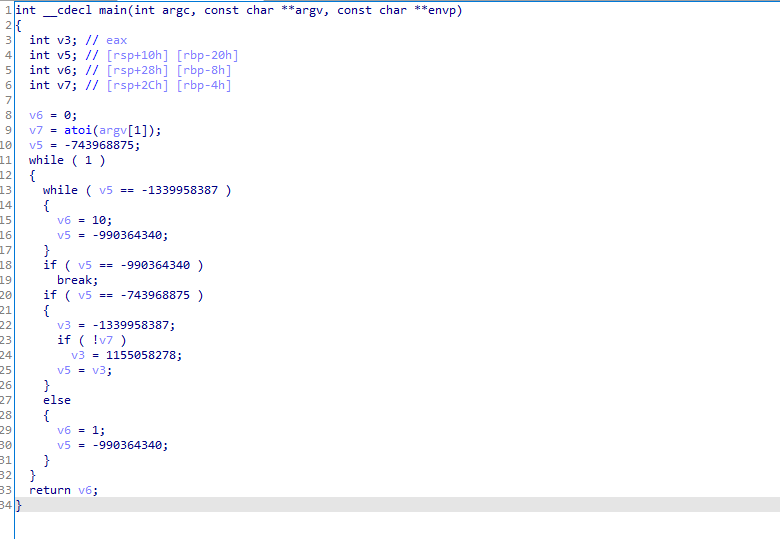
通过控制v5的值,跳出循环。其实是一个switch,但是ida没有分析出来
-mllvm -fla -mllvm -split
激活基本块分裂。一起使用时可改善平整度
./clang -mllvm -fla -mllvm -split hello.c -o hello_fla_split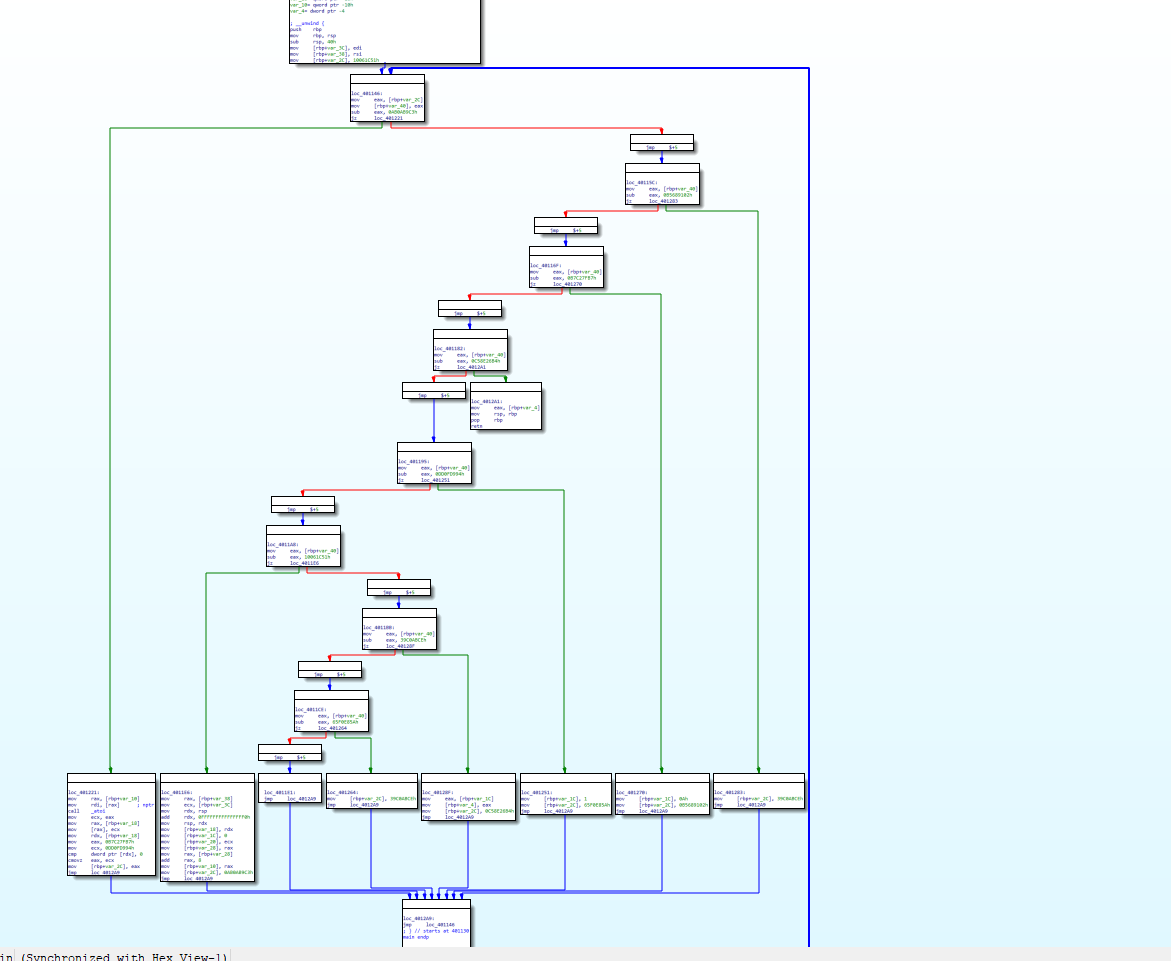
看起来更加平坦化了
-mllvm -split_num=3
在每个基本块上分裂 3 次
这个会使代码更复杂
./clang -mllvm -fla -mllvm -split -mllvm -split_num=3 hello.c -o hello_fla_split_num3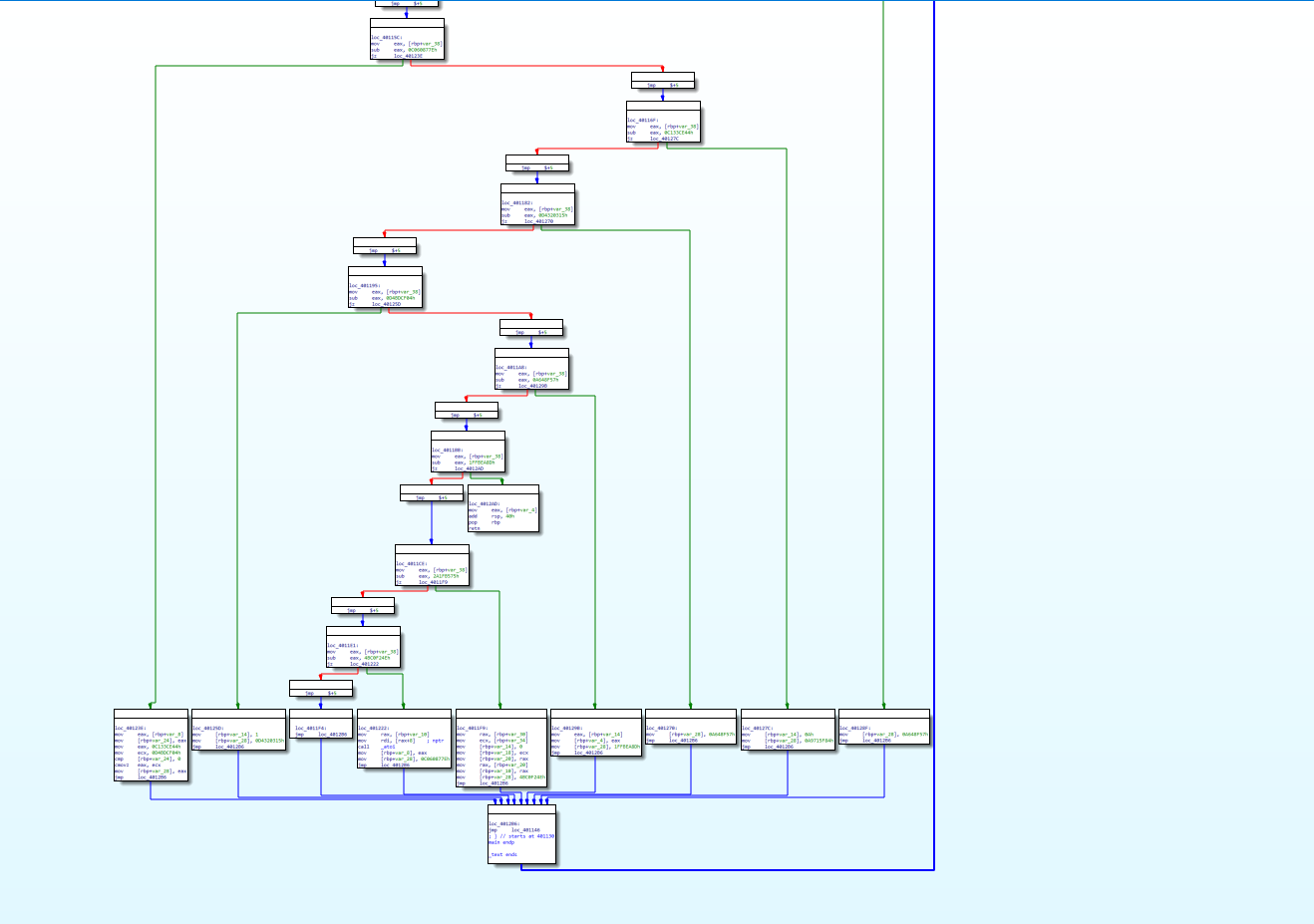
可能和上个差距不明显,我们把数字改大点,改成10
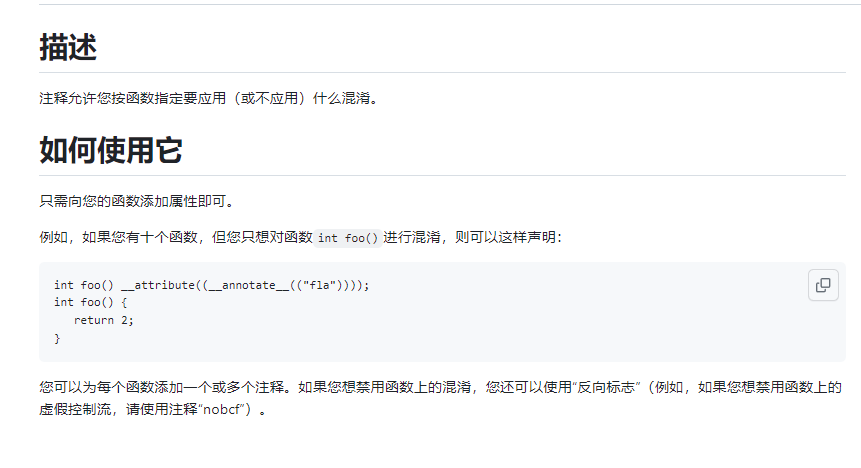
Functions annotations
17、脱离源码编译ollvm的pass
其实就是和之前脱离源码开发pass差不多,我们先创建一个文件树
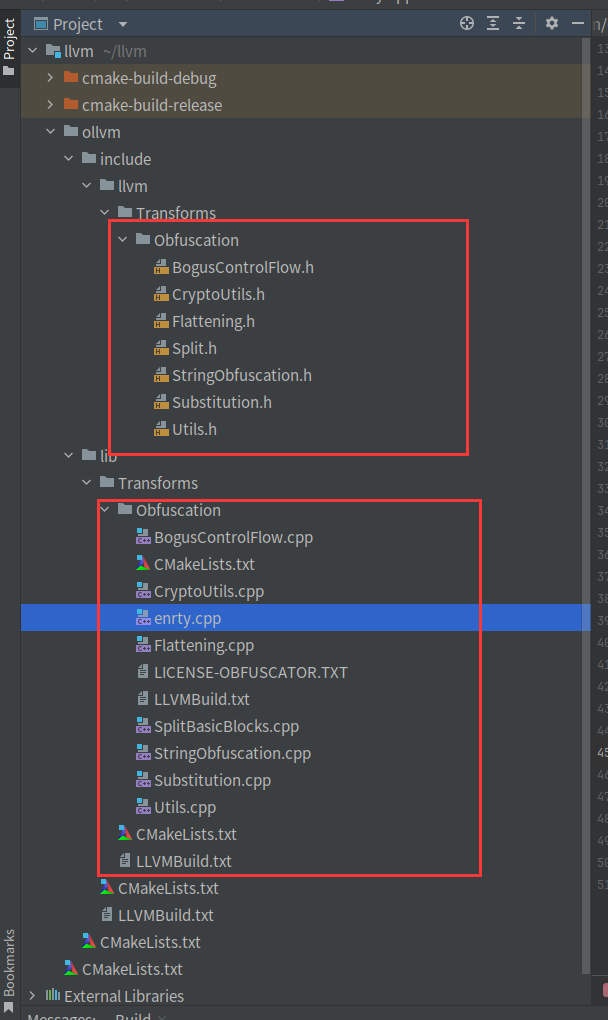
对于include没什么要改的,我们需要改的是源码中的一些CMakeLists.txt文件
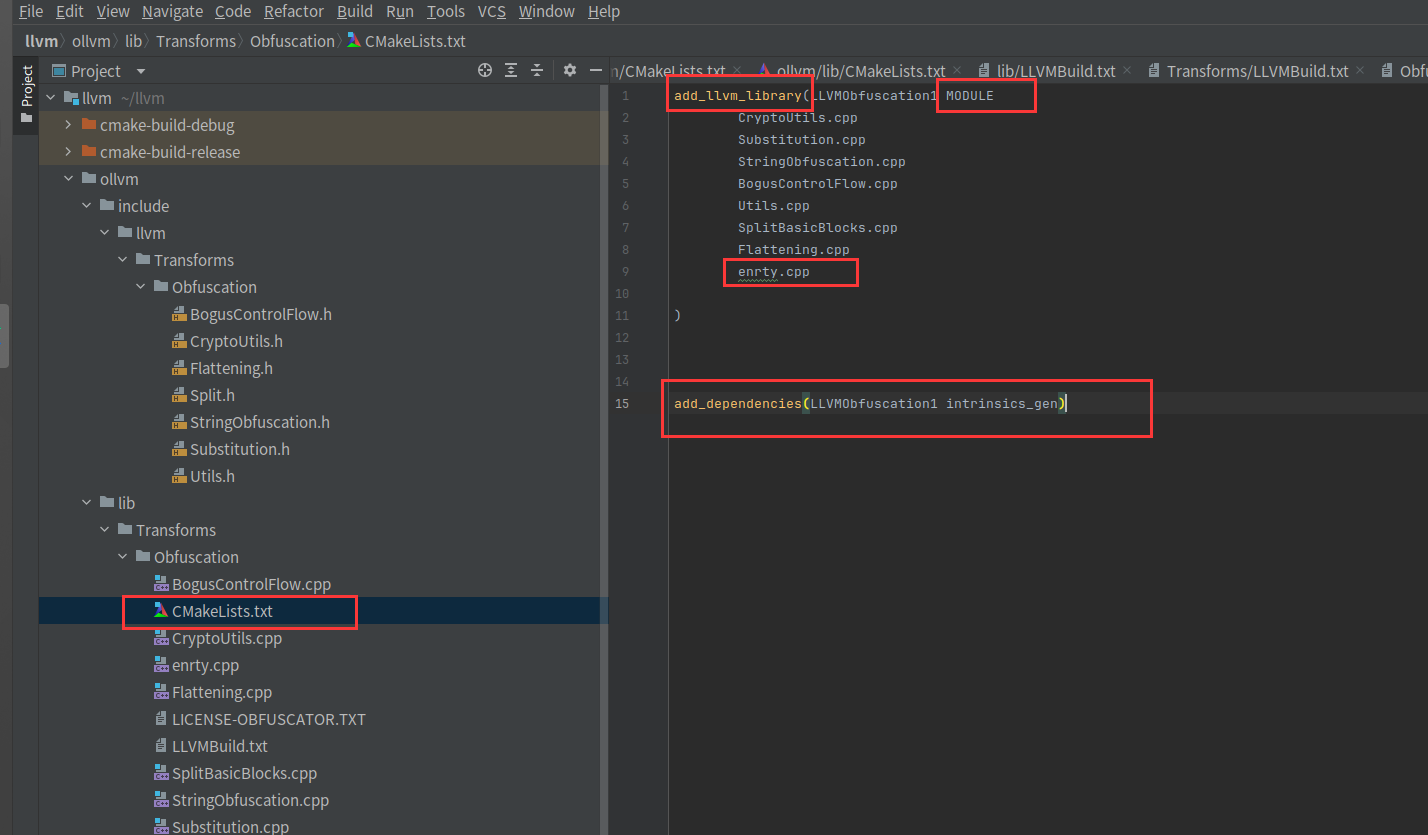
改成MODULE,这样编译出来是一个so,多了个cpp文件,这个entry.cpp是用来把命令行注册到clang的,后面再说
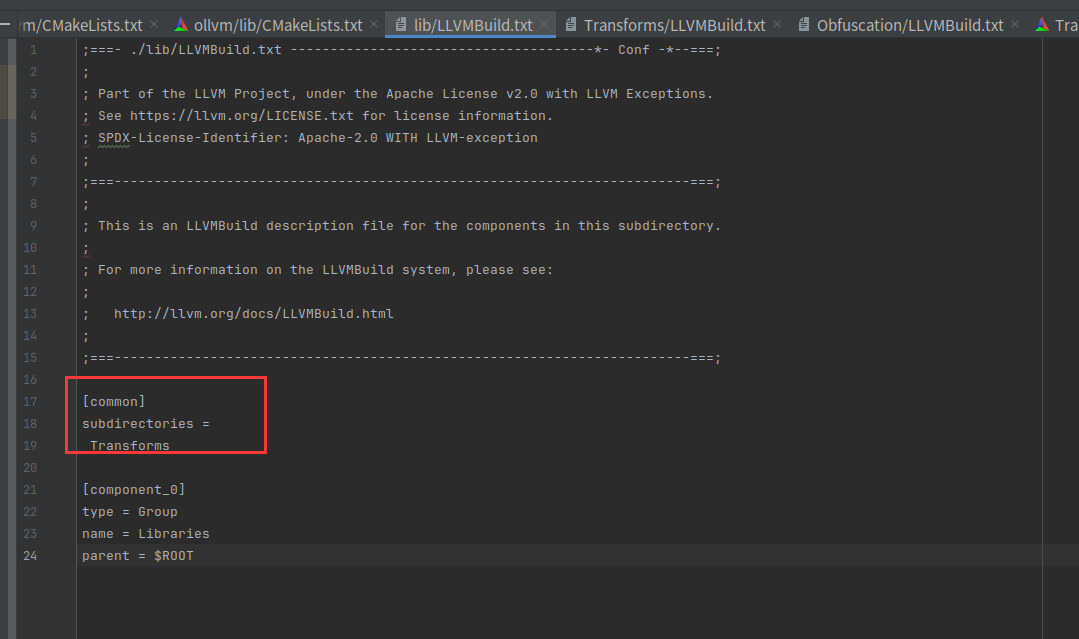
外层的其实就是把无关的模块给删了
LLVMBuild.txt也同理
同理
最外层的这个最重要
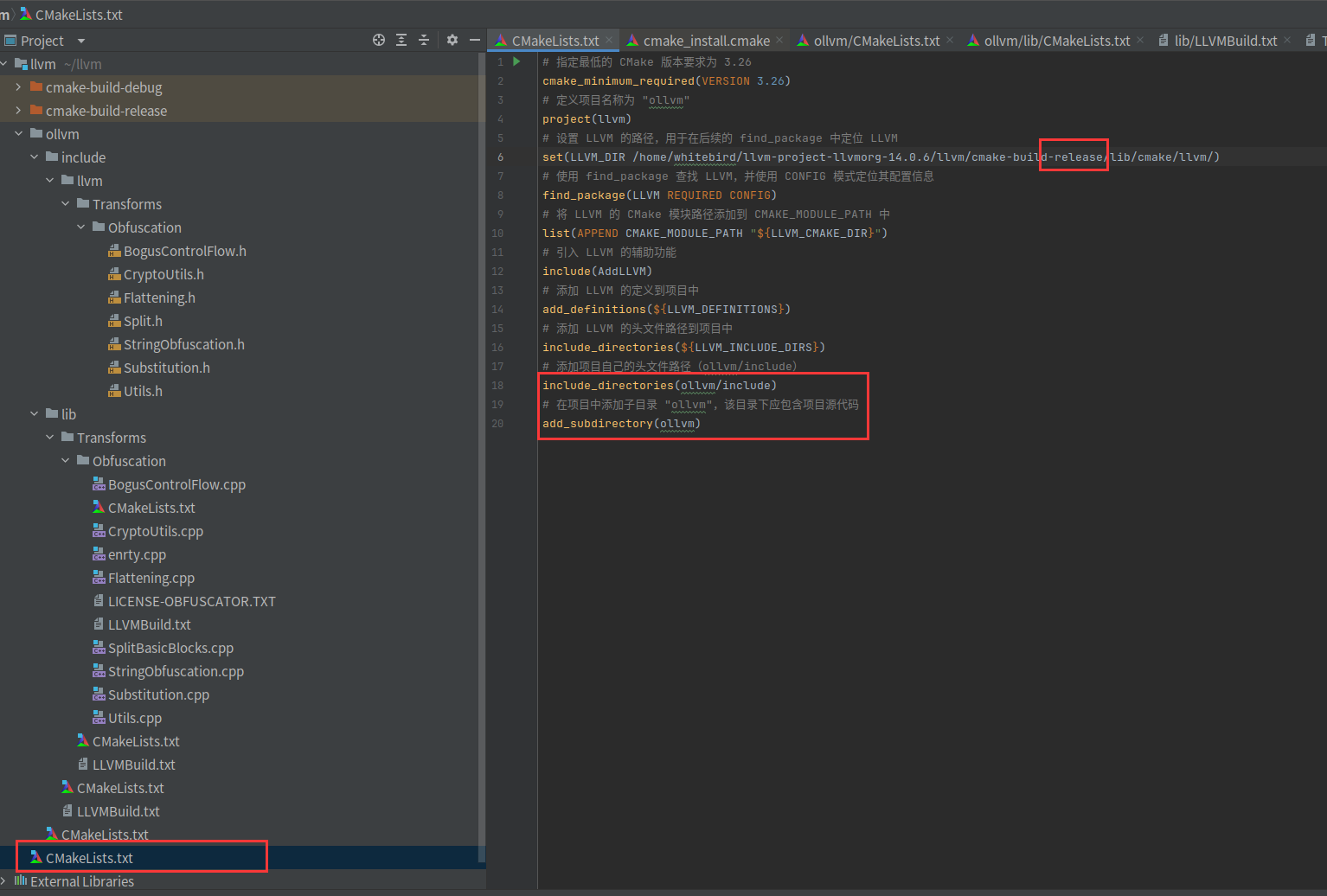
# 指定最低的 CMake 版本要求为 3.26
cmake_minimum_required(VERSION 3.26)
# 定义项目名称为 "ollvm"
project(llvm)
# 设置 LLVM 的路径,用于在后续的 find_package 中定位 LLVM
set(LLVM_DIR /home/whitebird/llvm-project-llvmorg-14.0.6/llvm/cmake-build-release/lib/cmake/llvm/)
# 使用 find_package 查找 LLVM,并使用 CONFIG 模式定位其配置信息
find_package(LLVM REQUIRED CONFIG)
# 将 LLVM 的 CMake 模块路径添加到 CMAKE_MODULE_PATH 中
list(APPEND CMAKE_MODULE_PATH "${LLVM_CMAKE_DIR}")
# 引入 LLVM 的辅助功能
include(AddLLVM)
# 添加 LLVM 的定义到项目中
add_definitions(${LLVM_DEFINITIONS})
# 添加 LLVM 的头文件路径到项目中
include_directories(${LLVM_INCLUDE_DIRS})
# 添加项目自己的头文件路径(ollvm/include)
include_directories(ollvm/include)
# 在项目中添加子目录 "ollvm",该目录下应包含项目源代码
add_subdirectory(ollvm)尤其是set那里,如果我们使用debug版本的clang+debug版本的LLVMObfuscation1.so就设置cmake-build-debug,否则就是cmake-build-release,切记不能混着用,否则执行混淆的时候会报错
export PATH=/home/whitebird/llvm-project-llvmorg-14.0.6/llvm/cmake-build-release/bin:$PATH
clang -Xclang -load -Xclang /home/whitebird/llvm/cmake-build-release/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -flegacy-pass-manager -mllvm -fla hello_clang.c -o hello_clang_tt这边得加个-flegacy-pass-manager,因为llvm14换了新的manager,使用-flegacy-pass-manager参数就是指定使用老版本的manager
我们看一下entry.cpp
#include "llvm/Transforms/Obfuscation/BogusControlFlow.h"
#include "llvm/Transforms/Obfuscation/Flattening.h"
#include "llvm/Transforms/Obfuscation/Split.h"
#include "llvm/Transforms/Obfuscation/Substitution.h"
#include "llvm/Transforms/Obfuscation/CryptoUtils.h"
#include "llvm/IR/LegacyPassManager.h"
#include "llvm/Transforms/IPO/PassManagerBuilder.h"
#include "llvm/Transforms/Utils.h"
using namespace llvm;
// Flags for obfuscation
static cl::opt<bool> Flattening("fla", cl::init(false),
cl::desc("Enable the flattening pass"));
static cl::opt<bool> BogusControlFlow("bcf", cl::init(false),
cl::desc("Enable bogus control flow"));
static cl::opt<bool> Substitution("sub", cl::init(false),
cl::desc("Enable instruction substitutions"));
static cl::opt<std::string> AesSeed("aesSeed", cl::init(""),
cl::desc("seed for the AES-CTR PRNG"));
static cl::opt<bool> Split("split", cl::init(false),
cl::desc("Enable basic block splitting"));
static llvm::RegisterStandardPasses Y(
llvm::PassManagerBuilder::EP_EarlyAsPossible,
[](const llvm::PassManagerBuilder &Builder,
llvm::legacy::PassManagerBase &PM) {
if(!AesSeed.empty()) {
if(!llvm::cryptoutils->prng_seed(AesSeed.c_str()))
exit(1);
}
PM.add(createSplitBasicBlock(Split));
PM.add(createBogus(BogusControlFlow));
if (Flattening) {
PM.add(createLowerSwitchPass());
}
PM.add(createFlattening(Flattening));
PM.add(createSubstitution(Substitution));
});使用RegisterStandardPasses进行注册
PassManagerBuilder::EP_EarlyAsPossible 会在其他优化进行之前调用我们的 pass PassManagerBuilder::EP_FullLinkTimeOptimizationLast 会在链接优化之后调用我们的 pass。
18、调试ollvm源码
我一开始编译的是release的LLVMObfuscation1.so模块配合release版本的clang进行调试发现断不下来,后来重新编译了一份debug版本的clang,才可以正常调试,原因是release版本的clang去除了符号,导致断点位置不对。
首先我们编译一个debug版本的LLVMObfuscation1.so
然后我们的clang也是debug版本的,进入llvm根目录
cmake -S llvm -B build_debug -G Ninja -DLLVM_ENABLE_PROJECTS="clang" -DCMAKE_BUILD_TYPE=Debug -DLLVM_INCLUDE_TESTS=OFF
cd build_debug/
ninja clang完整的编译很慢,所以只编译了clang,可以看到很占内存
我们设置调试参数
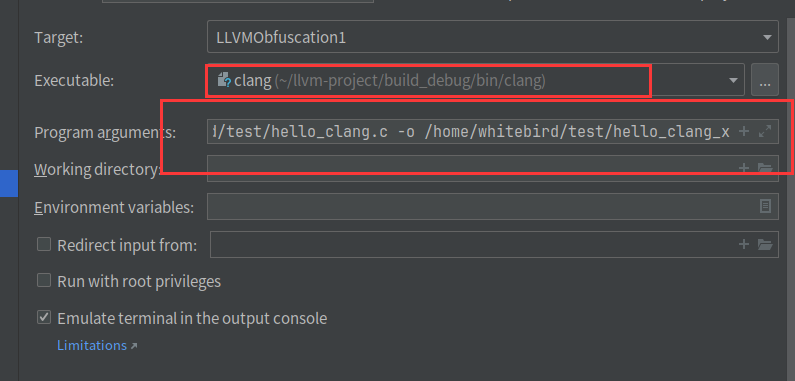
-Xclang -load -Xclang /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -flegacy-pass-manager -mllvm -fla /home/whitebird/test/hello_clang.c -o /home/whitebird/test/hello_clang_x会发现还是断不下来,但是执行了我们自己写的打印
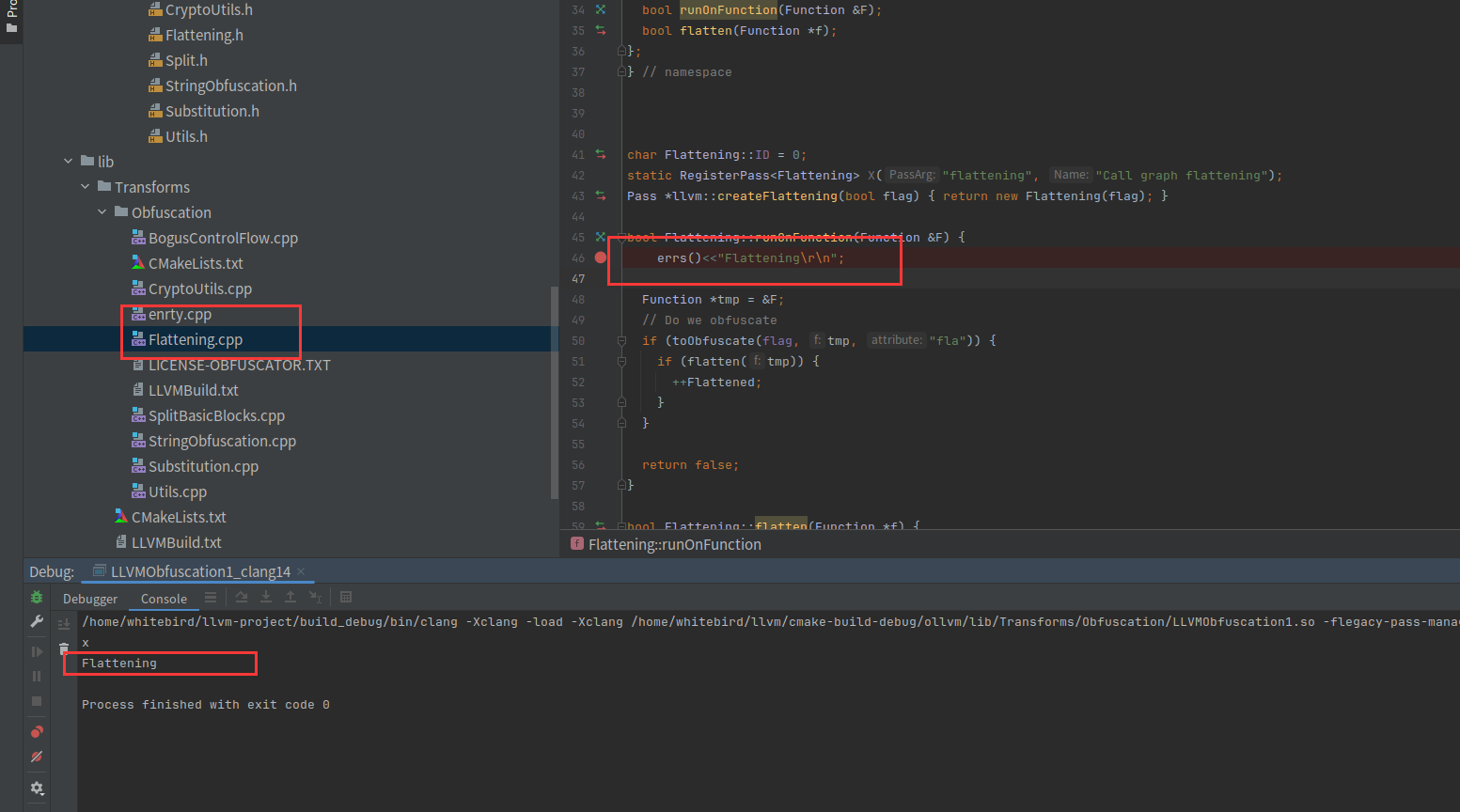
我们写个异常看看,需要重新编译模块
int *err=(int*)0;
*err=1;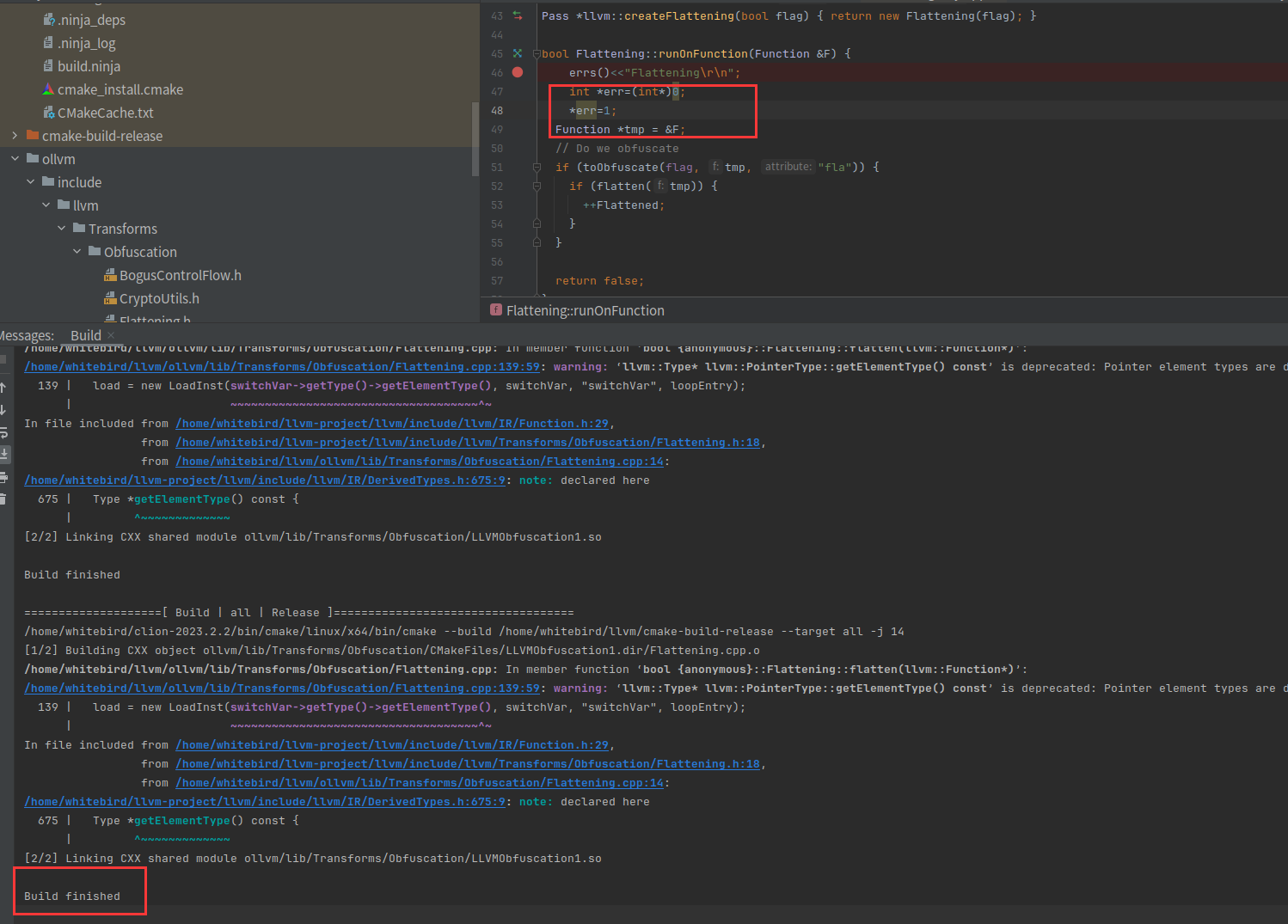
可以发现其实真正用的是clang-14,而且多了一堆参数
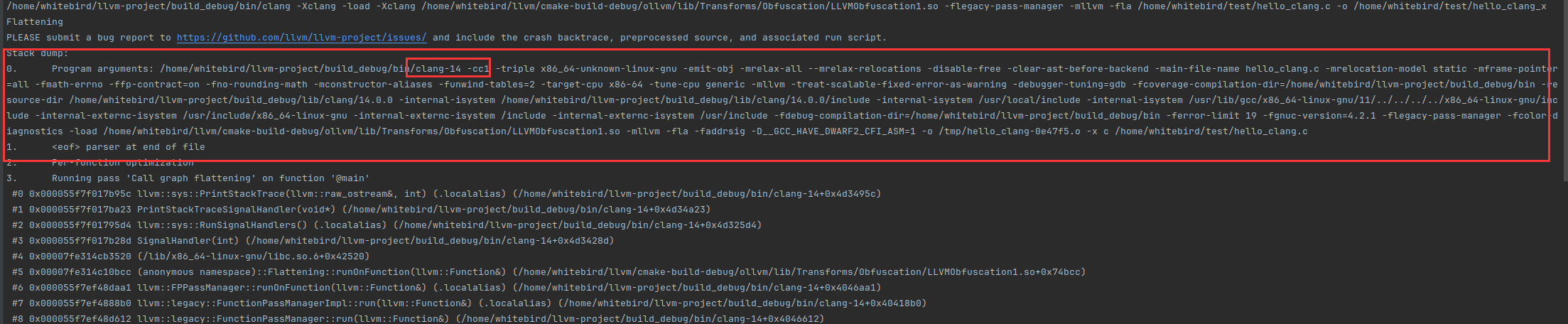
我们把这些参数改成我们自己使用
-cc1 -triple x86_64-unknown-linux-gnu -emit-obj -mrelax-all --mrelax-relocations -disable-free -clear-ast-before-backend -main-file-name hello_clang.c -mrelocation-model static -mframe-pointer=all -fmath-errno -ffp-contract=on -fno-rounding-math -mconstructor-aliases -funwind-tables=2 -target-cpu x86-64 -tune-cpu generic -mllvm -treat-scalable-fixed-error-as-warning -debugger-tuning=gdb -fcoverage-compilation-dir=/home/whitebird/llvm-project/build_debug/bin -resource-dir /home/whitebird/llvm-project/build_debug/lib/clang/14.0.0 -internal-isystem /home/whitebird/llvm-project/build_debug/lib/clang/14.0.0/include -internal-isystem /usr/local/include -internal-isystem /usr/lib/gcc/x86_64-linux-gnu/11/../../../../x86_64-linux-gnu/include -internal-externc-isystem /usr/include/x86_64-linux-gnu -internal-externc-isystem /include -internal-externc-isystem /usr/include -fdebug-compilation-dir=/home/whitebird/llvm-project/build_debug/bin -ferror-limit 19 -fgnuc-version=4.2.1 -flegacy-pass-manager -fcolor-diagnostics -load /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -mllvm -fla -faddrsig -D__GCC_HAVE_DWARF2_CFI_ASM=1 -o /tmp/hello_clang-e00a33.o -x c /home/whitebird/test/hello_ollvm.c 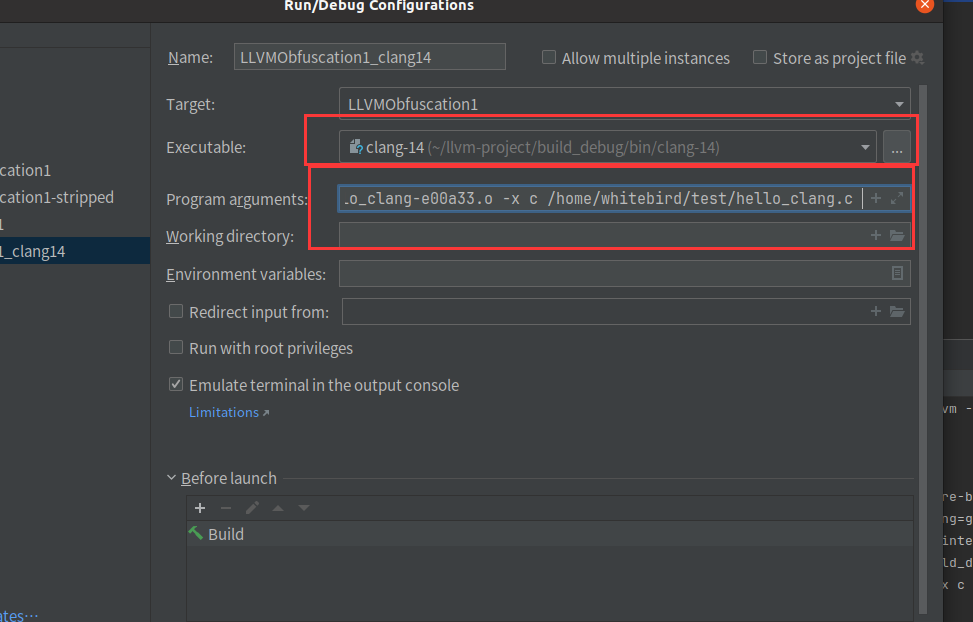
注意改成clang-14和把参数复制进去
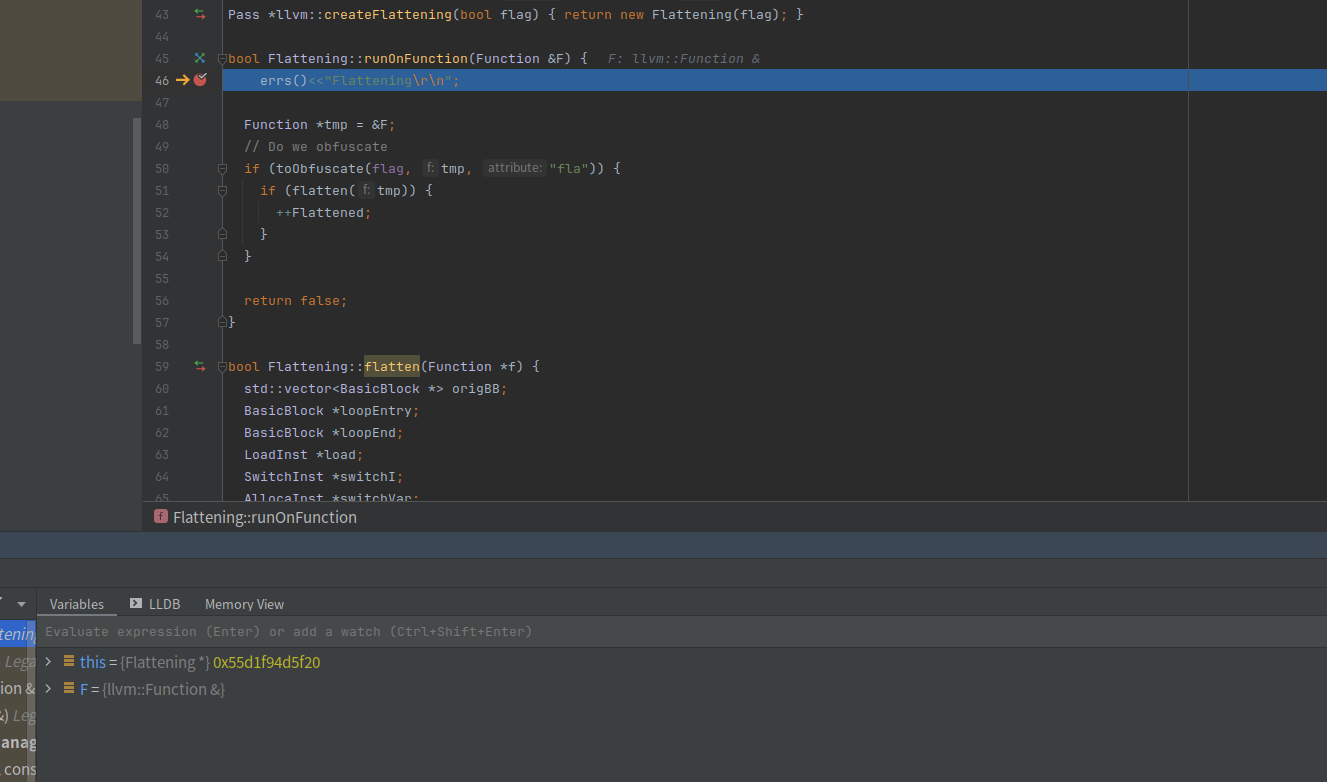
现在需要做的是删除之前的异常代码,重新编译模块。
这个时候就已经可以正常调试了
19、调试ollvm-fla源码
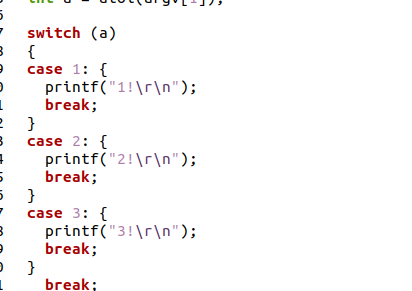
测试代码
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char** argv) {
int a = atoi(argv[1]);
switch (a)
{
case 1: {
printf("1!\r\n");
break;
}
case 2: {
printf("2!\r\n");
break;
}
case 3: {
printf("3!\r\n");
break;
}
break;
default:
break;
}
if(a == 0)
return 1;
else
return 10;
return 0;
}分别生成fla的ir和没有fla的ir
clang -emit-llvm -S -mllvm -fla hello_ollvm.c -o hello_ollvm_fla.ll
clang -emit-llvm -S hello_ollvm.c -o hello_ollvm_src.ll使用Beyond Compare查看
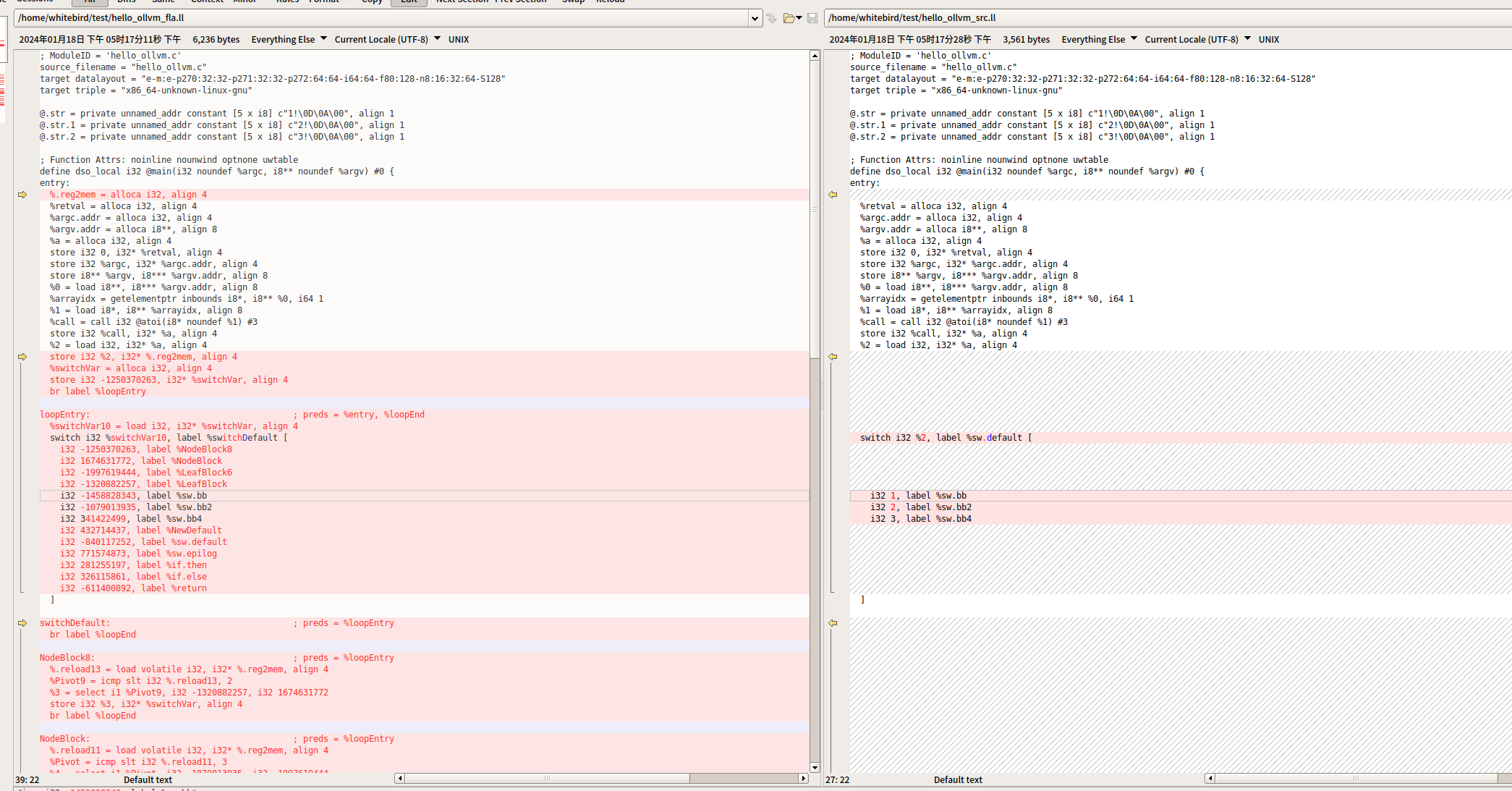
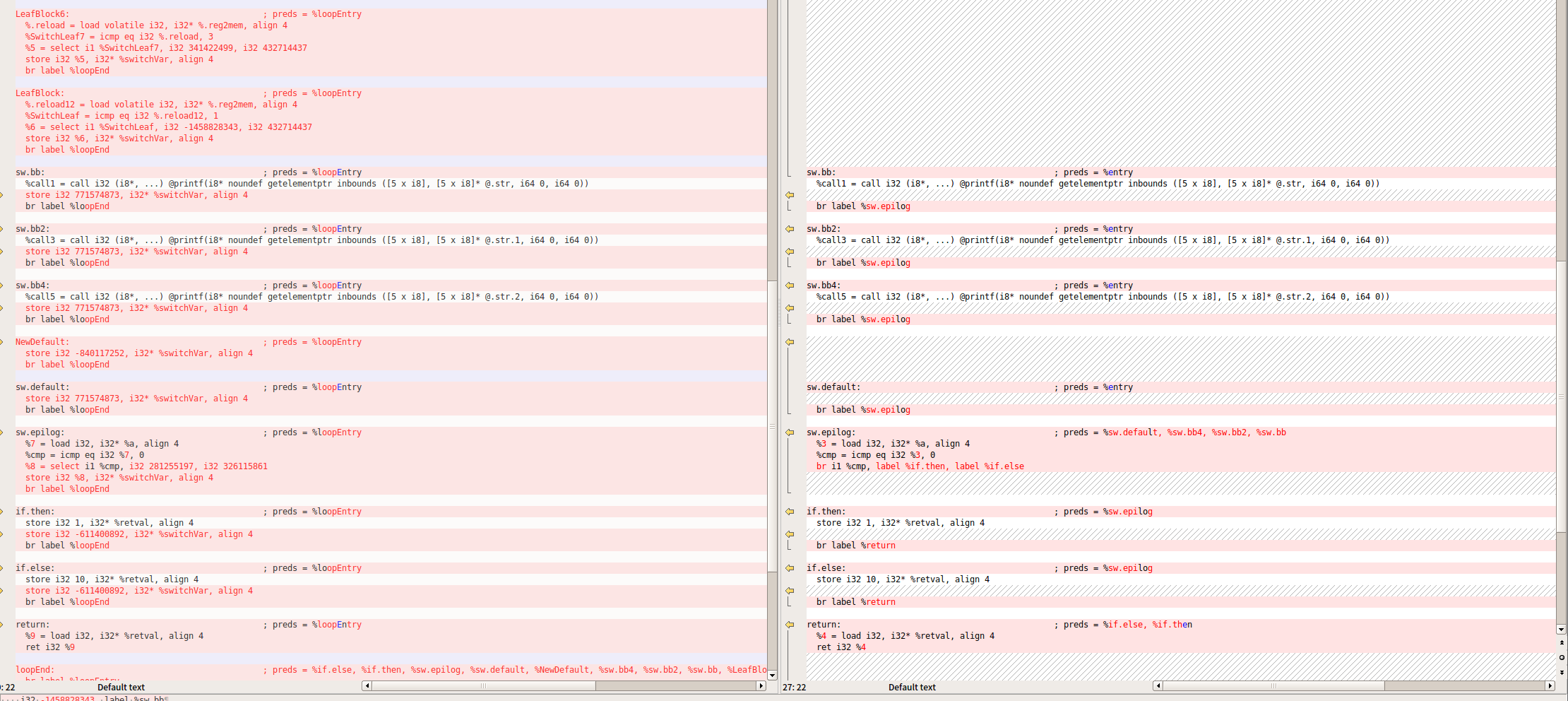
可以看到基本块是一样的
我们看一下注册pass的代码,可以发现当执行fla的时候会执行两个pass
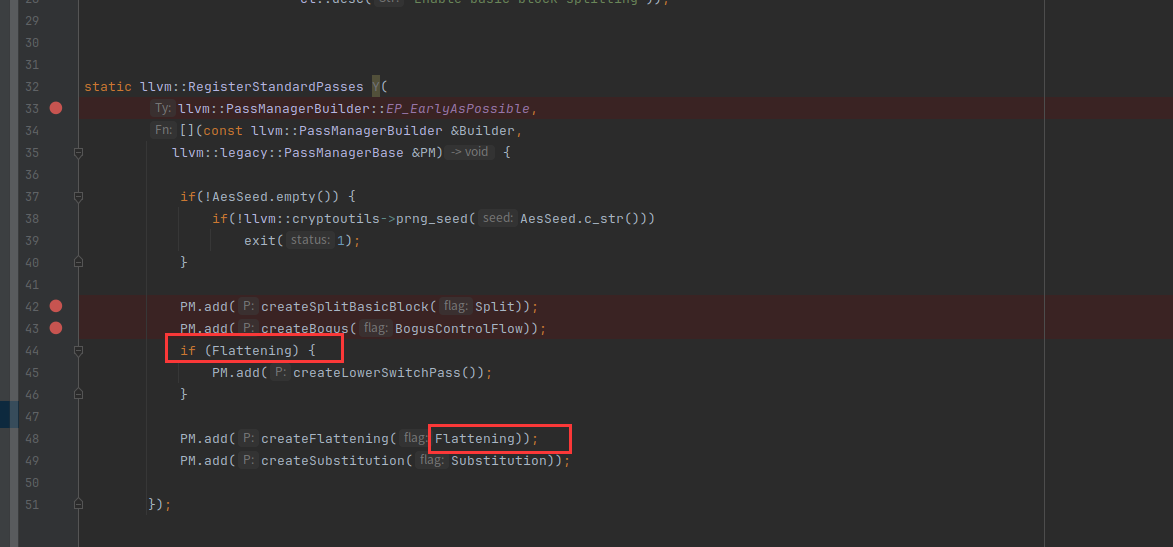
我们把 PM.add(createLowerSwitchPass())移到下面,这样不加参数就会执行createLowerSwitchPass
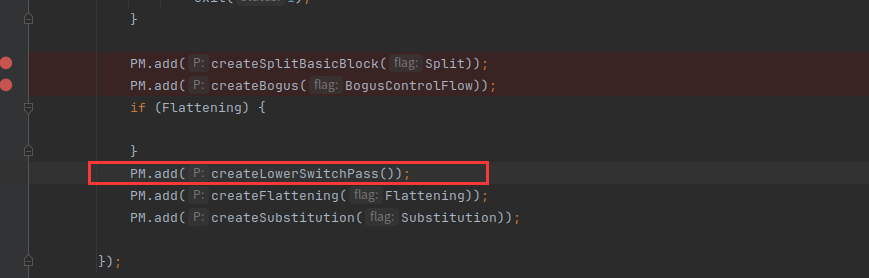
clang -emit-llvm -S hello_ollvm.c -o hello_ollvm_no_fla_switch.ll把hello_ollvm_no_fla_switch和hello_ollvm_src.ll进行比较,发现只改变了switch部分
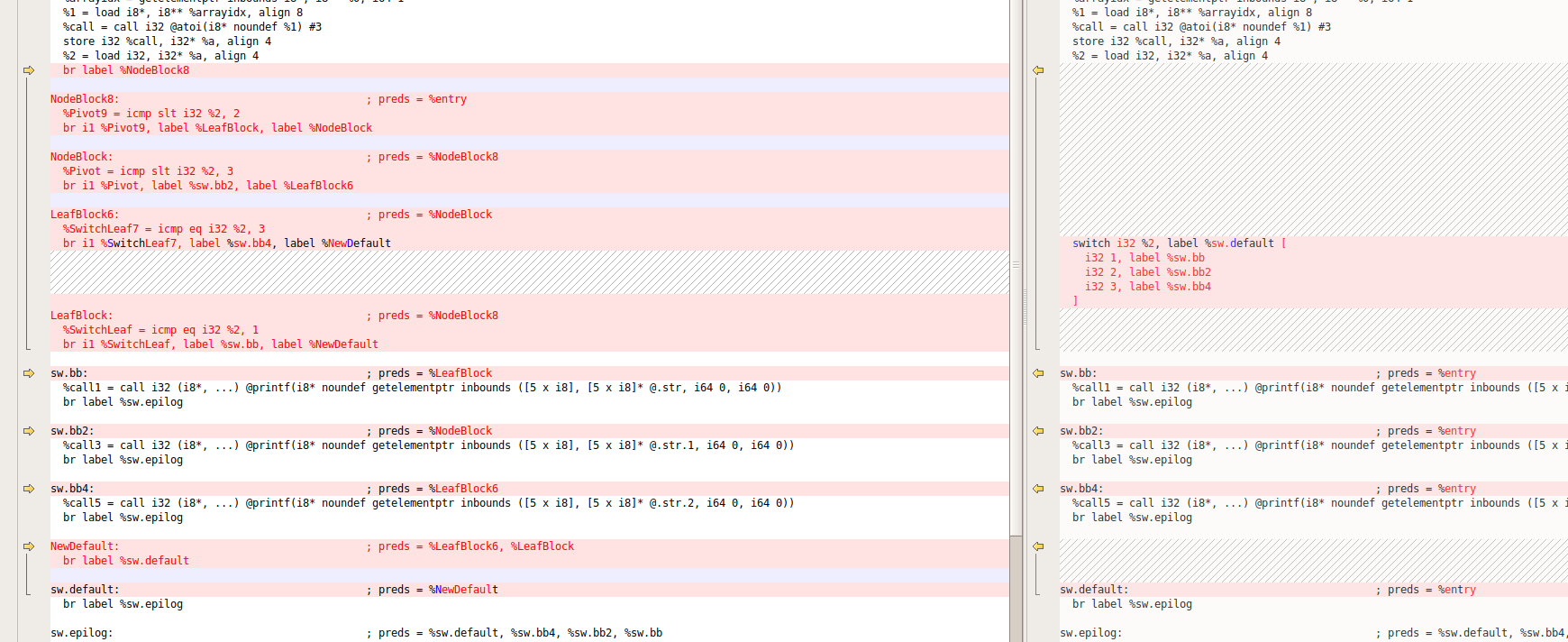
我们调试一下createLowerSwitchPass,它是把源代码中的switch转换成平坦化的操作
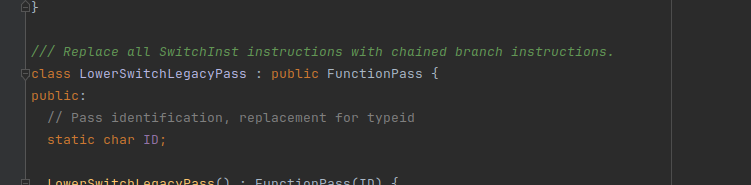
看注释的意思也是差不多的
我们在之前的项目中打开LowerSwitch.cpp,然后下断点调试
-emit-llvm -S /home/whitebird/test/hello_ollvm.c -o /home/whitebird/test/hello_ollvm_no_fla_switch.ll没有断下来,还是之前的问题,需要clang-14,直接用上一节的参数
-cc1 -triple x86_64-unknown-linux-gnu -emit-obj -mrelax-all --mrelax-relocations -disable-free -clear-ast-before-backend -main-file-name hello_clang.c -mrelocation-model static -mframe-pointer=all -fmath-errno -ffp-contract=on -fno-rounding-math -mconstructor-aliases -funwind-tables=2 -target-cpu x86-64 -tune-cpu generic -mllvm -treat-scalable-fixed-error-as-warning -debugger-tuning=gdb -fcoverage-compilation-dir=/home/whitebird/llvm-project/build_debug/bin -resource-dir /home/whitebird/llvm-project/build_debug/lib/clang/14.0.0 -internal-isystem /home/whitebird/llvm-project/build_debug/lib/clang/14.0.0/include -internal-isystem /usr/local/include -internal-isystem /usr/lib/gcc/x86_64-linux-gnu/11/../../../../x86_64-linux-gnu/include -internal-externc-isystem /usr/include/x86_64-linux-gnu -internal-externc-isystem /include -internal-externc-isystem /usr/include -fdebug-compilation-dir=/home/whitebird/llvm-project/build_debug/bin -ferror-limit 19 -fgnuc-version=4.2.1 -flegacy-pass-manager -fcolor-diagnostics -load /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -mllvm -fla -faddrsig -D__GCC_HAVE_DWARF2_CFI_ASM=1 -o /tmp/hello_clang-e00a33.o -x c /home/whitebird/test/hello_ollvm.c 一直按F9就到了这个位置
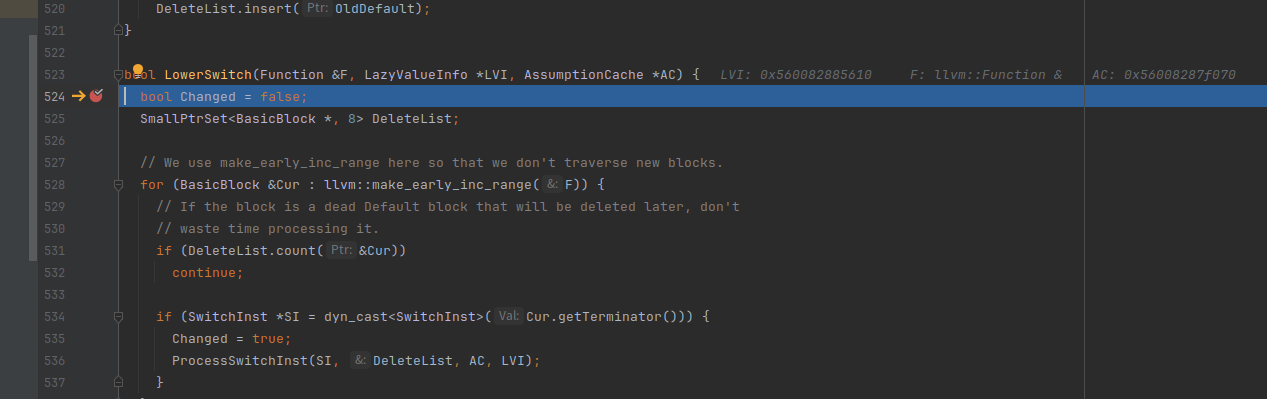
首先遍历entry,Cur代表着每个基本块
这里是对基本块最后一条指令的地方进行转换成switch指令,如果成功就进入函数体内部

ProcessSwitchInst内部就是把switch语句转换成链式的结构
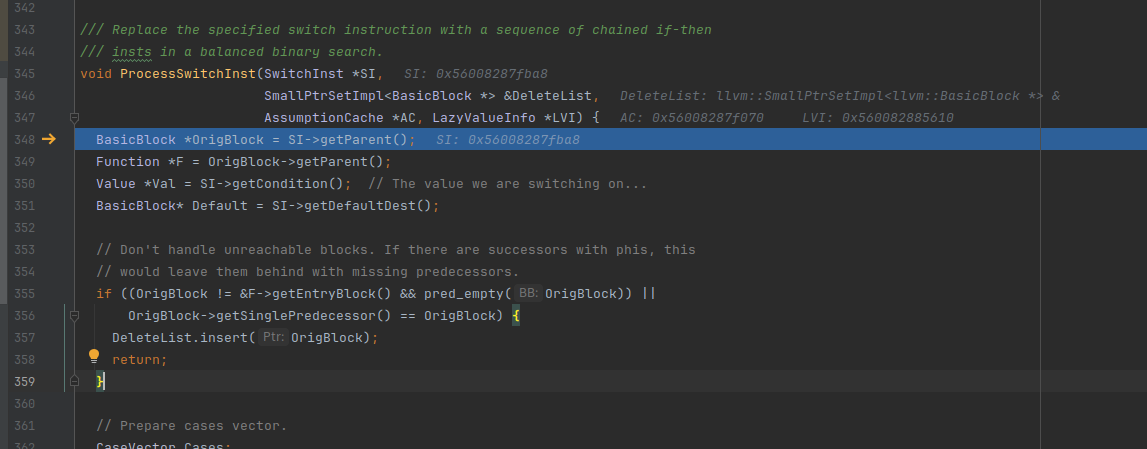
OrigBlock就是entry块
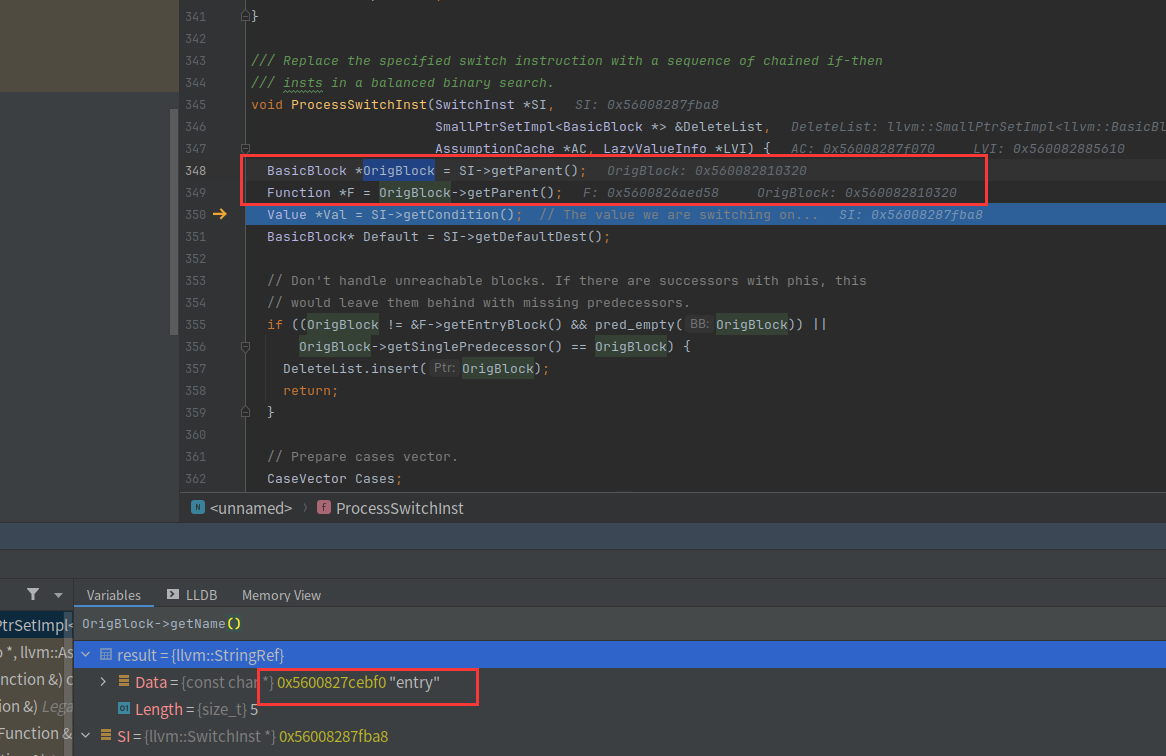
F就是main块
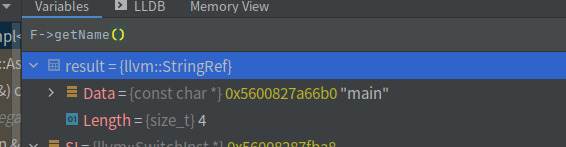
这个时候我们讲一下整个代码的结构
Module下面有很多Function,而Function下面有很多基本块,基本块是由不同种类的指令组成的,可以参考Instructions.h
Module
Function
BasicBlock
Instruction
Instruction
Instruction
Instruction
SwitchInst
BranchInst
ReturnInst
LandingPadInst
IndirectBrInst
CatchReturnInst
CatchSwitchInst
BasicBlock
BasicBlock
BasicBlock
Function
Function
Function
Function
Function
Function继续调试

在经过Clusterify后,Cases的值为3,猜测这个函数的作用是计算switch有多少个分支,我们代码中也是3个
如果case是空就返回了
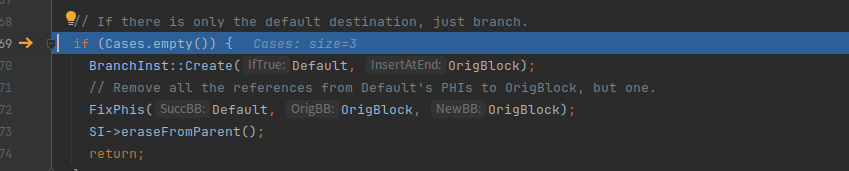
继续往下执行
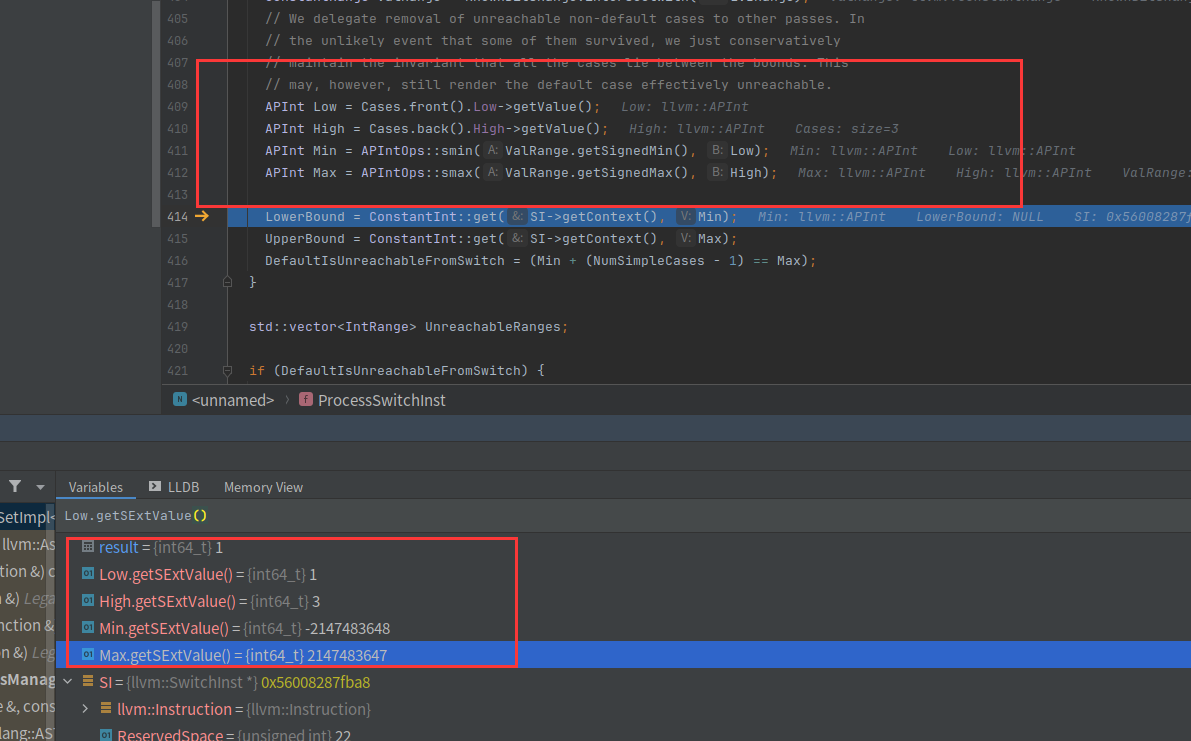
这里的Low代表着switch case里最小的值,High是最大的值
这里就是创建一个NewDefault块,然后通过 BranchInst::Create(Default, NewDefault),让NewDefault跳到sw.default:
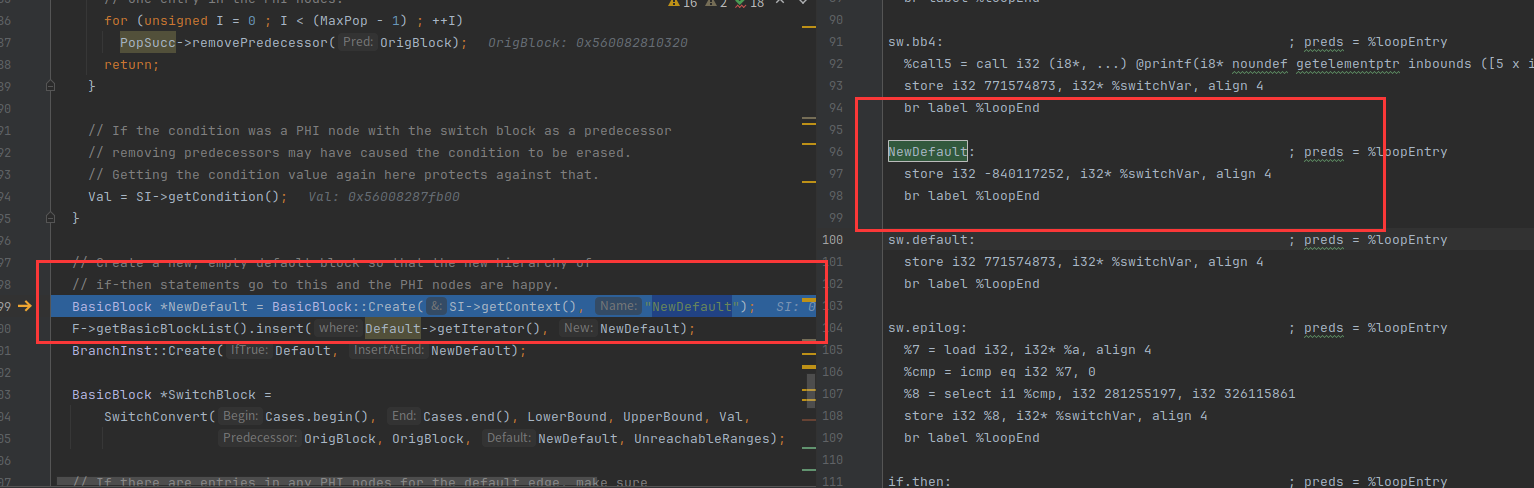
下面的函数是创建case块
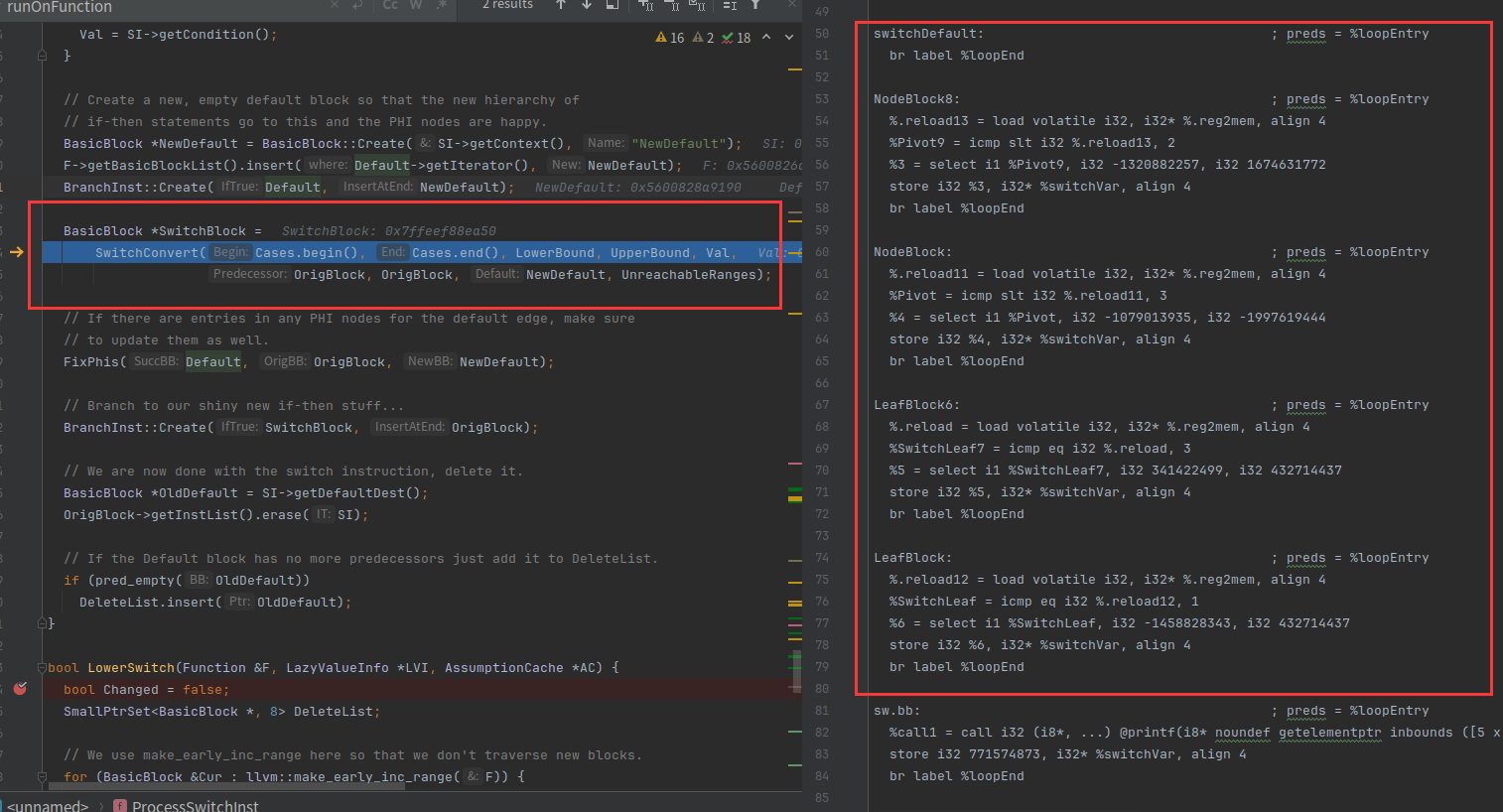
删除原来的switch case
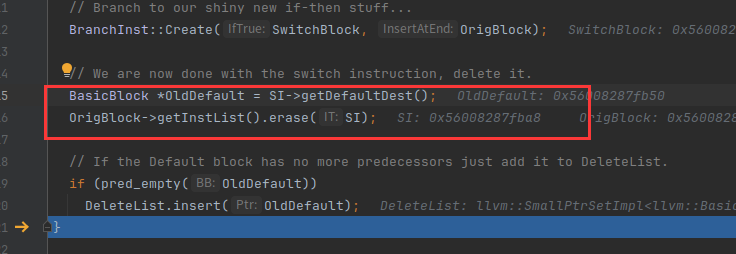
然后我们F9就跳到fla的断点处了
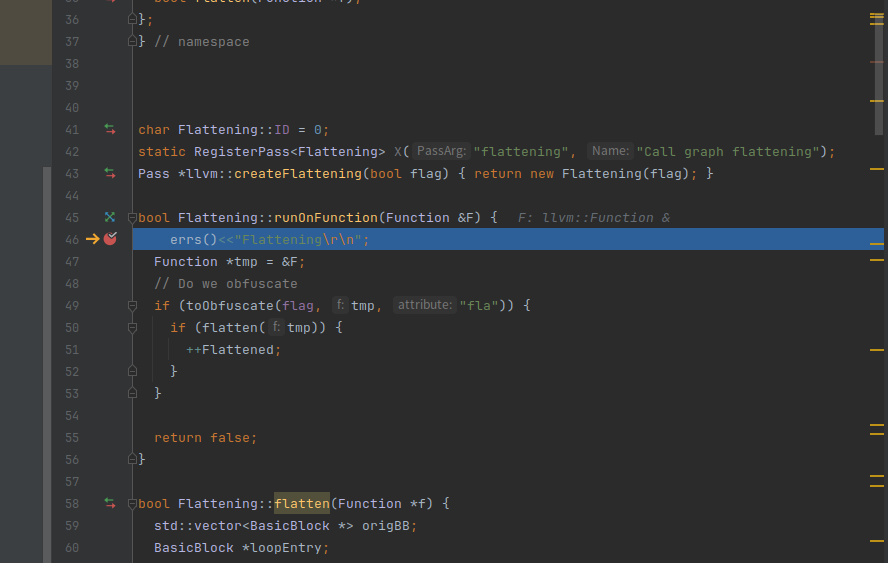
这边有个随机的key,用来生成我们控制流平坦化的case值
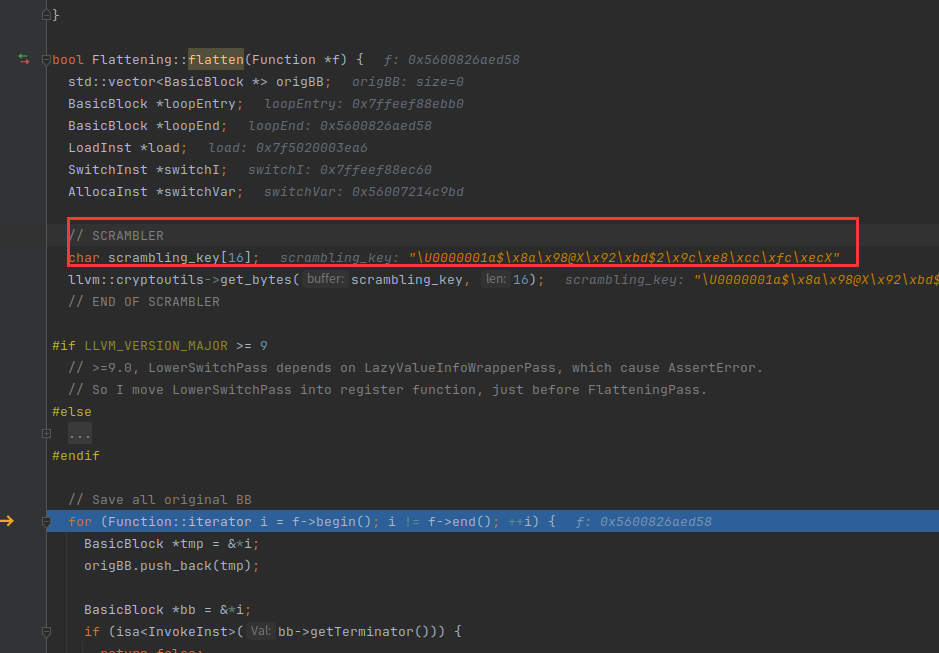
就是图中的值
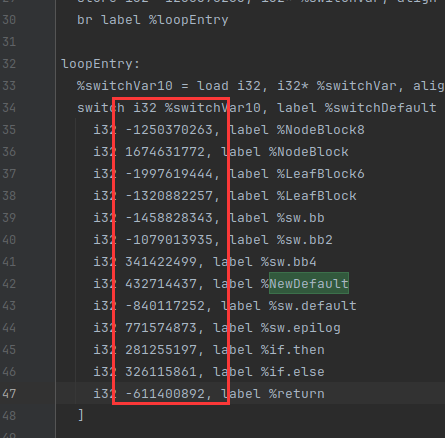
在一开始pass注册的时候,我们可以指定key,如果不指定就是随机的。当AesSeed固定后,平坦化中的case值也会固定
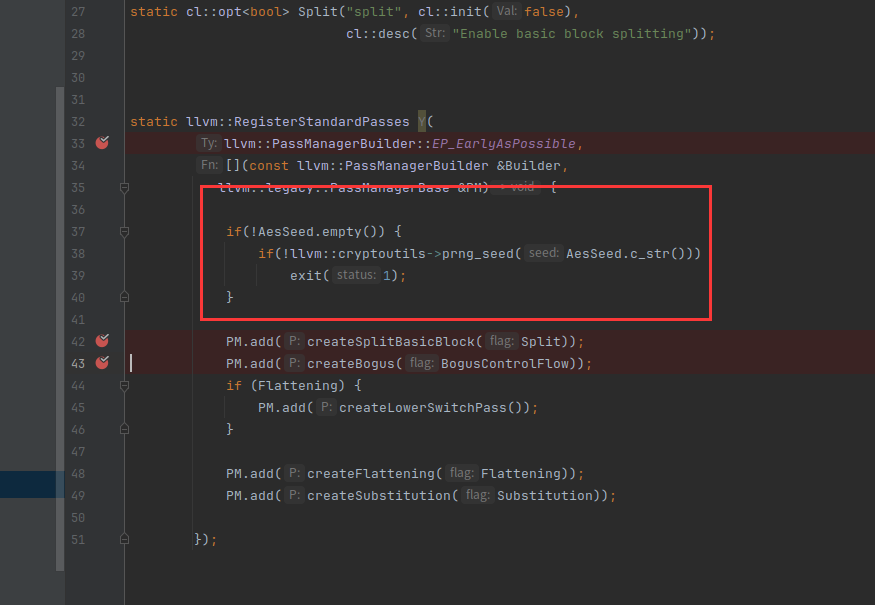
设置AesSeed
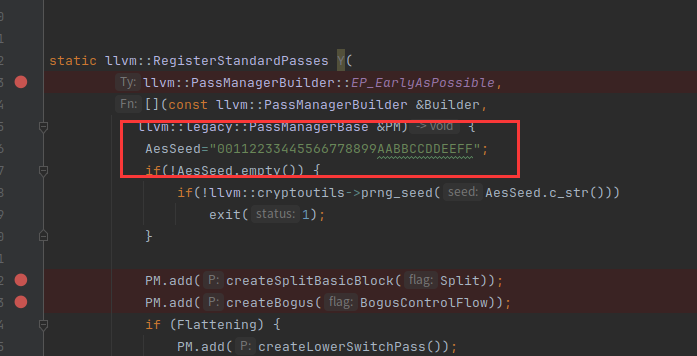
两次生成的结果是一样的
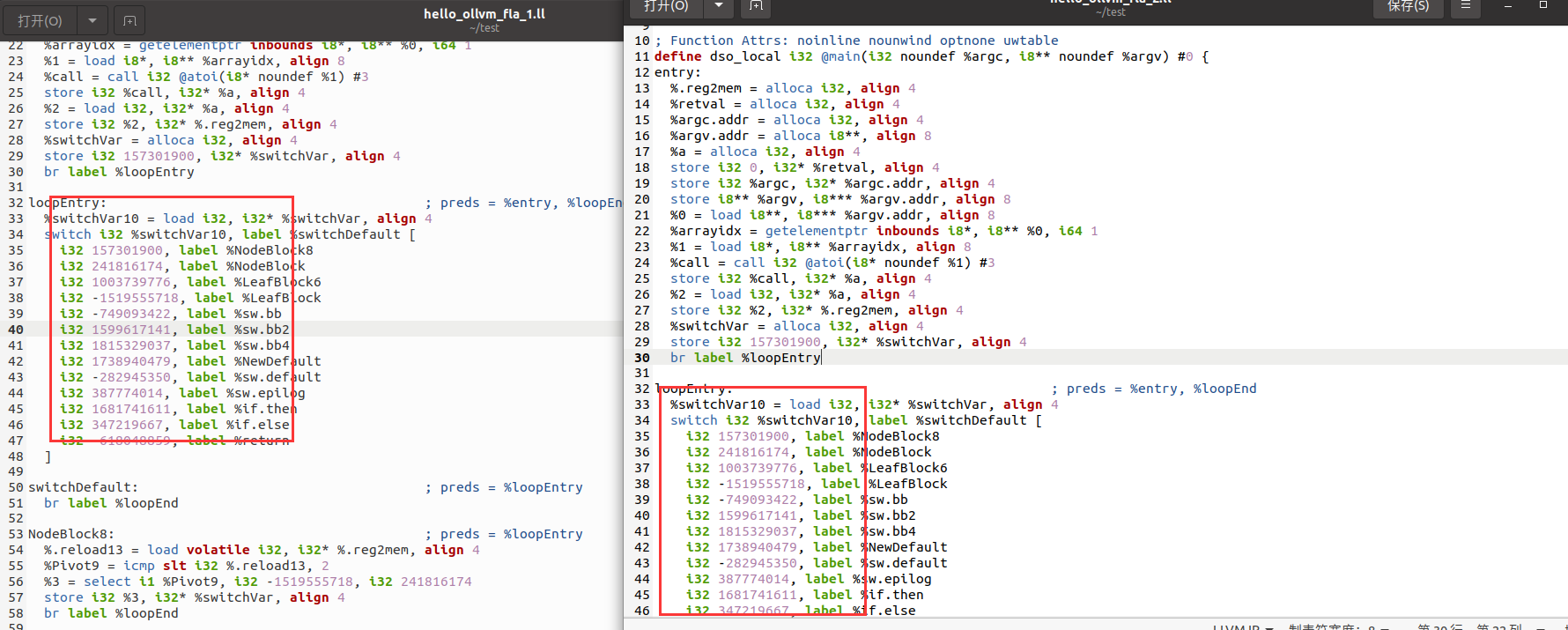
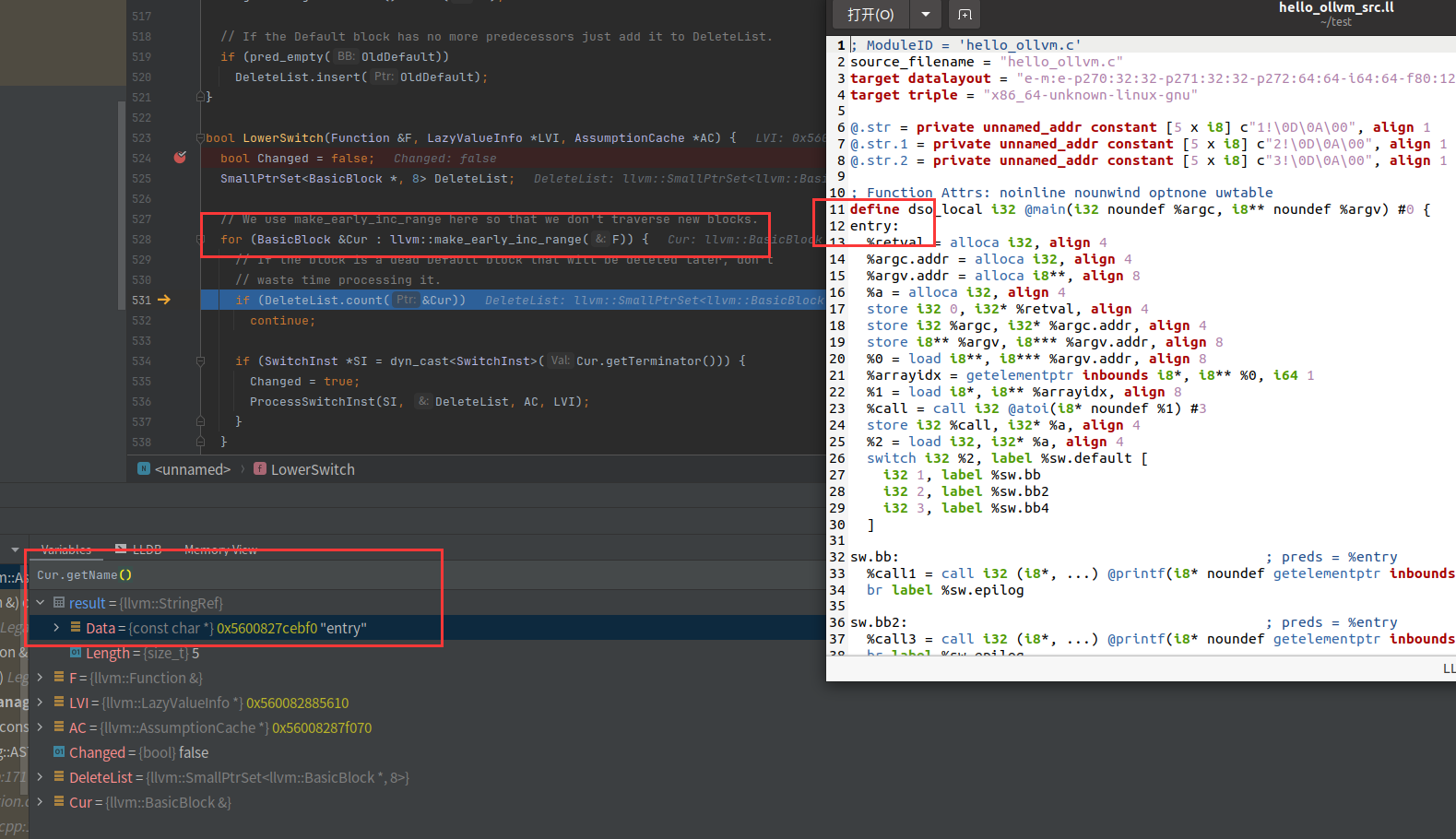
遍历出14个基本块,这个时候遍历的ir是经过createLowerSwitchPass的
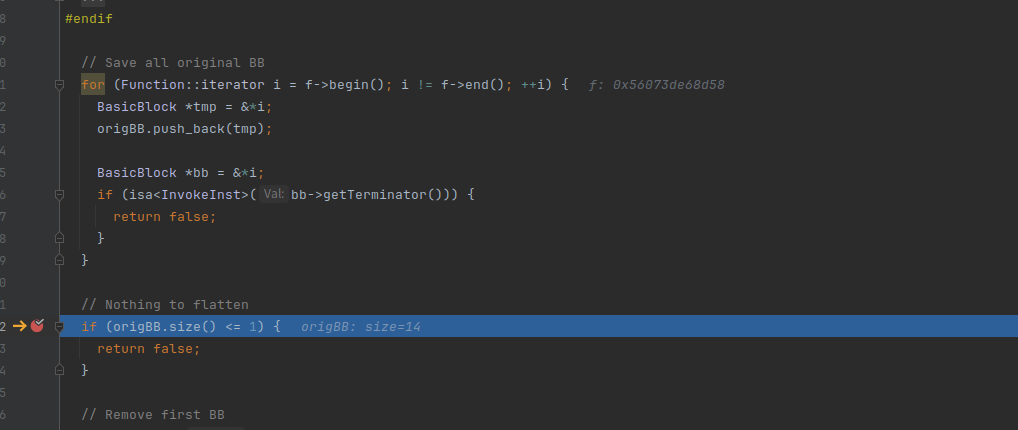
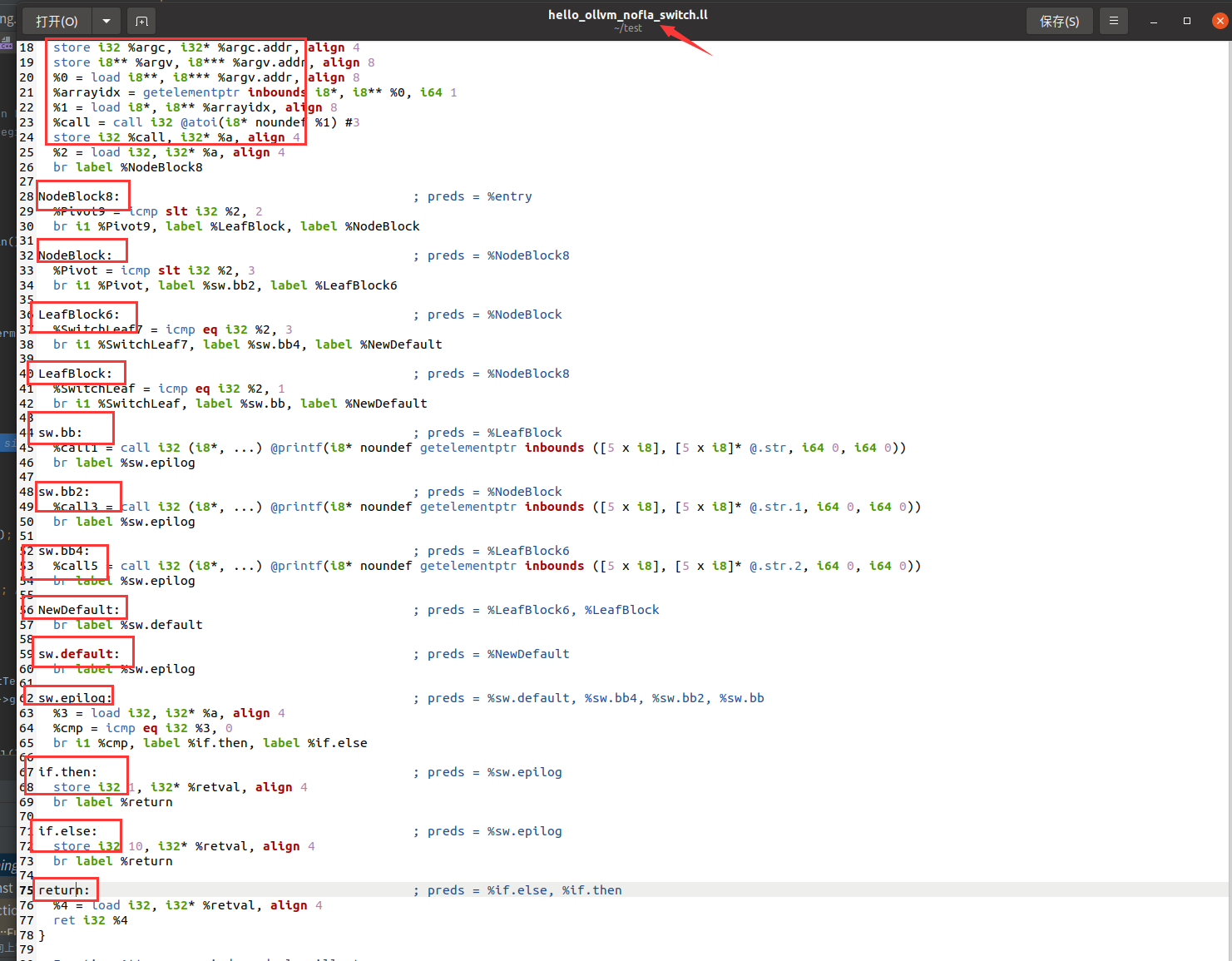
origBB.erase(origBB.begin())是把entry块从vector中删了
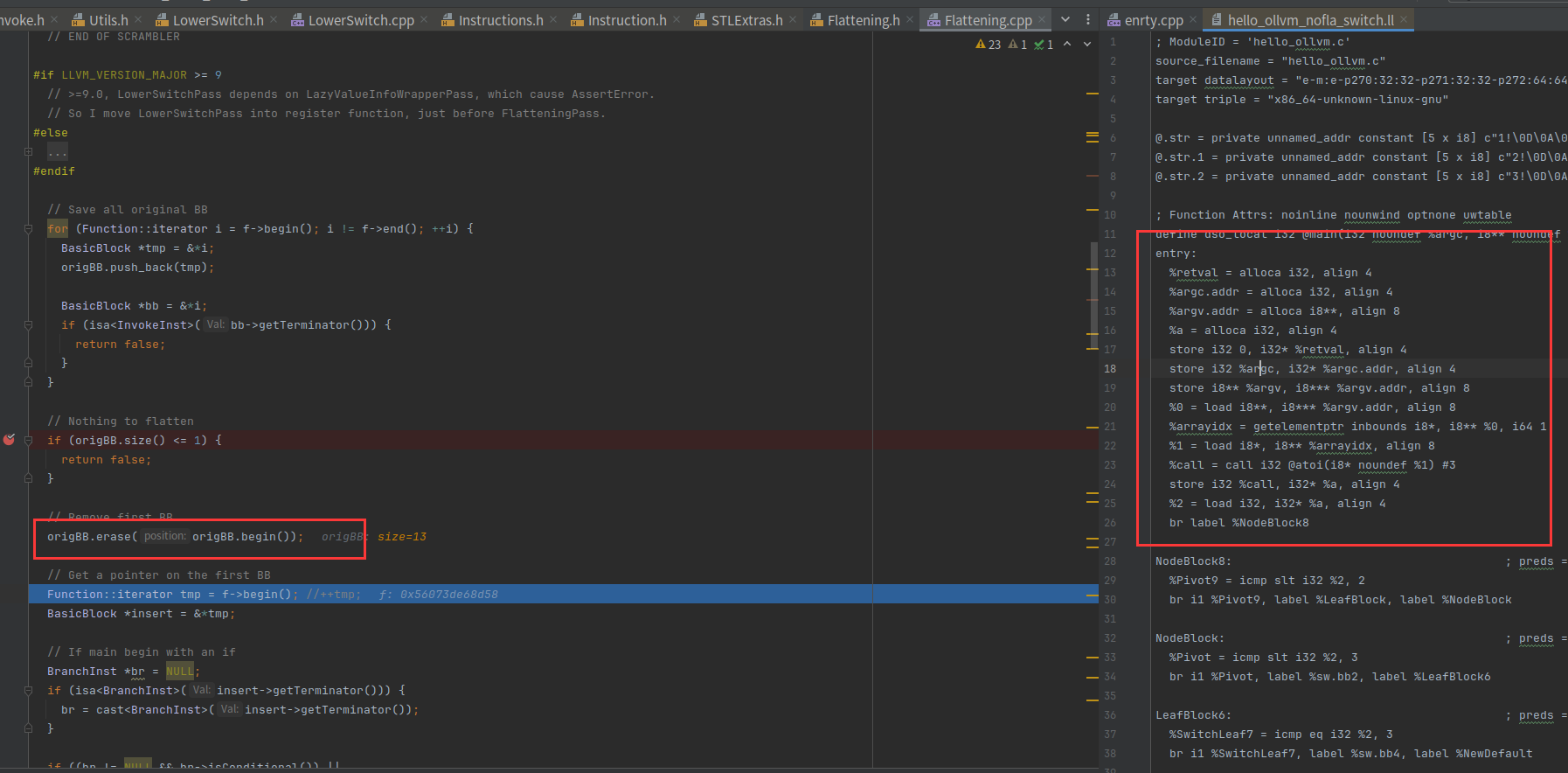
又获取了一次entry块,然后判断最后一行是否是跳转指令
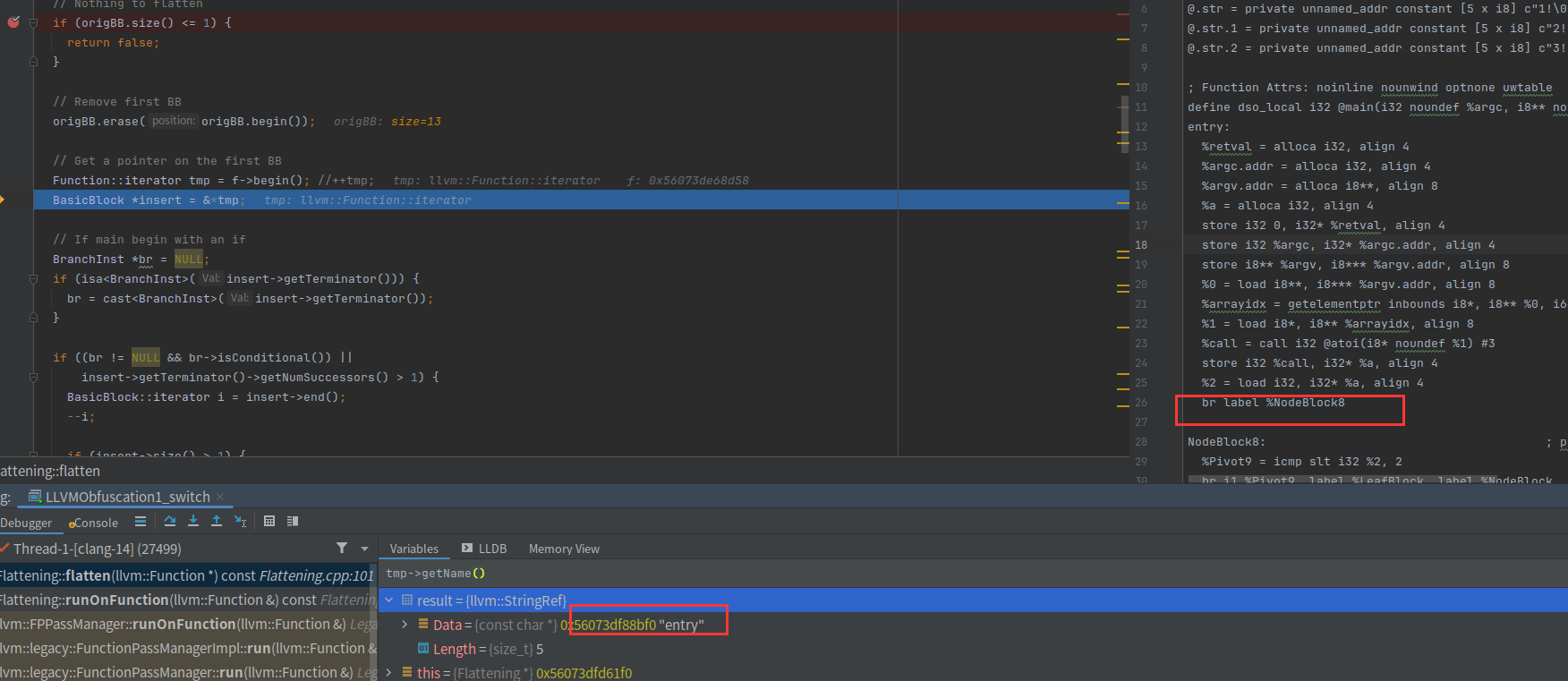
直接跳出判断,因为这里就一个分支,也就是无条件跳转
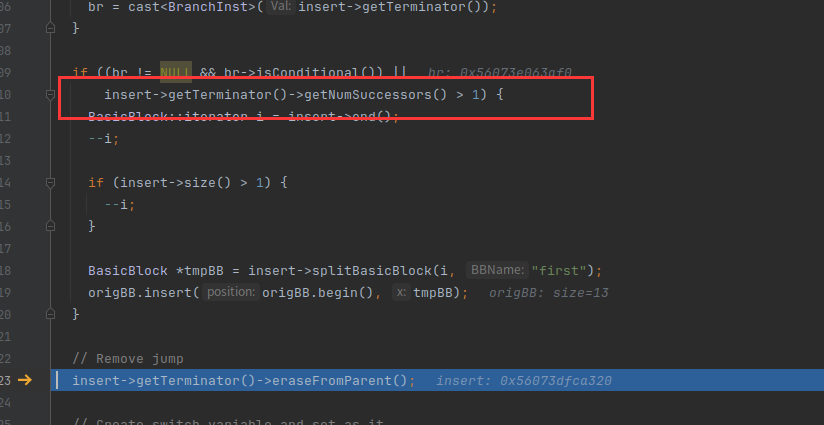
把最后一行的跳转语句删了,创建了switchVar指令
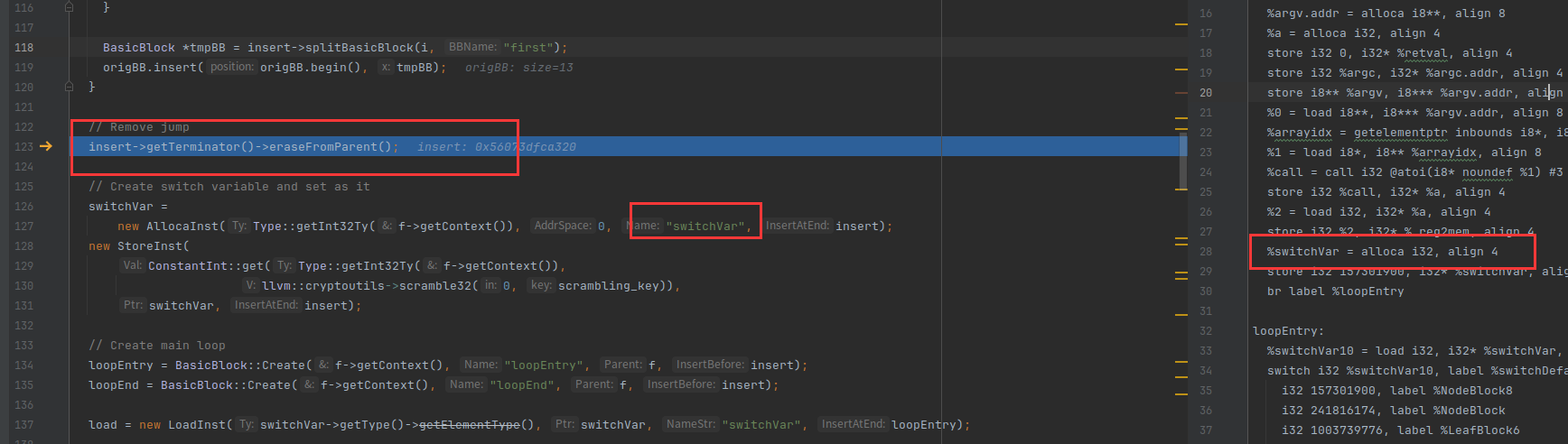
获取一个随机的整数,因为我们的key是固定了,所以这里获取的值也是固定的。创建了语句:把数字存到switchVar
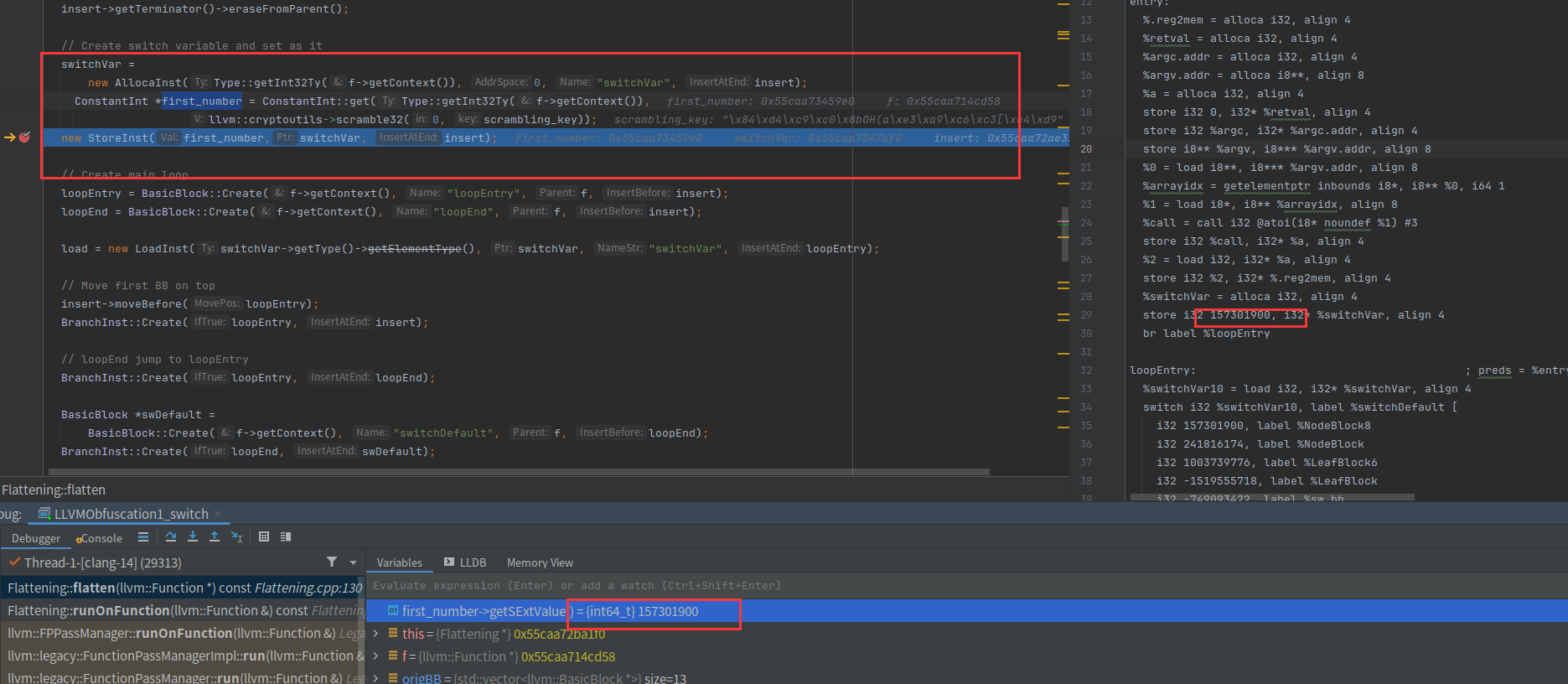
创建loopEntry和loopEnd
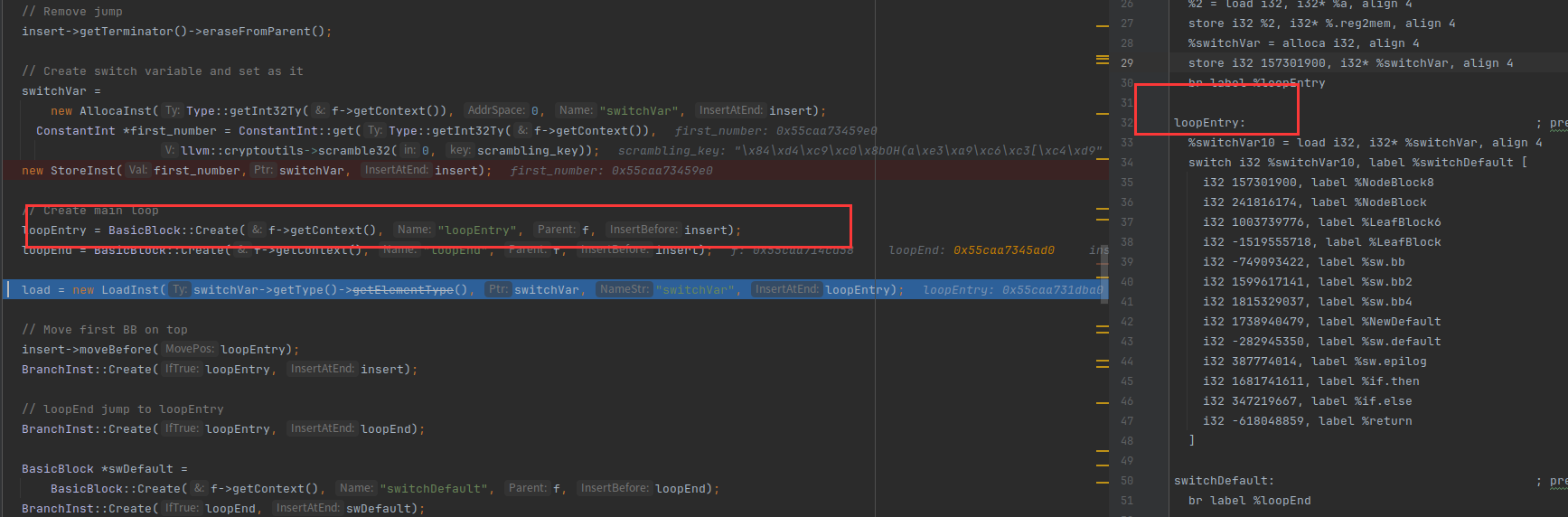

在loopEntry中生成一条指令:把switchVar的值赋给switchVar
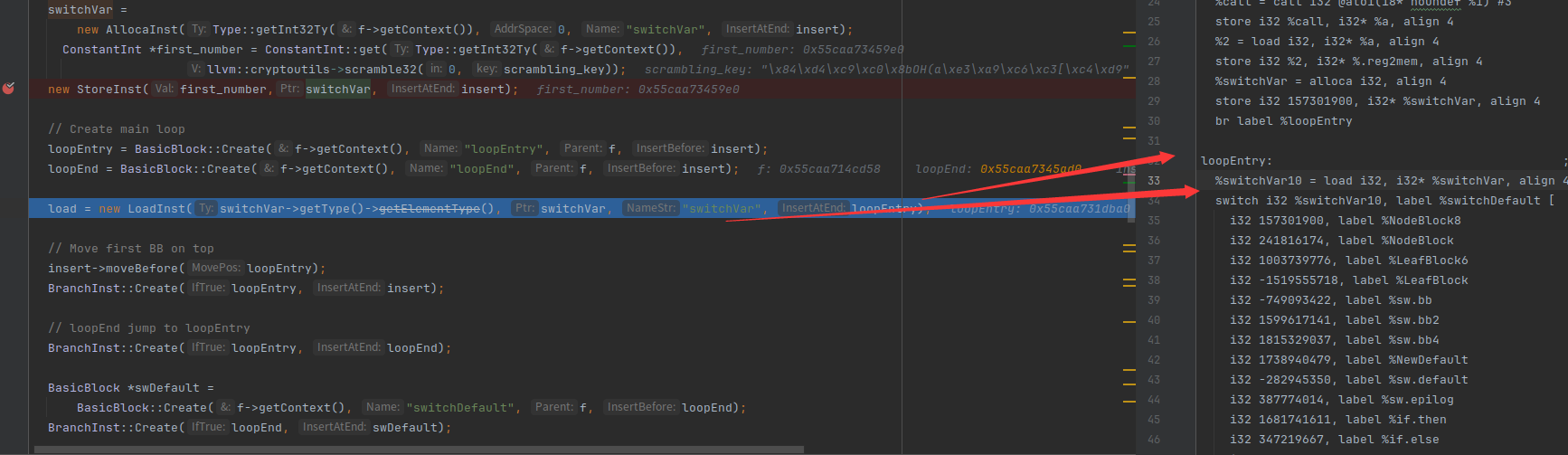
把loopEntry移动到第一个,然后在entry插入一条指令:跳转到loopEntry
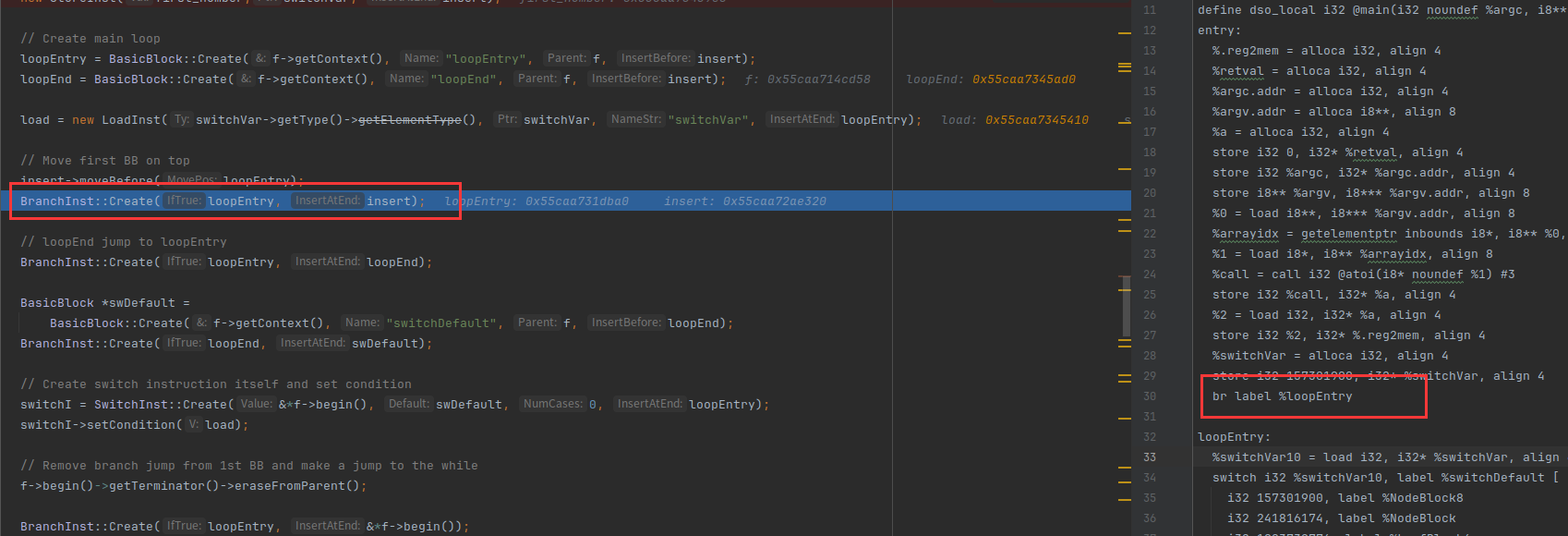
在loopEnd创建一条跳转指令:跳转到loopEntry

创建一个switchDefault,里面创建一条指令:跳转到loopEnd

在loopEntry创建一个switch指令,此时还是0个case,此时的f->begin指向loopEntry

删除跳转指令,然后创建一个跳转到loopEntry
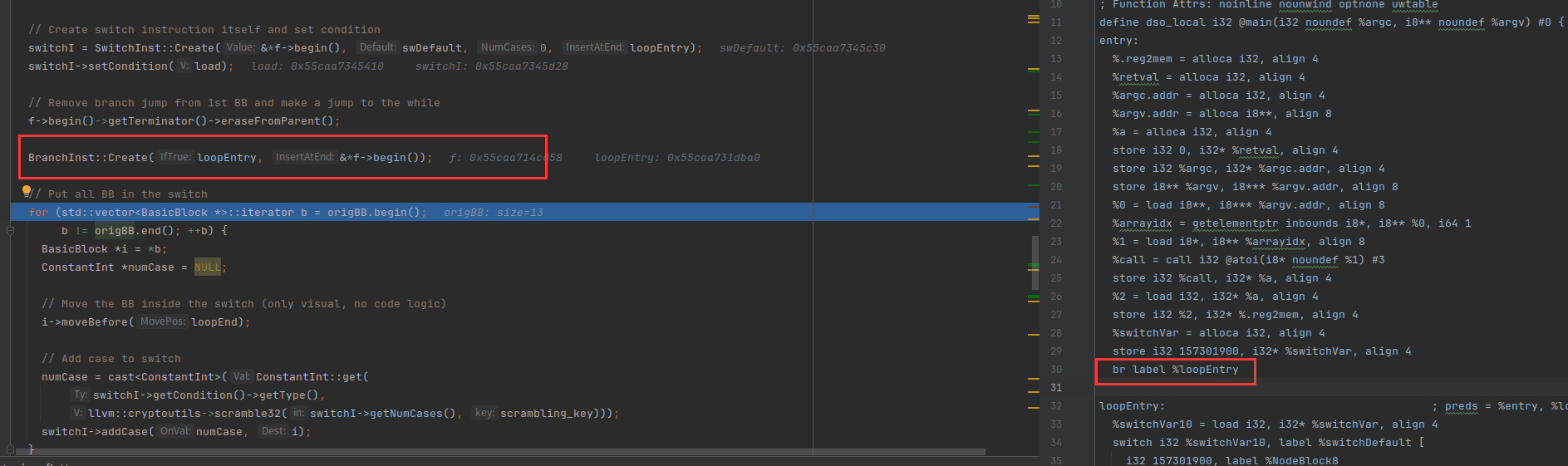
下面的属于重点,遍历所有的基础块,然后放到switch中,因为上面我们创建了一个switch,但是还没有case
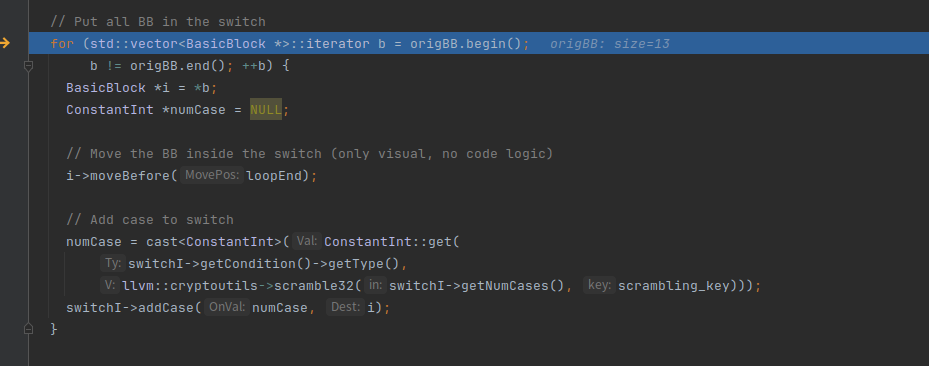
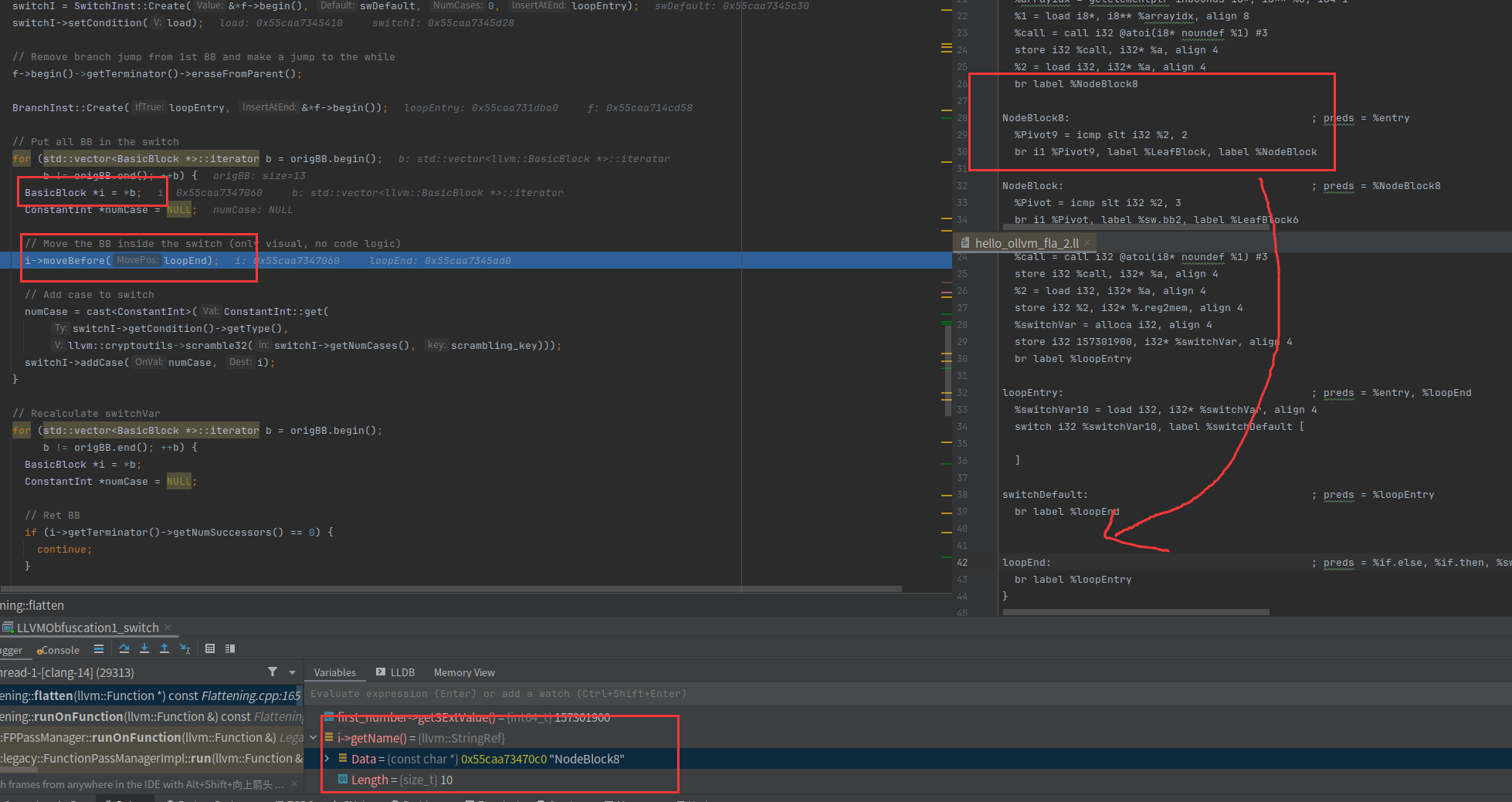
可以看到第一个i是NodeBlock8,也就是我们正常ir的除了entry的第一个基本块
i->moveBefore(loopEnd)就是把NodeBlock8添加到了loopEnd前面,其实就是尾插
设置case的值
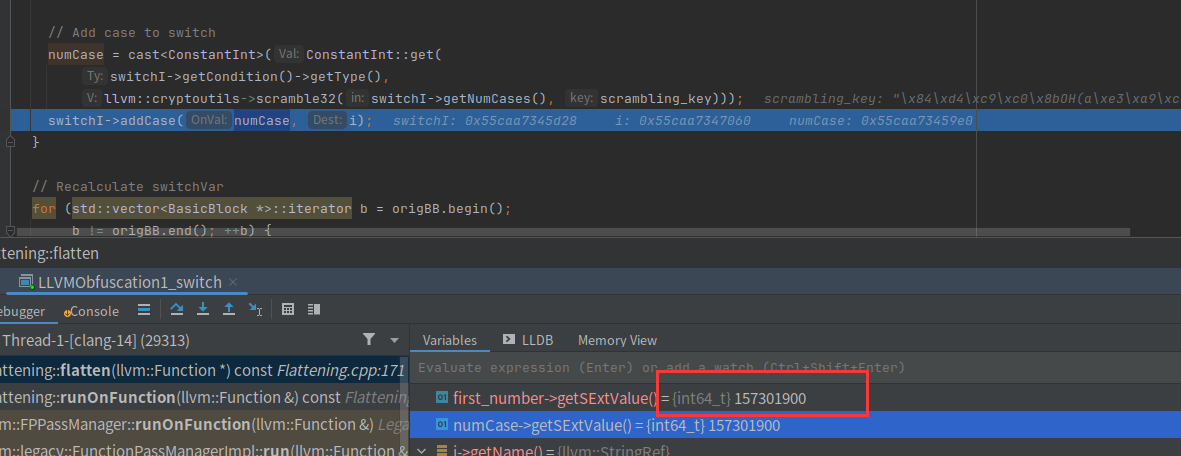
和我们最终的得到的switch case结果一致
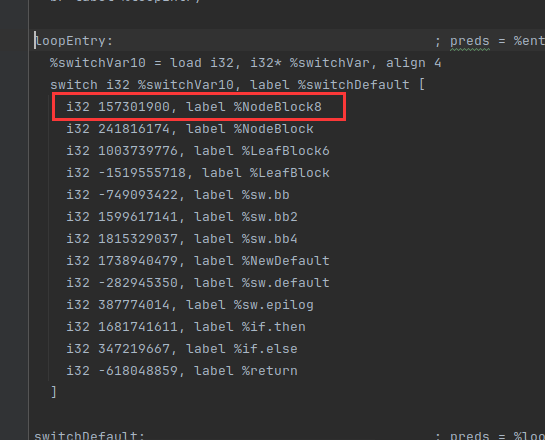
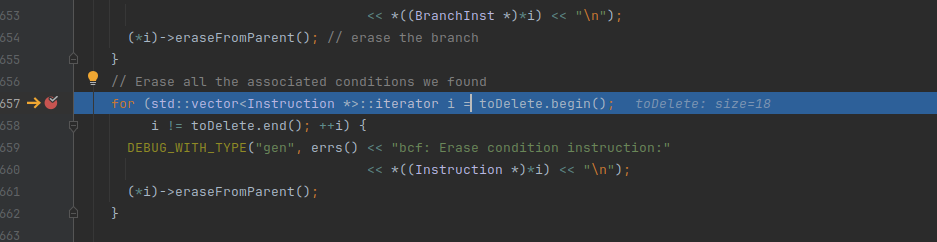
跳出这个循环,就是调整原有基本块与后继块的跳转
第一种情况,没有跳转分支了,就只有return指令了

等于1代表非条件跳转,等于2代表条件跳转
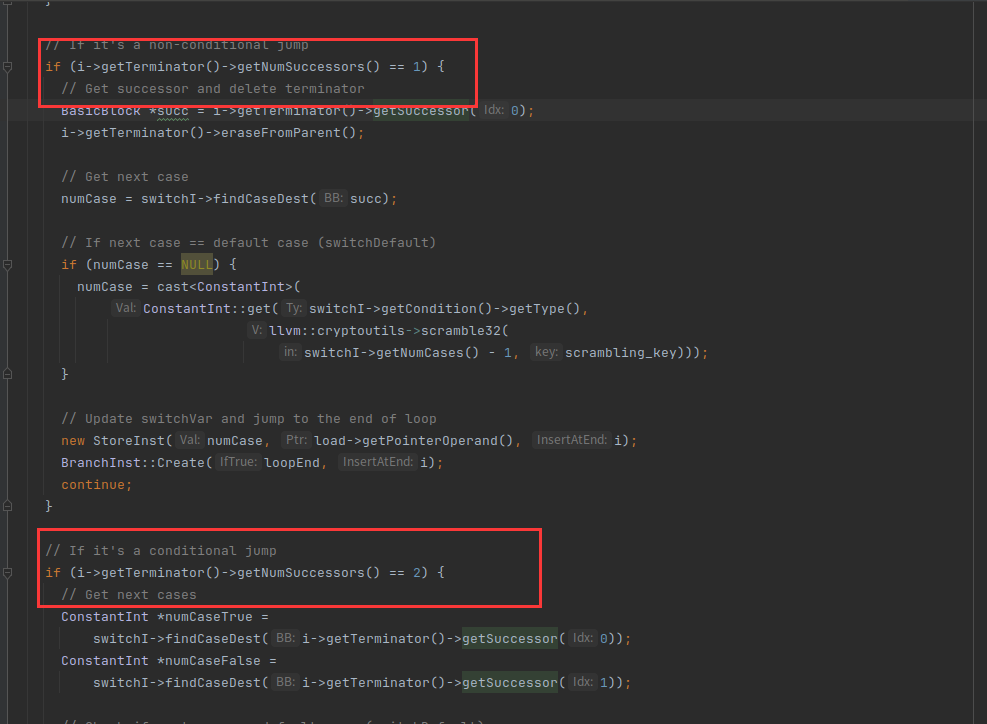
此时第一个要分析的就是NodeBlock8,它有两个分支
首先创建两个两个数numCaseTrue和numCaseFalse,对应的结果如图
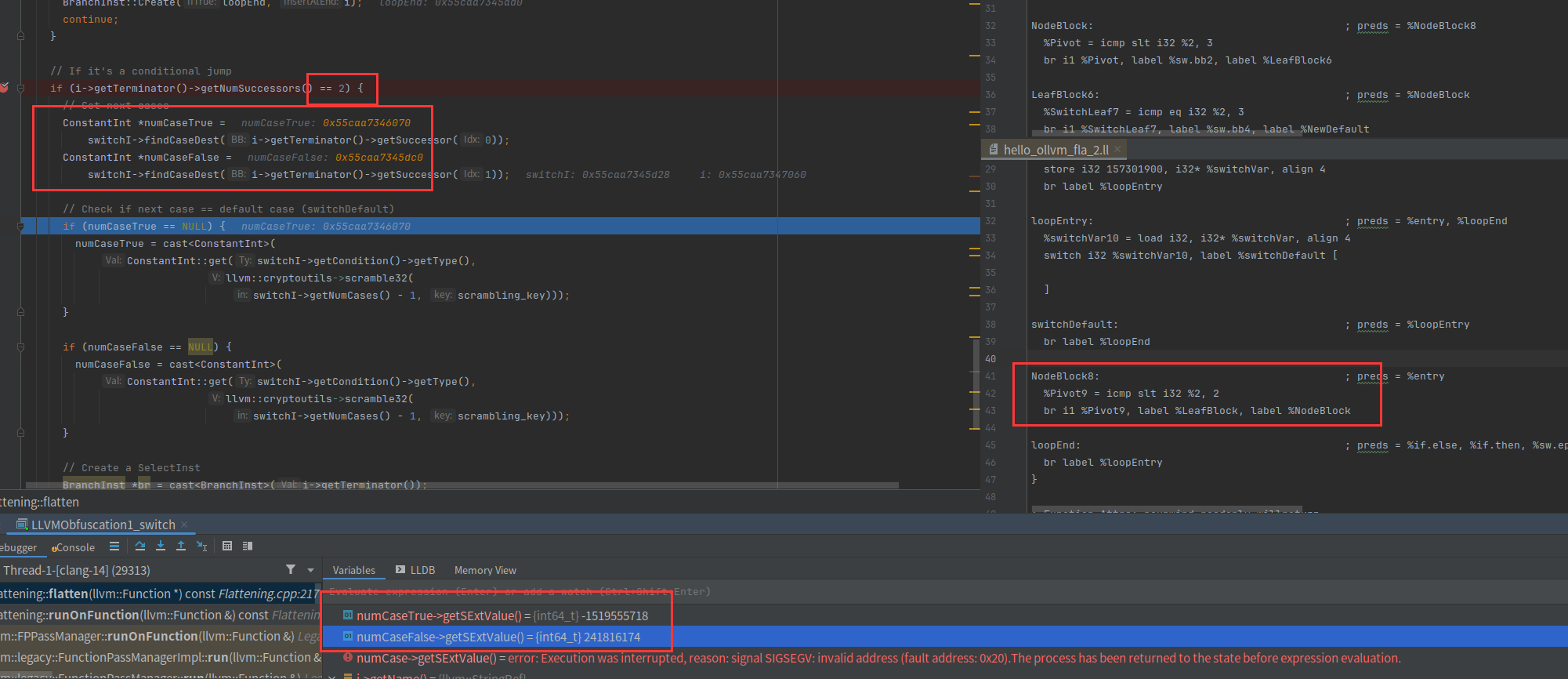
可以看到两个数分别代表两个case
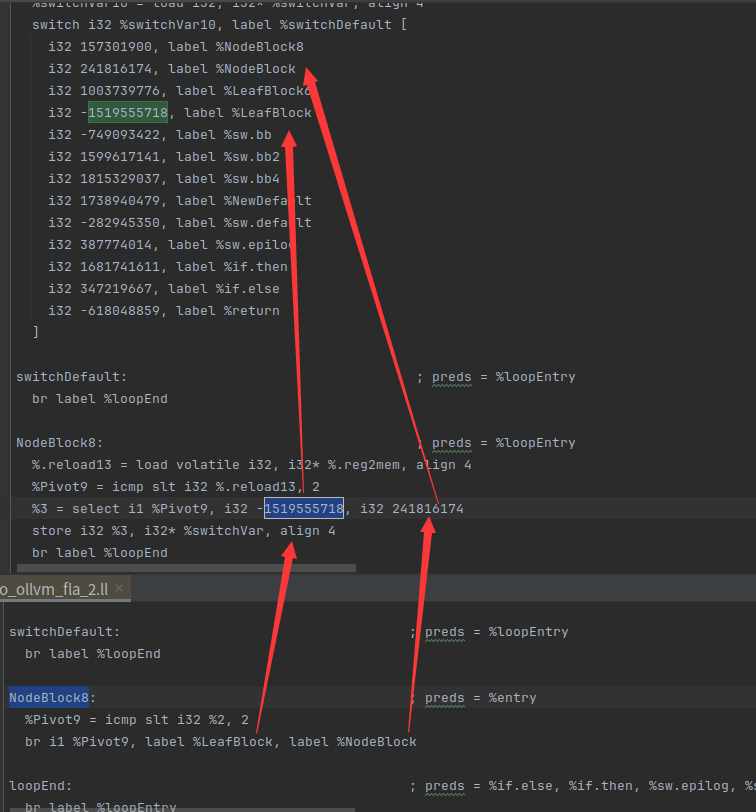
然后判断是否有一个值是空的,如果是空的代表要走默认分支
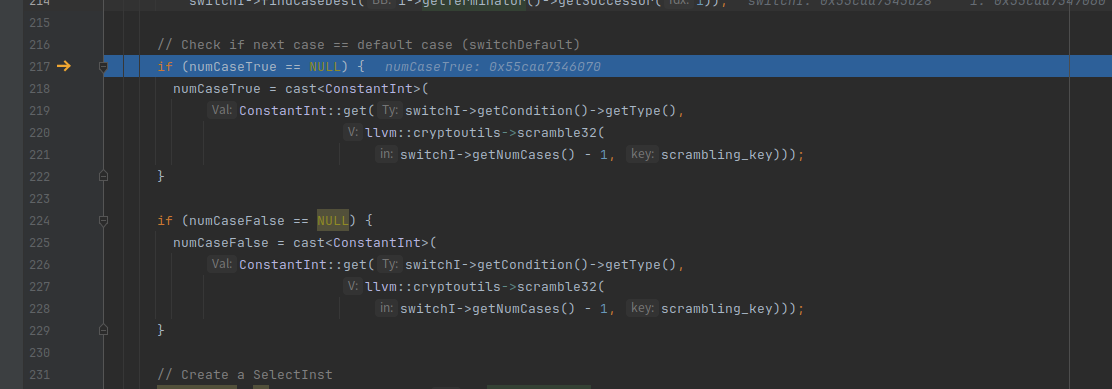
通过 br i1 %Pivot9, label %LeafBlock, label %NodeBlock创建一个SelectInst
%3 = select i1 %Pivot9, i32 -1519555718, i32 241816174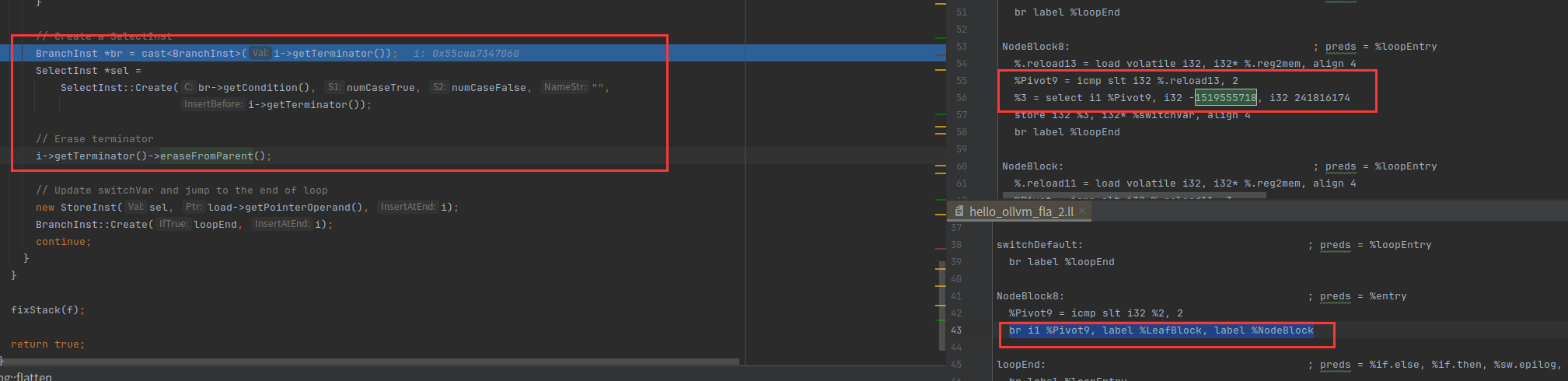
然后把br i1 %Pivot9, label %LeafBlock, label %NodeBlock删了
把sel的结果存起来,然后创建一个跳转分支:跳转到loopEnd
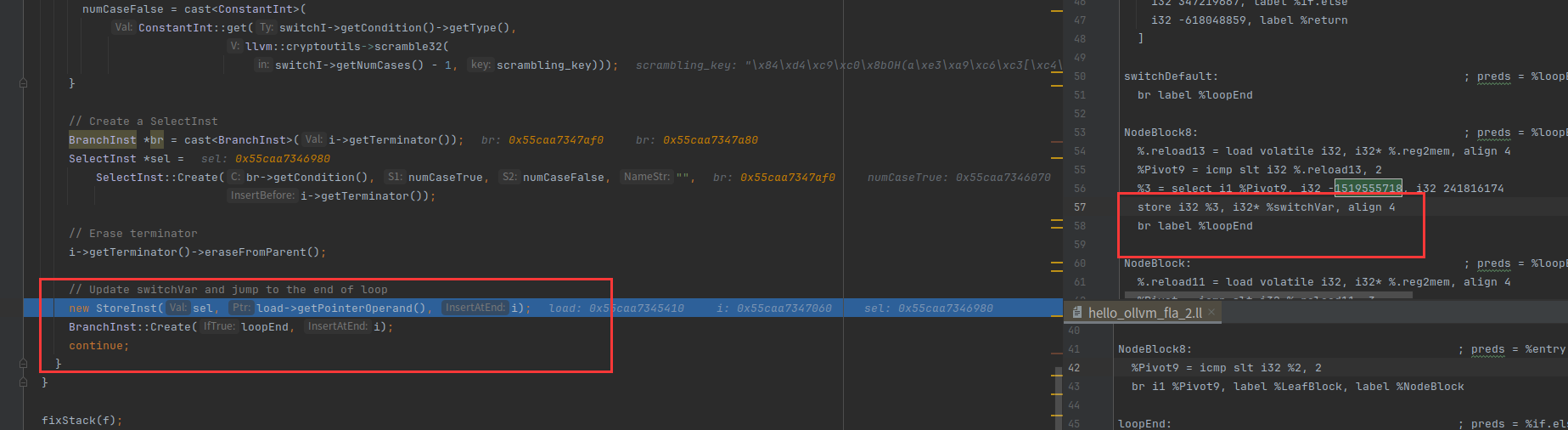
我们继续调分支等于1的情况,可以看到sw.bb只有一个无条件跳转
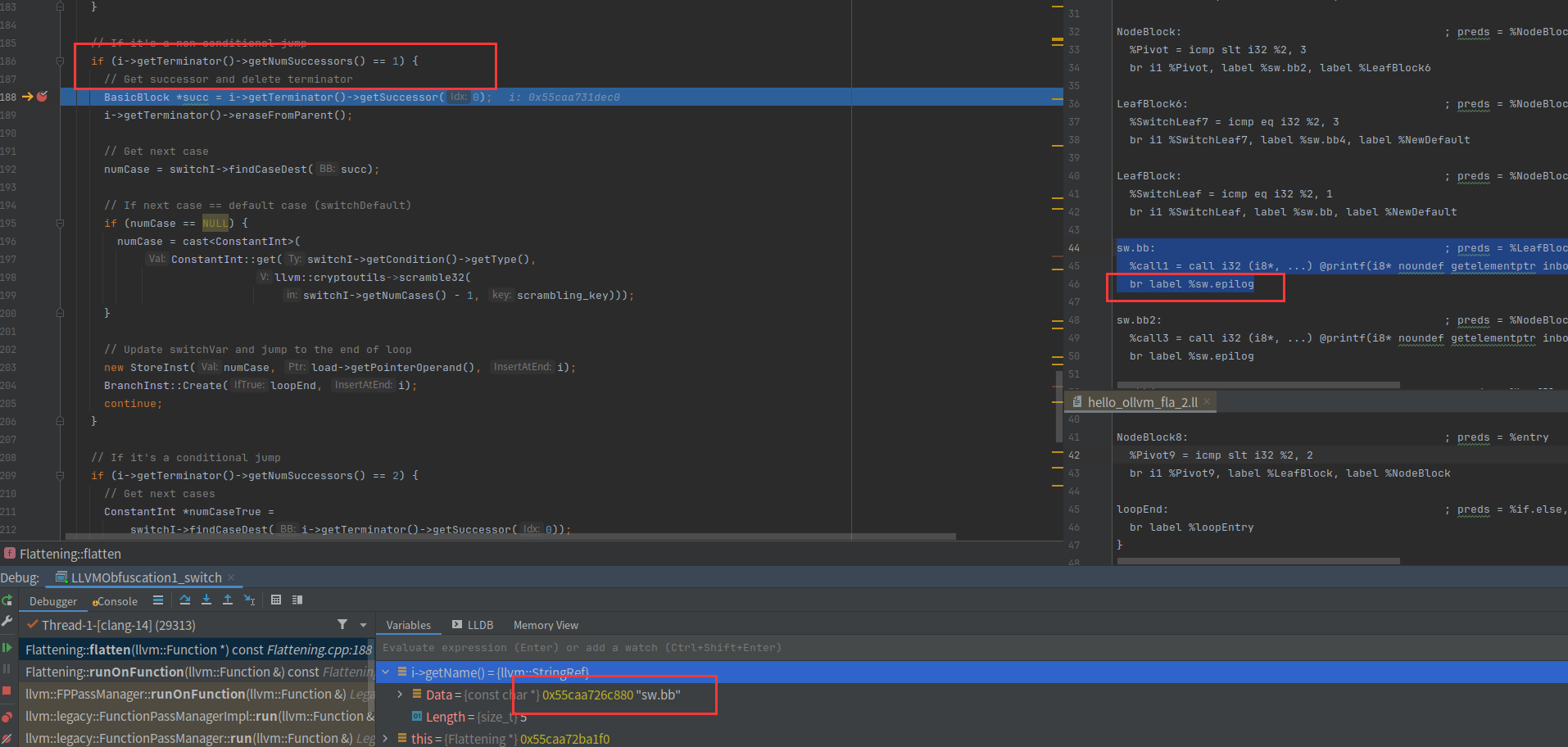
先得到要跳转的基本块是sw.epilog,然后删除 br label %sw.epilog,获取sw.epilog对应的case值
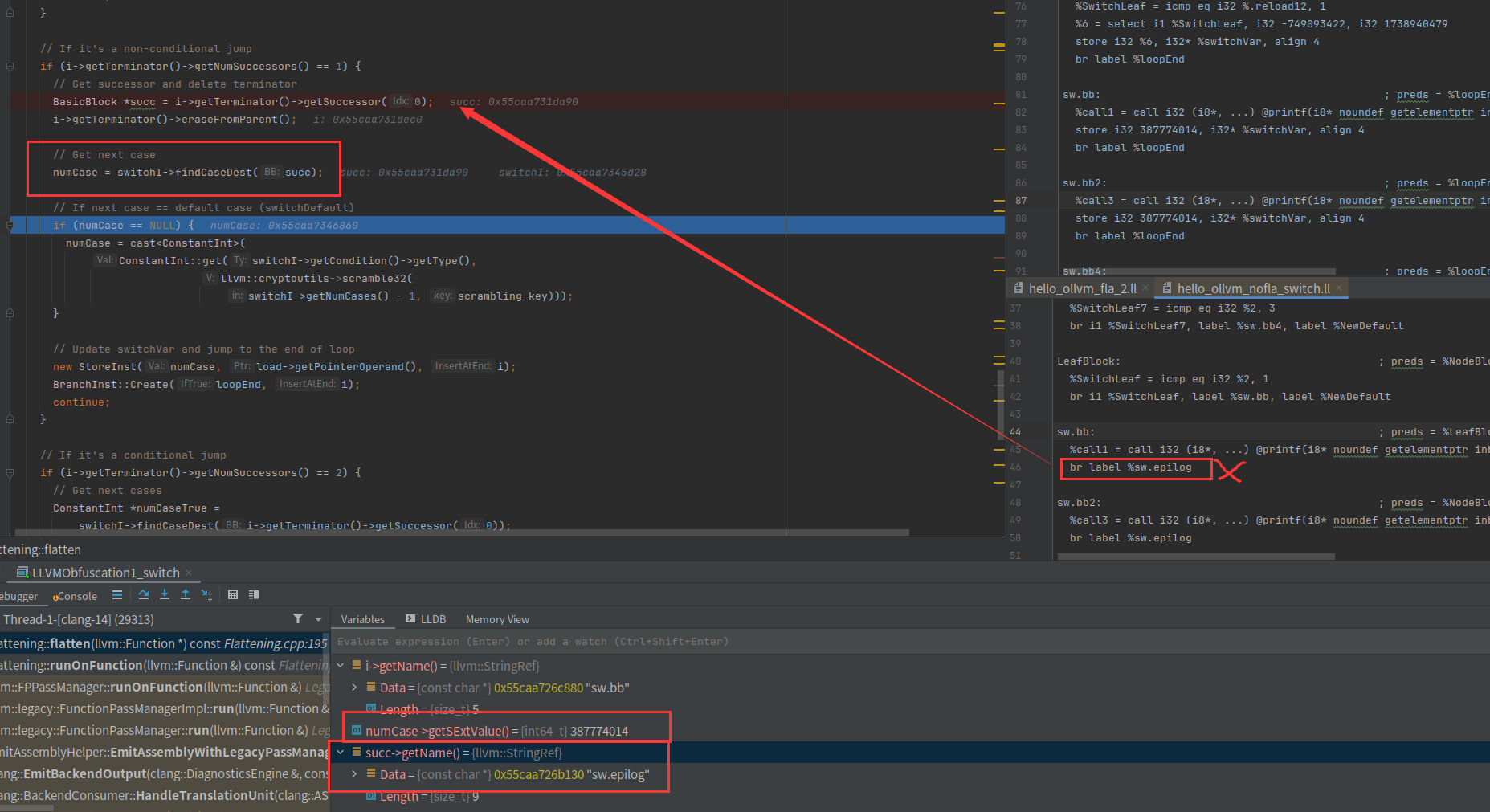
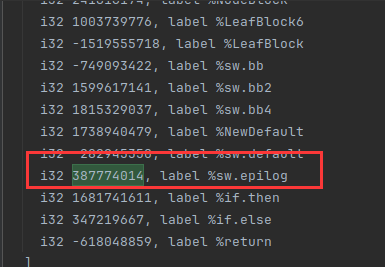
把case值存起来,然后创建一个跳转到loodEnd的分支
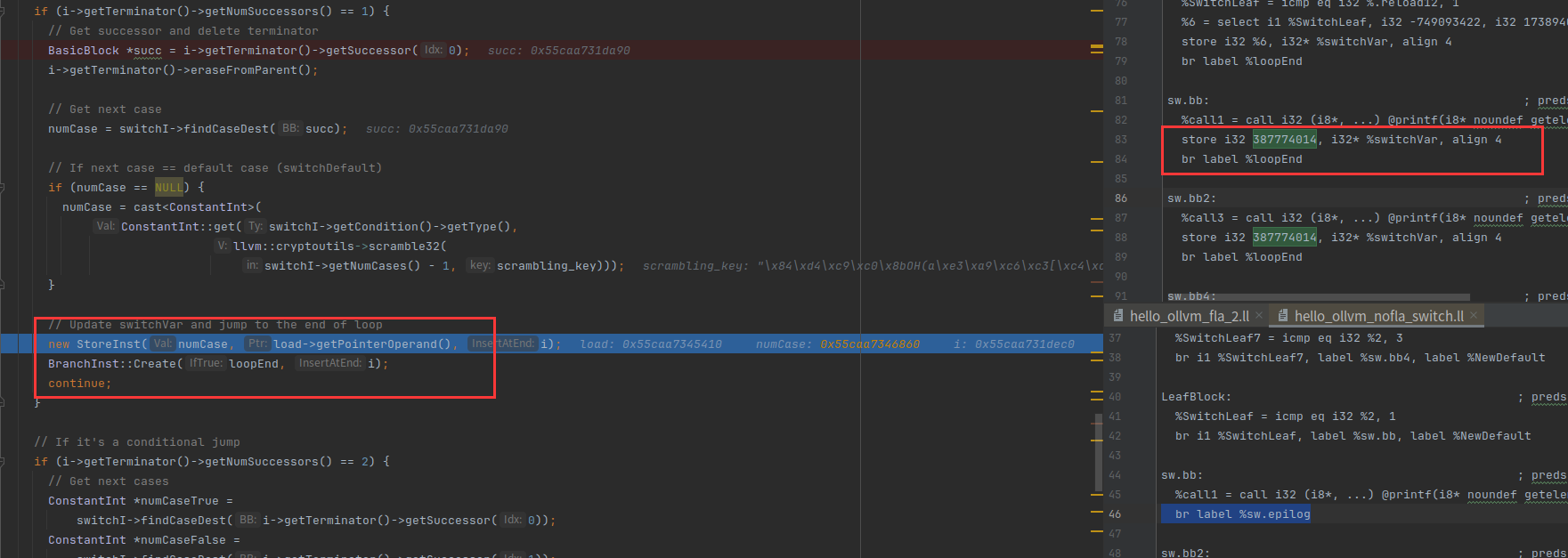
最后就是return跳出循环
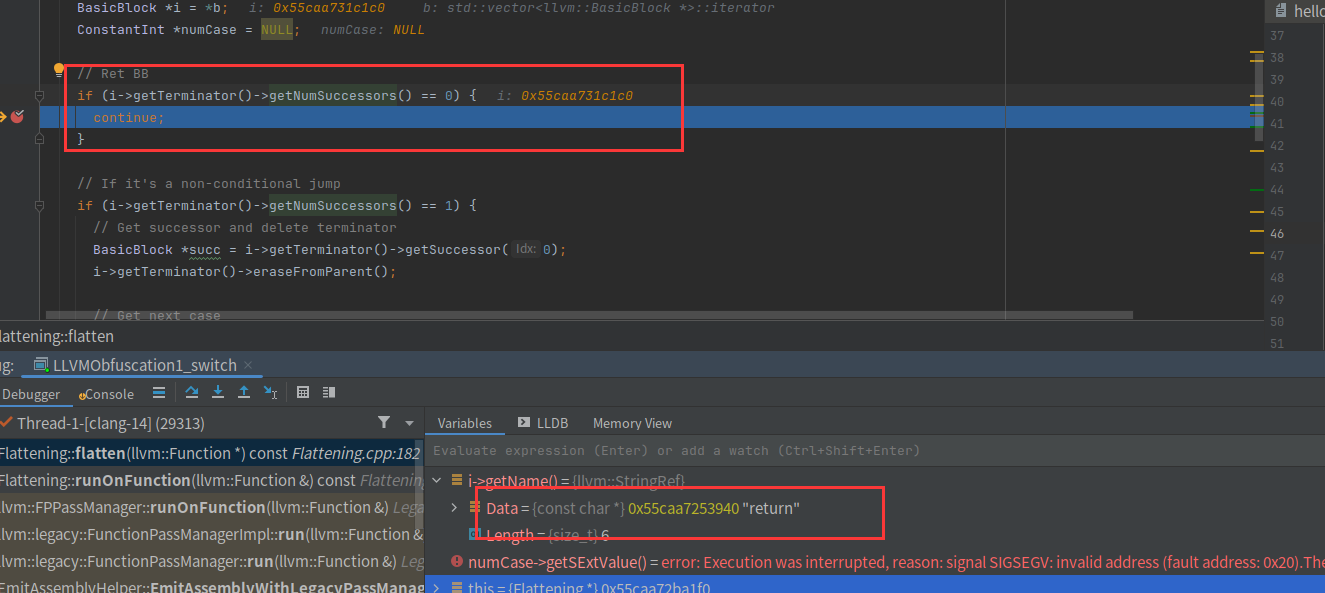
代码最后还有个fixstack,作用就是修复栈
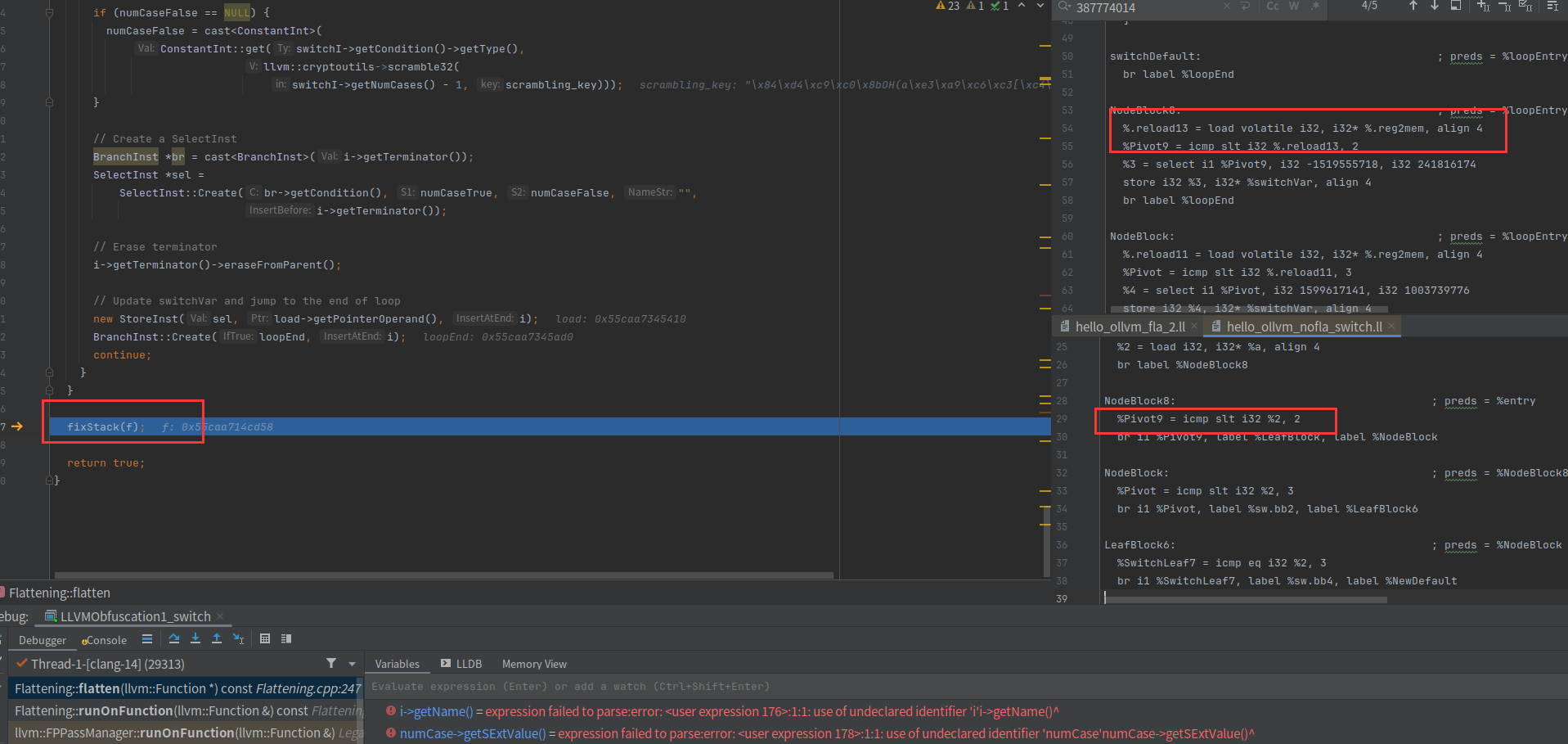
首先看看没fla但是经过lowerswitch和fla的寄存器变化,把%2寄存器变成了alloca
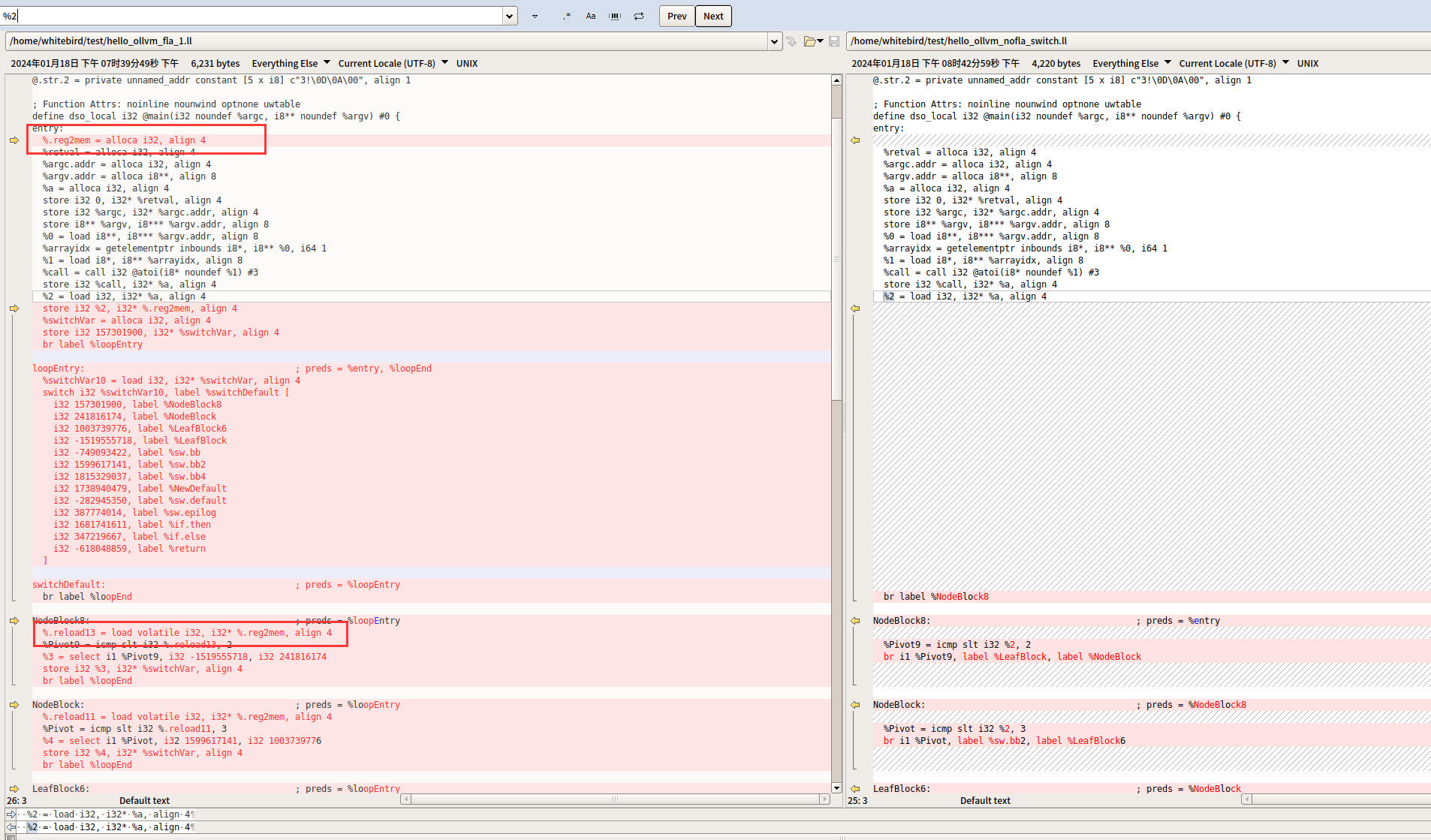
下面的比较都是用的这个声明出来的内存reg2mem
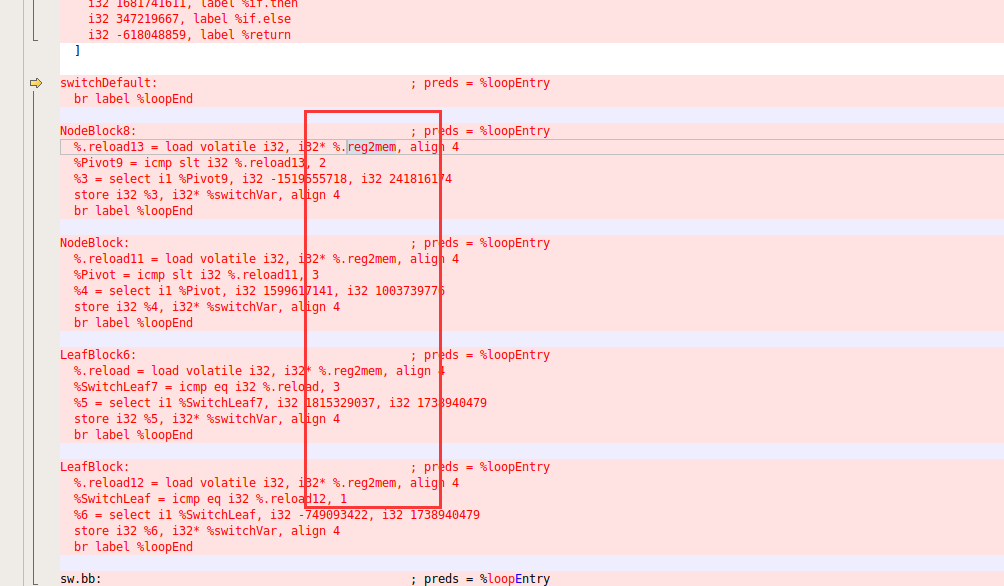
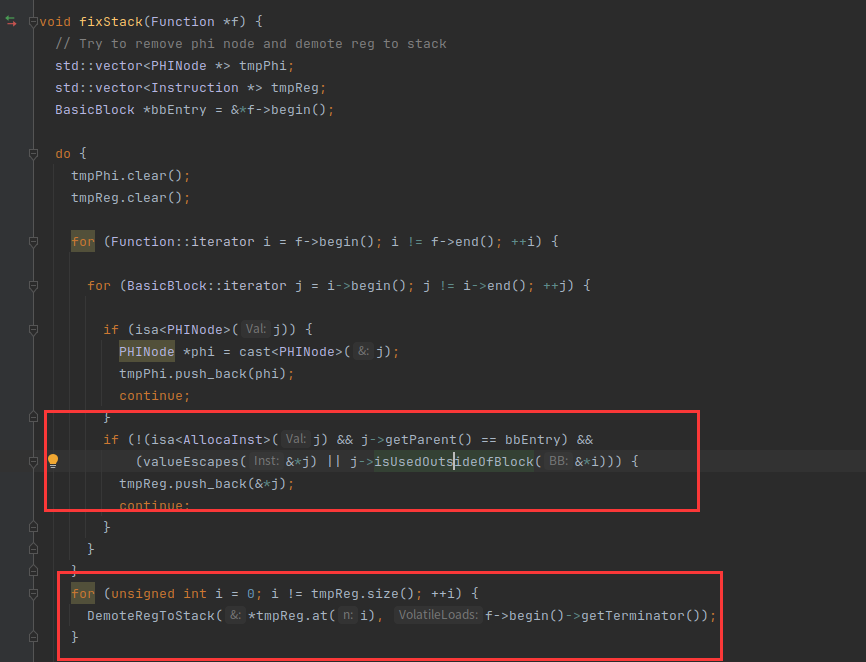
最主要的判断就是是否已经声明了,并且现在处于entry块,如果没有声明,就看这些寄存器是否是entry和其他块都使用,如果是就加入到tmpReg,最后在DemoteRegToStack进行处理
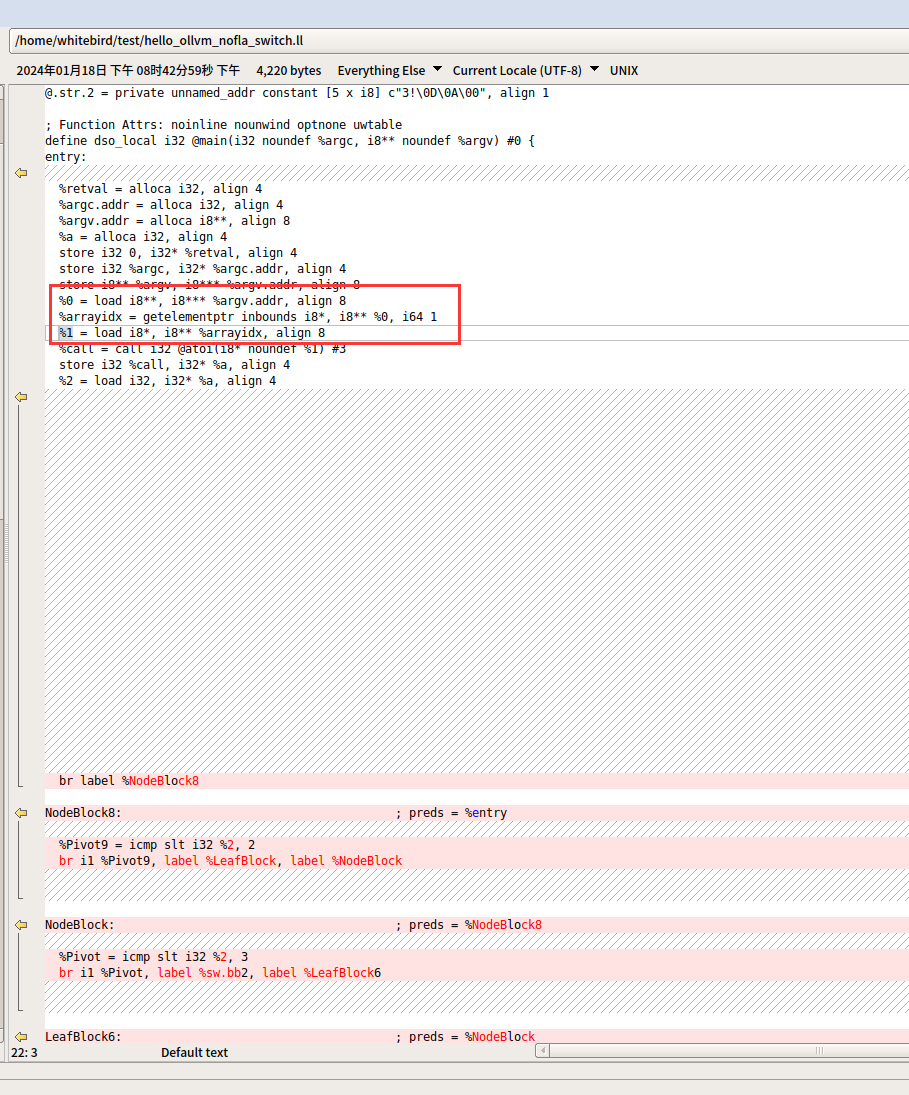
可以看到%0和%1寄存器都是entry自己使用,所以不处理。%2别的块也会使用,所以就会处理。
20、调试ollvm-bcf源码
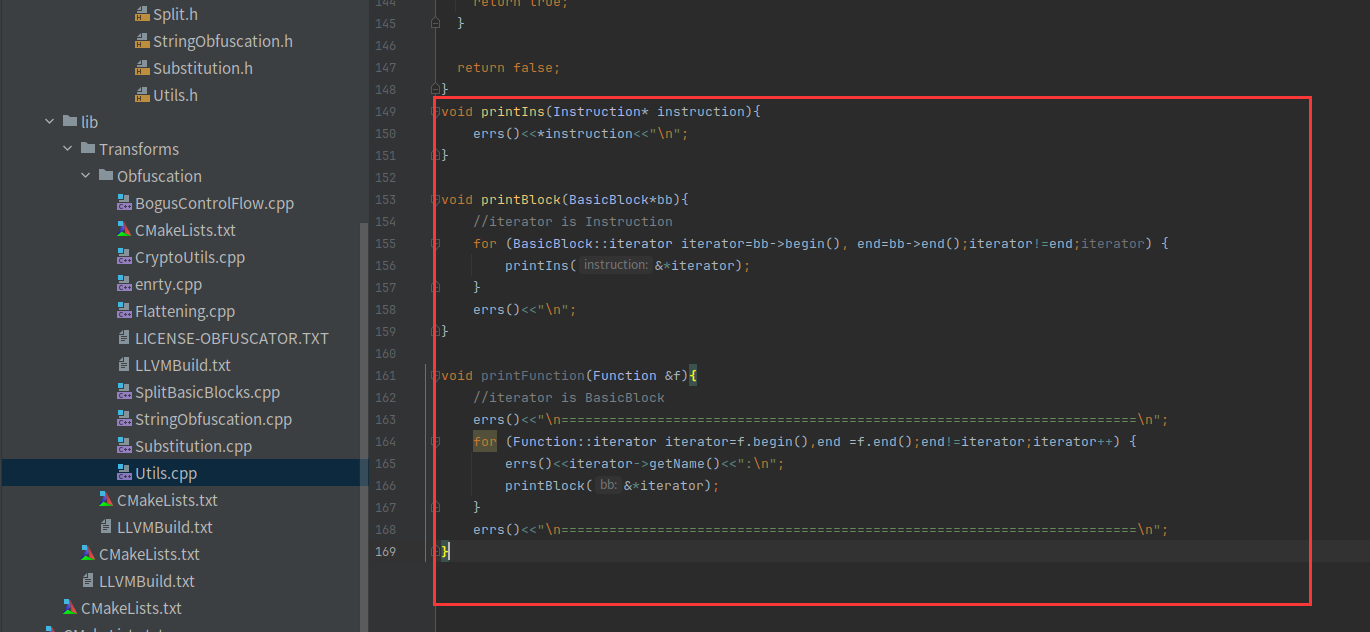
首先我们先写几个函数,用来调试的时候打印ir
void printIns(Instruction* instruction){
errs()<<*instruction<<"\n";
}
void printBlock(BasicBlock*bb){
//iterator is Instruction
for (BasicBlock::iterator iterator=bb->begin(), end=bb->end();iterator!=end;iterator++) {
printIns(&*iterator);
}
errs()<<"\n";
}
void printFunction(Function &f){
//iterator is BasicBlock
errs()<<"\n========================================================================\n";
for (Function::iterator iterator=f.begin(),end =f.end();end!=iterator;iterator++) {
errs()<<iterator->getName()<<":\n";
printBlock(&*iterator);
}
errs()<<"\n========================================================================\n";
}
先看看正常的ir和bcf的ir对比
clang -Xclang -load -Xclang /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -flegacy-pass-manager -emit-llvm -S hello_ollvm.c -o hello_ollvm_src.ll
clang -Xclang -load -Xclang /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -flegacy-pass-manager -mllvm -bcf -emit-llvm -S hello_ollvm.c -o hello_ollvm_bcf.ll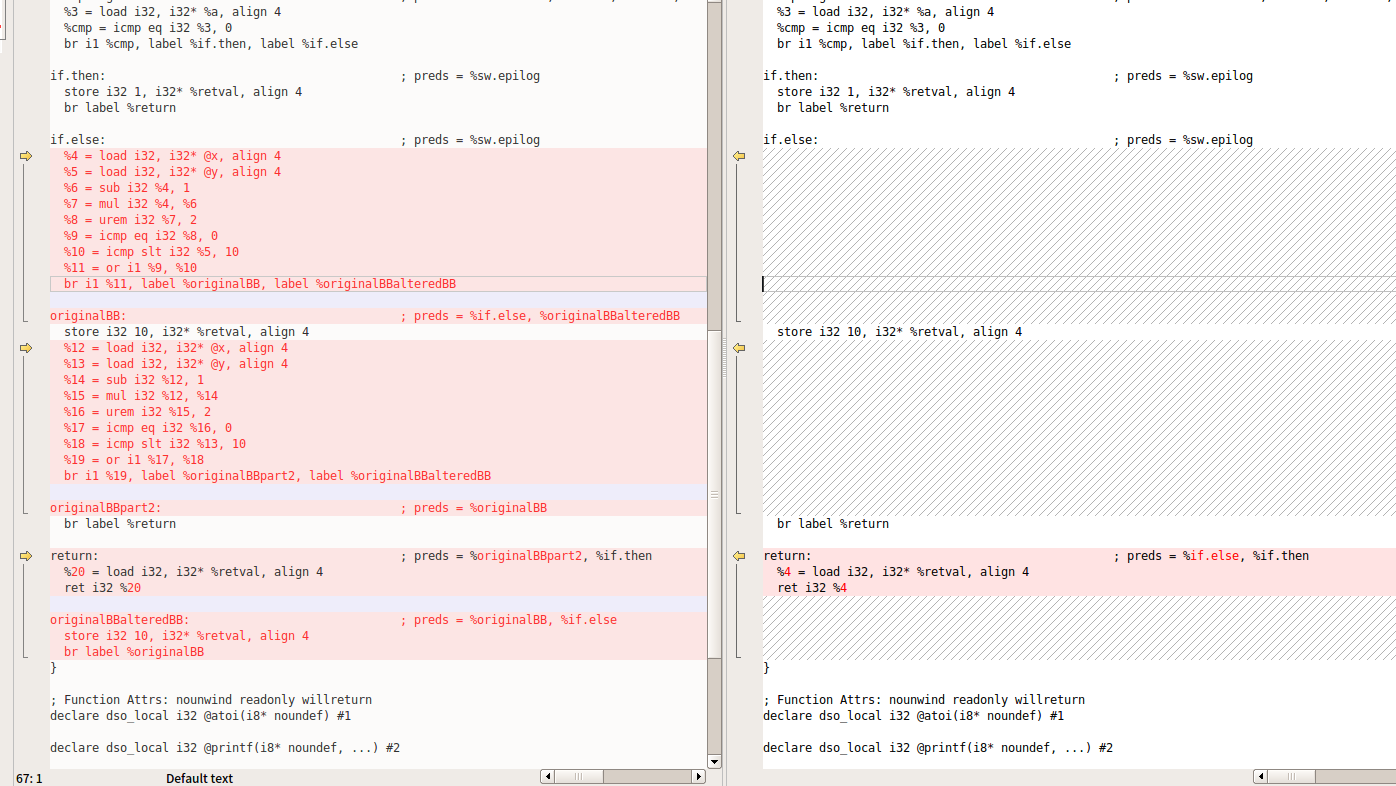
为了效果明显,我们加个-bcf_prob=100,就是把每个块都混淆一下
clang -Xclang -load -Xclang /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -flegacy-pass-manager -mllvm -bcf -mllvm -bcf_prob=100 -emit-llvm -S hello_ollvm.c -o hello_ollvm_bcf.ll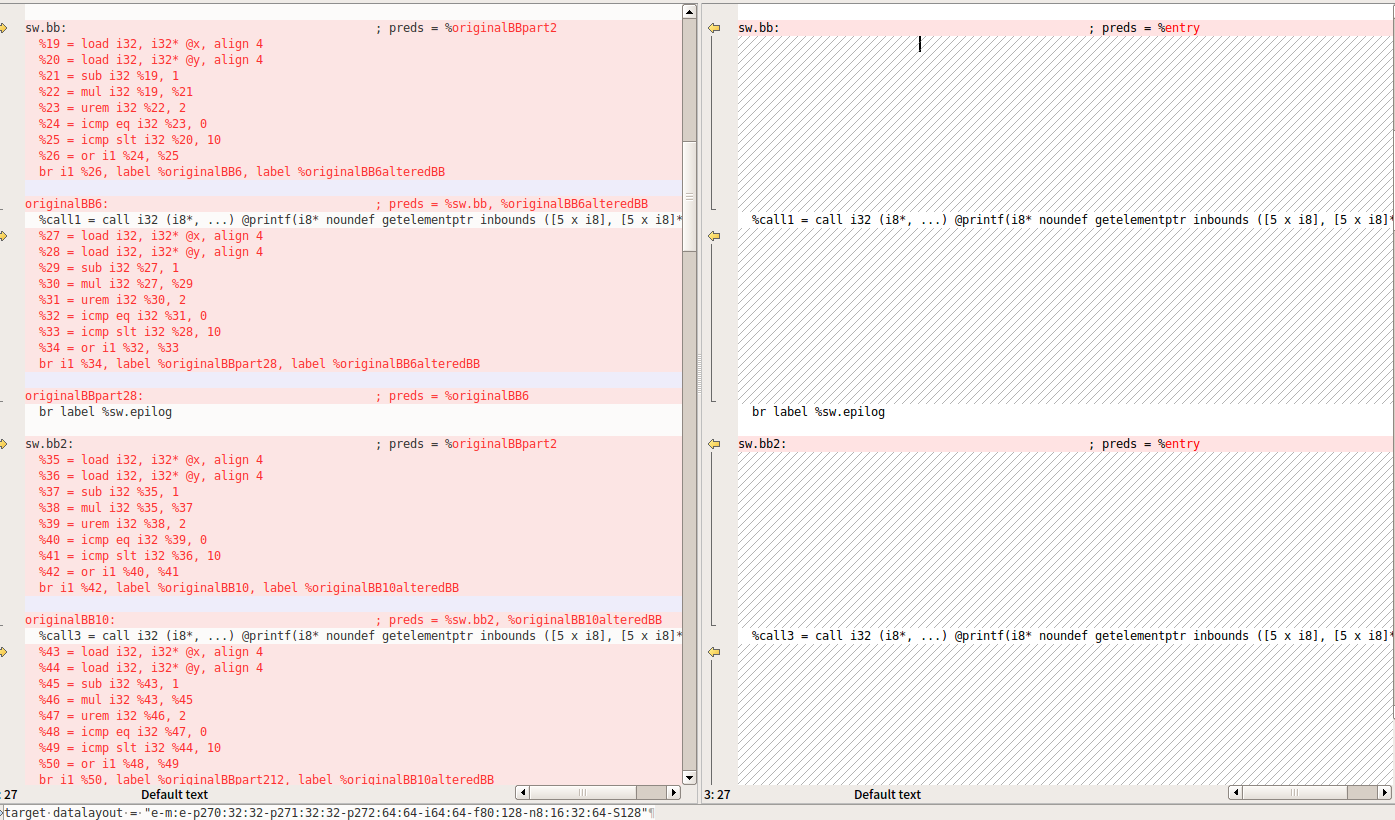
开始调试
-Xclang -load -Xclang /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -flegacy-pass-manager -mllvm -bcf -mllvm -bcf_prob=100 -emit-llvm -S /home/whitebird/test/hello_ollvm.c -o /home/whitebird/test/hello_ollvm_bcf_100.ll
不知道为什么这次选clang和正常参数居然可以断下来调试了
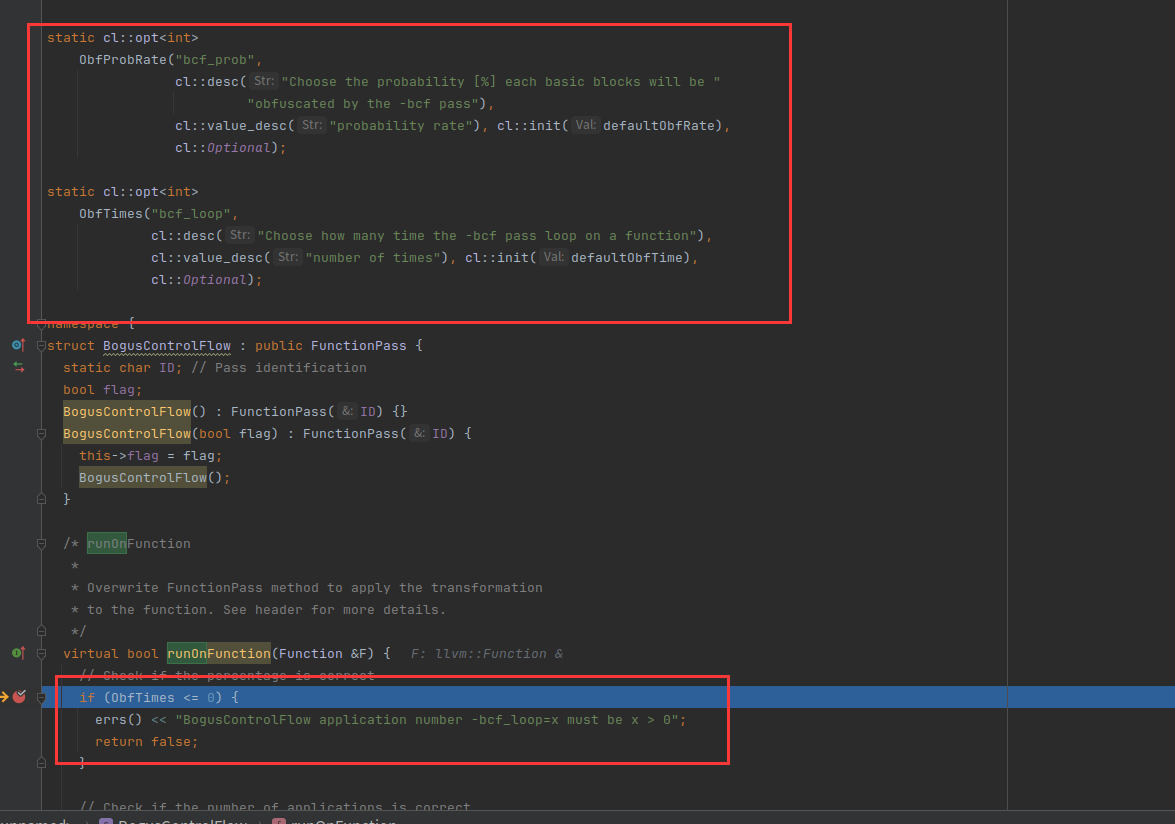
ObfTimes是上面注册的,通过参数传递进来,判断是否小于0,如果小于0就返回了。上面还注册了ObfProbRate,表示每个块被混淆的概率。
判断混淆的概率是否在0-100之间
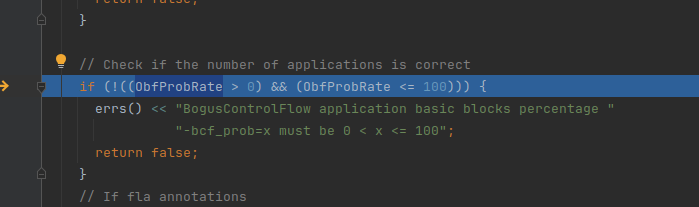
判断是否开启bcf
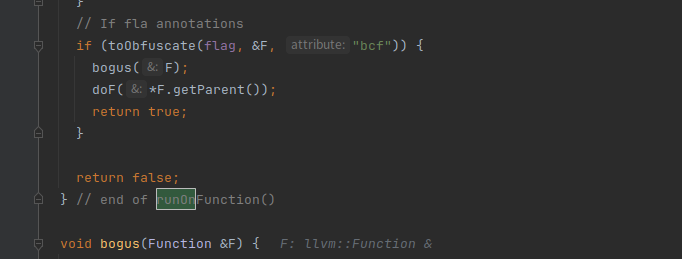
进入bogus
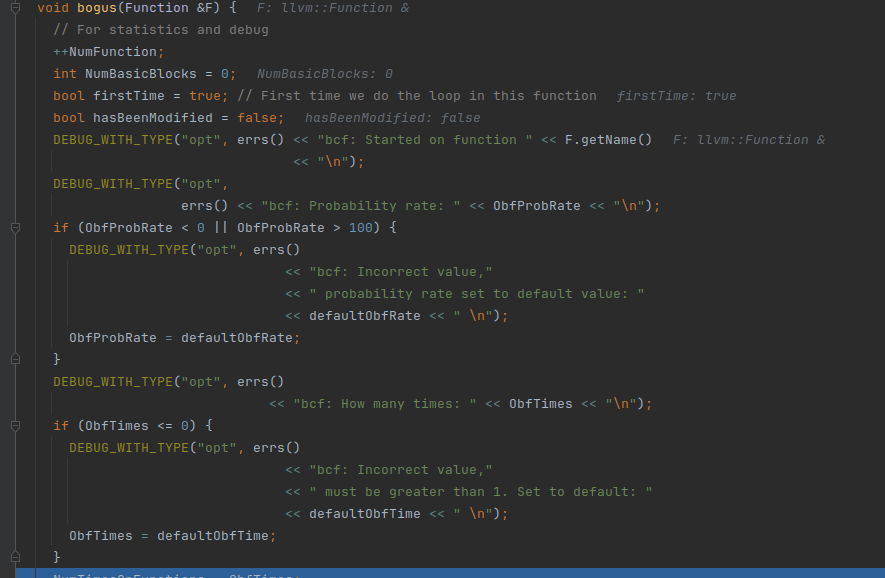
ObfTimes和ObfProbRate都有默认值,对于数值错误的情况下都会设置成默认值
ObfTimes=1;ObfProbRate=30
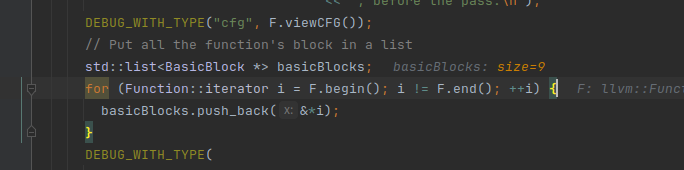
把所有的基本块放到std::list<BasicBlock *>中
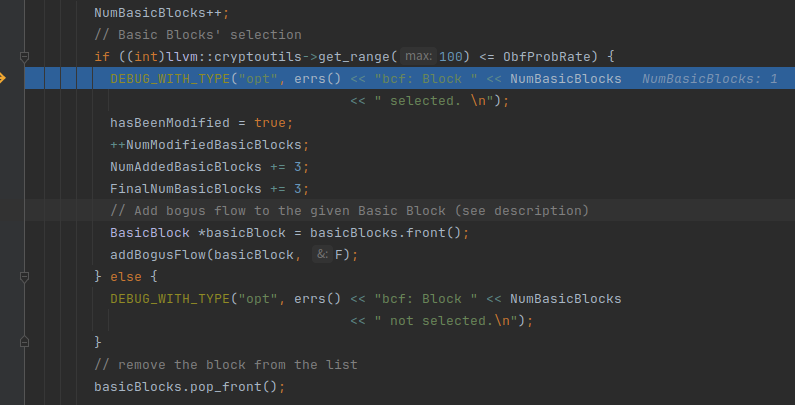
size是9,我们看原来没变过的基本块也是9个
因为我们的ObfProbRate=100,所以进入分支
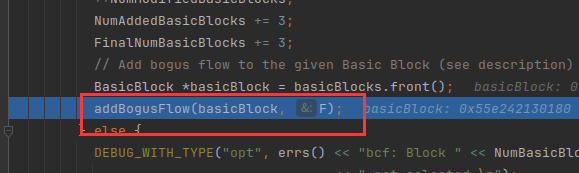
现在我们打印一下两个参数
call printFunction(F)是把之前没有经过任何处理的ir打印出来
call printBlock(basicBlock)是打印了entry块
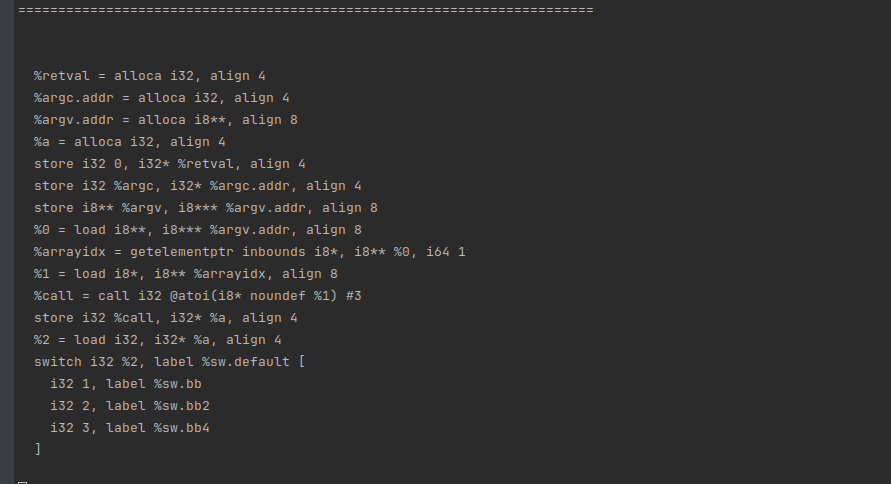
BasicBlock::iterator i1 = basicBlock->begin()取出了entry块的第一行指令
basicBlock->getFirstNonPHIOrDbgOrLifetime()返回基本块中的第一条非 PHI 指令。PHI 指令通常用于表示控制流图中的条件分支,而 getFirstNonPHIOrDbgOrLifetime() 会跳过这些特殊的 PHI 指令,直到找到基本块中的其他类型的指令。
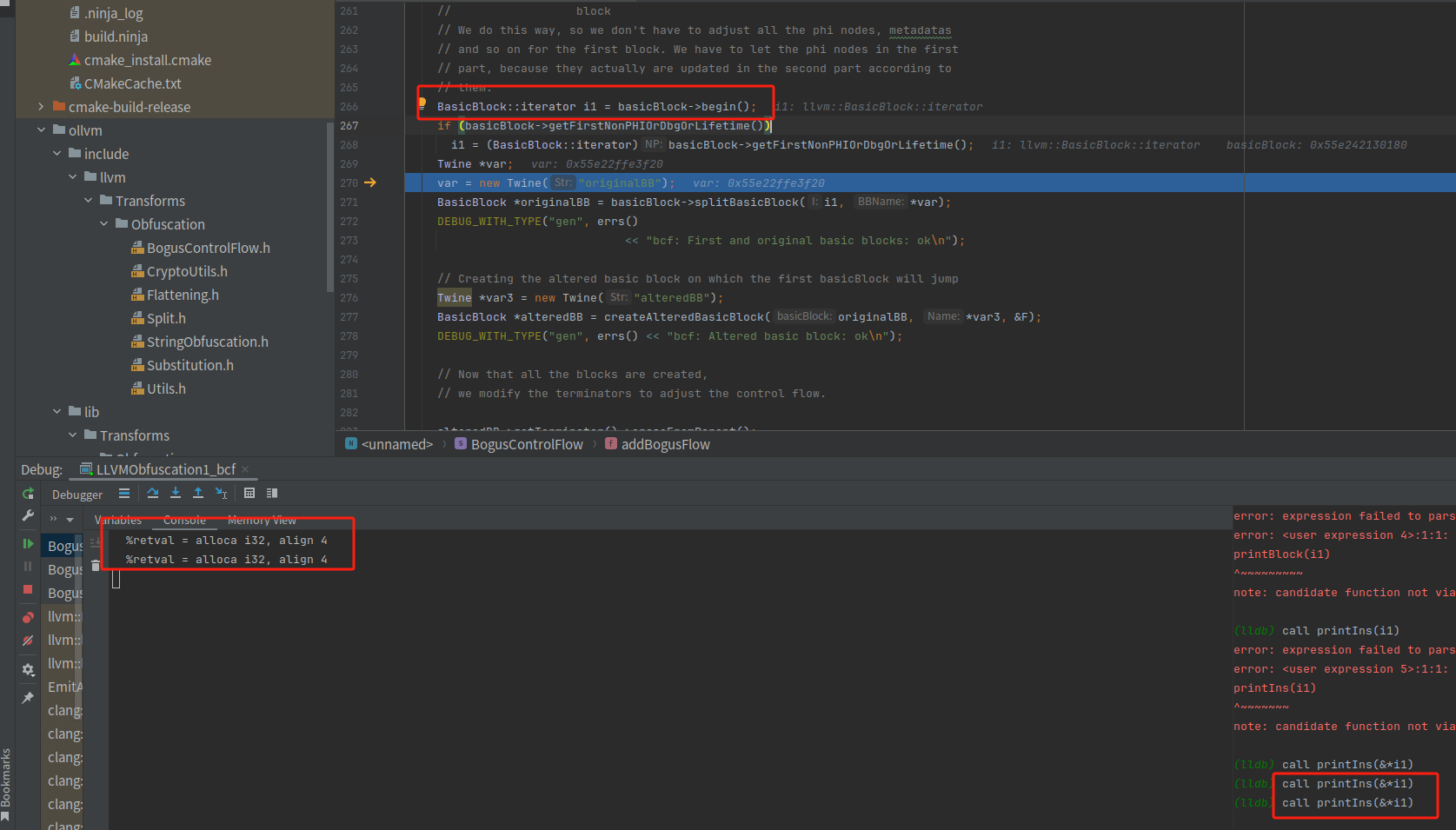
if (basicBlock->getFirstNonPHIOrDbgOrLifetime())
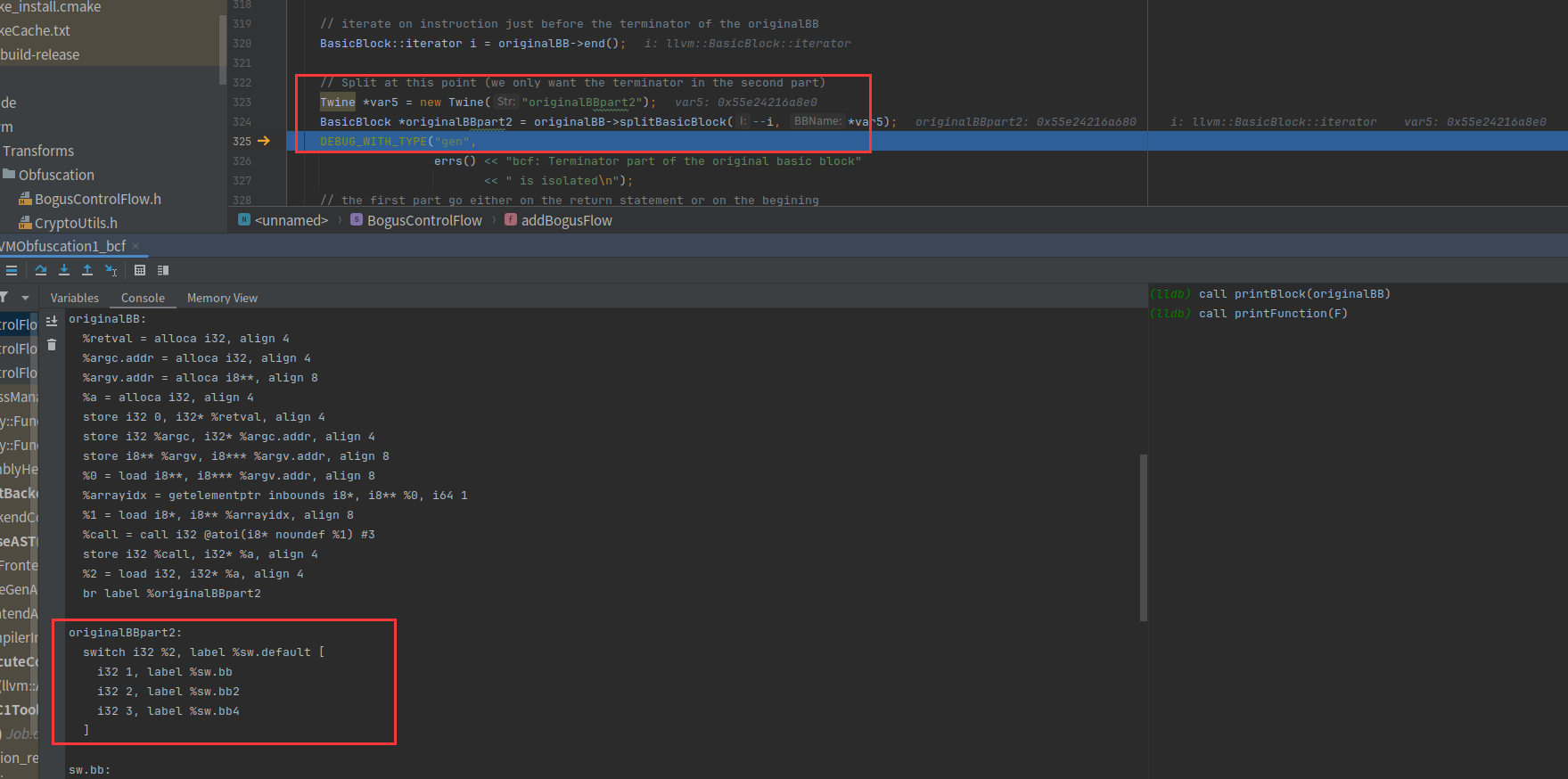
i1 = (BasicBlock::iterator)basicBlock->getFirstNonPHIOrDbgOrLifetime();如果成立就把这条指令取出来,所以取出来的还是第一条指令,因为它不是控制流图中的条件分支
Twine *var;
var = new Twine("originalBB");
BasicBlock *originalBB = basicBlock->splitBasicBlock(i1, *var);将给定的基本块 basicBlock 在指令 i1 处进行分割,得到一个新的基本块 originalBB,并设置新基本块的名称为 originalBB
可以打印一下现在整个源码的ir,此时entry会跳到originalBB
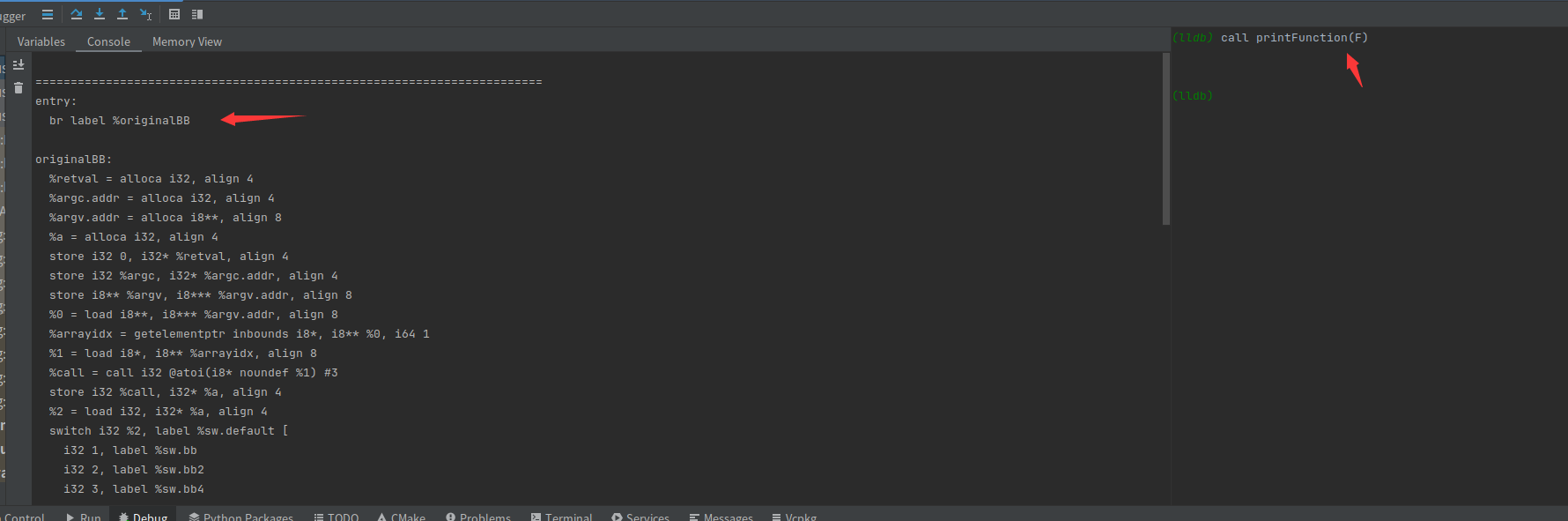
createAlteredBasicBlock创建了一个alteredBB块,其实和originalBB一样的,只不过变量名发生了改变,这个块是一个虚假块
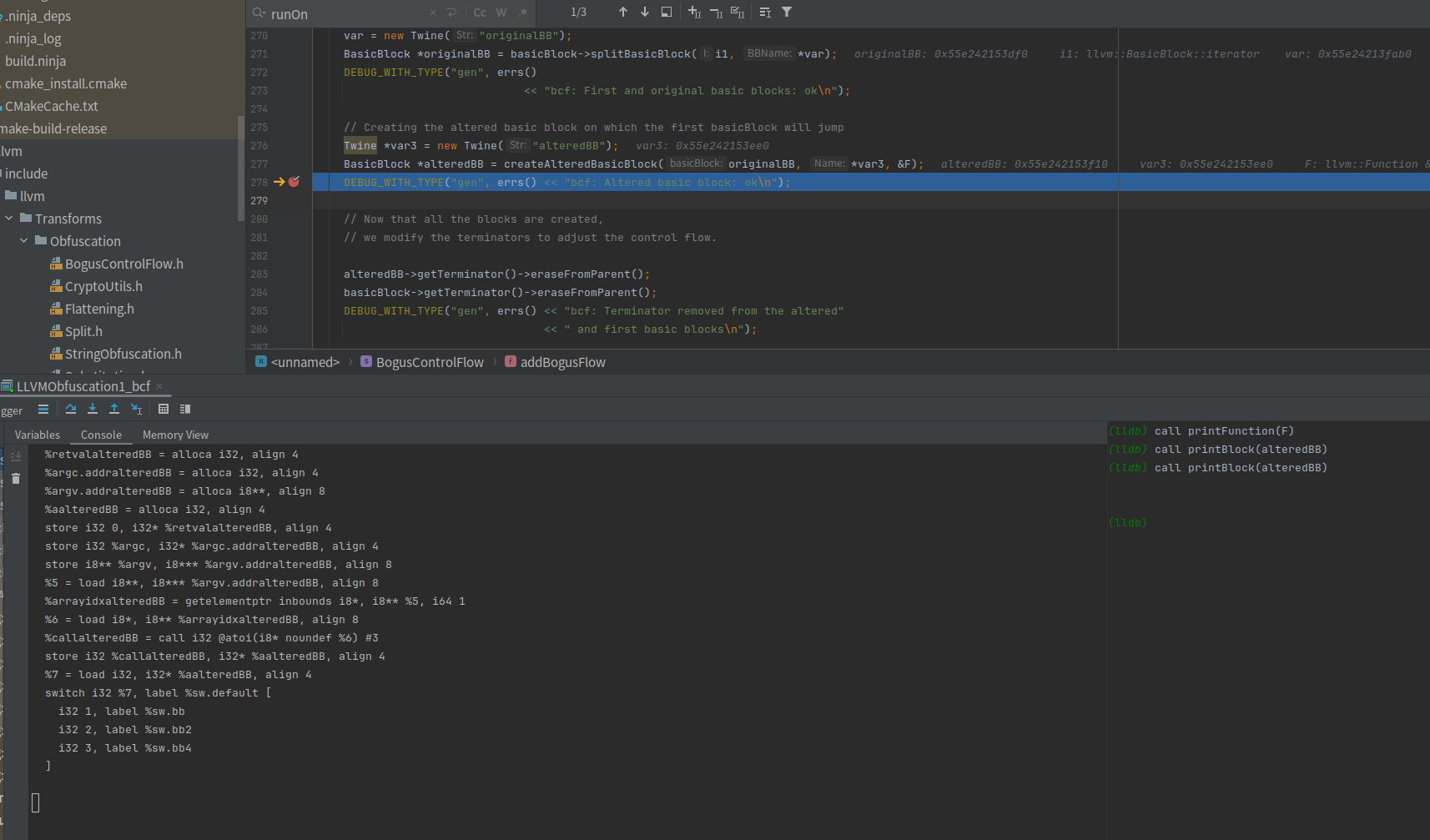
打印一下整个源码的ir
========================================================================
entry:
br label %originalBB
originalBB:
%retval = alloca i32, align 4
%argc.addr = alloca i32, align 4
%argv.addr = alloca i8**, align 8
%a = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 %argc, i32* %argc.addr, align 4
store i8** %argv, i8*** %argv.addr, align 8
%0 = load i8**, i8*** %argv.addr, align 8
%arrayidx = getelementptr inbounds i8*, i8** %0, i64 1
%1 = load i8*, i8** %arrayidx, align 8
%call = call i32 @atoi(i8* noundef %1) #3
store i32 %call, i32* %a, align 4
%2 = load i32, i32* %a, align 4
switch i32 %2, label %sw.default [
i32 1, label %sw.bb
i32 2, label %sw.bb2
i32 3, label %sw.bb4
]
...
...
...
originalBBalteredBB:
%retvalalteredBB = alloca i32, align 4
%argc.addralteredBB = alloca i32, align 4
%argv.addralteredBB = alloca i8**, align 8
%aalteredBB = alloca i32, align 4
store i32 0, i32* %retvalalteredBB, align 4
store i32 %argc, i32* %argc.addralteredBB, align 4
store i8** %argv, i8*** %argv.addralteredBB, align 8
%5 = load i8**, i8*** %argv.addralteredBB, align 8
%arrayidxalteredBB = getelementptr inbounds i8*, i8** %5, i64 1
%6 = load i8*, i8** %arrayidxalteredBB, align 8
%callalteredBB = call i32 @atoi(i8* noundef %6) #3
store i32 %callalteredBB, i32* %aalteredBB, align 4
%7 = load i32, i32* %aalteredBB, align 4
switch i32 %7, label %sw.default [
i32 1, label %sw.bb
i32 2, label %sw.bb2
i32 3, label %sw.bb4
]
========================================================================alteredBB->getTerminator()->eraseFromParent()把originalBBalteredBB最后一行的switch删除了
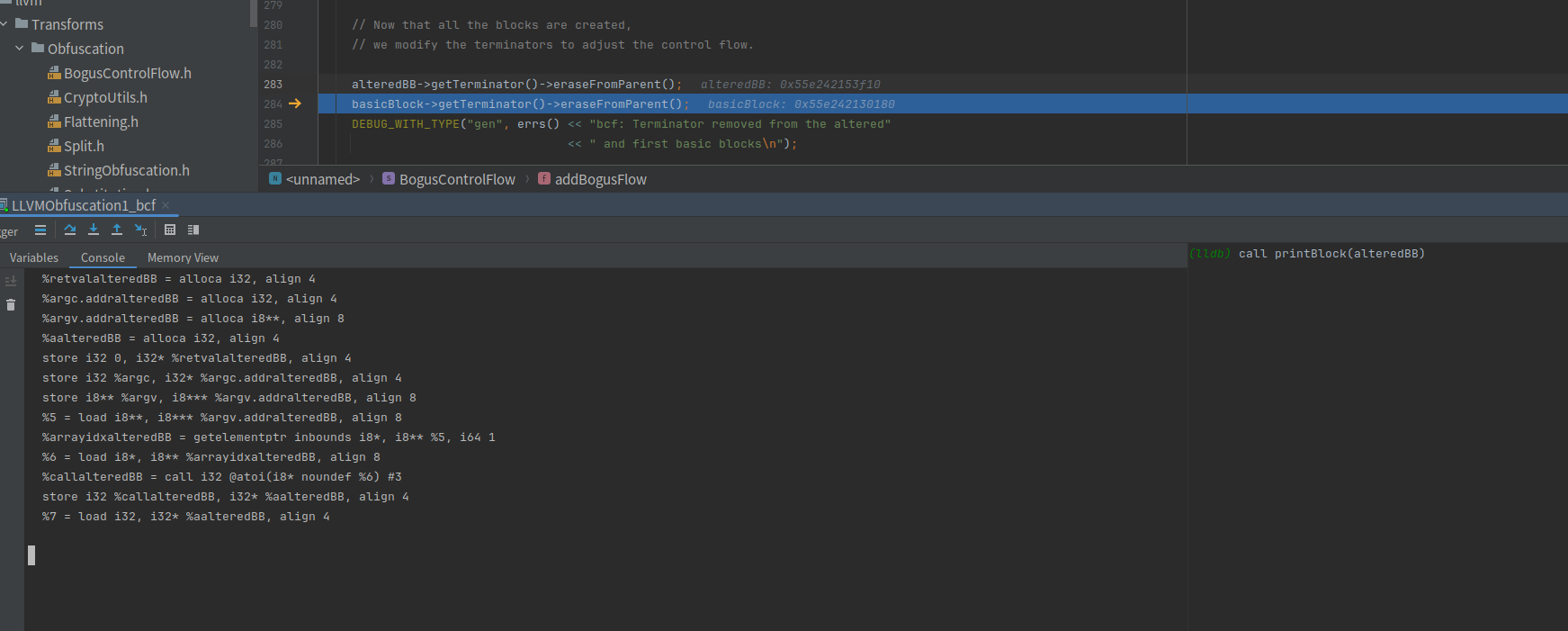
basicBlock->getTerminator()->eraseFromParent()把basicBlock的最后一行删了
entry只有一行指令,所以删完后,打印出来是空的
创建了两个浮点数用作比较
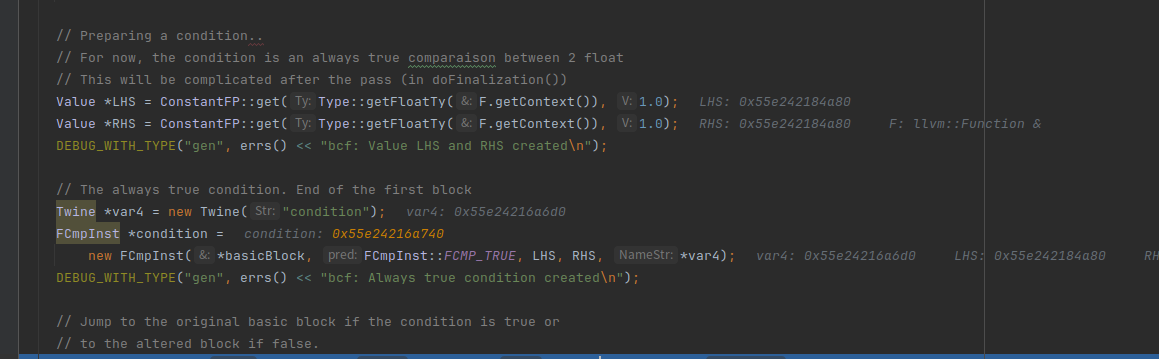
FCmpInst condition = new FCmpInst(*basicBlock, FCmpInst::FCMP_TRUE, LHS, RHS, *var4)创建了一个浮点数比较指令,该指令在给定的基本块 basicBlock 中进行,而此时的basicBlock 是entry块。这个指令比较了两个操作数 LHS 和 RHS 的值,并根据指定的比较条件(在此处是 FCmpInst::FCMP_TRUE)来设置条件结果
参考:https://llvm.org/docs/LangRef.html#fcmp-instruction

设置成true就是恒成立,看一下现在的entry块

创建一个分支,true跳向originalBB块,false跳向alteredBB块,condition是上面FCmpInst得到的,看似是两个浮点数比较,实际上始终返回true,也就是跳向originalBB
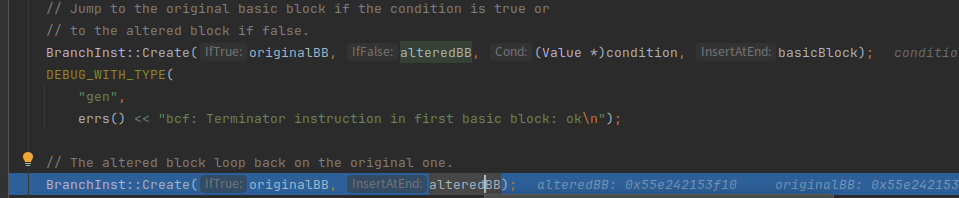

虚假块的末尾插上 跳转到originalBB
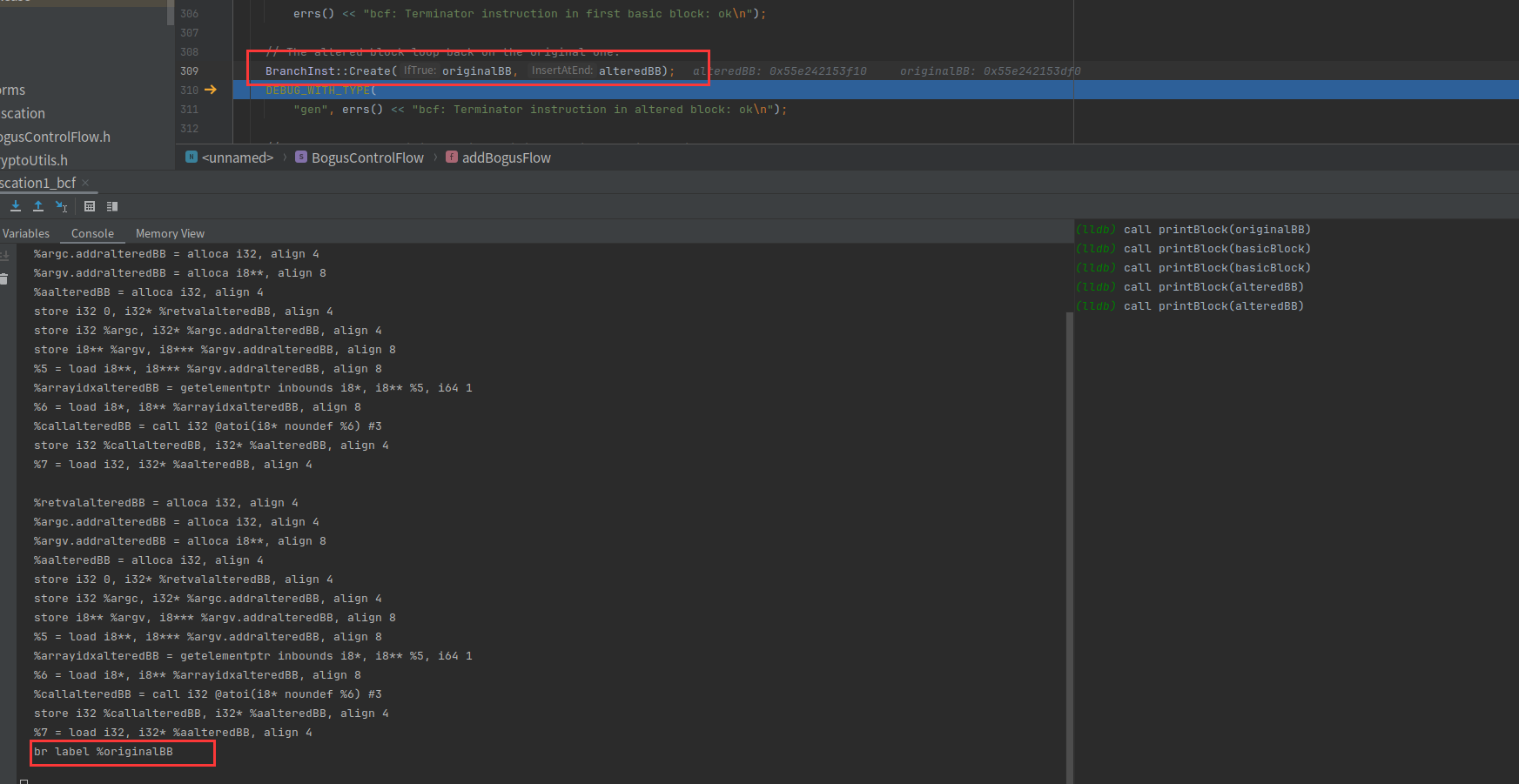
把originalBB块分割出originalBBpart2
originalBB->getTerminator()->eraseFromParent()把跳转指令删除了
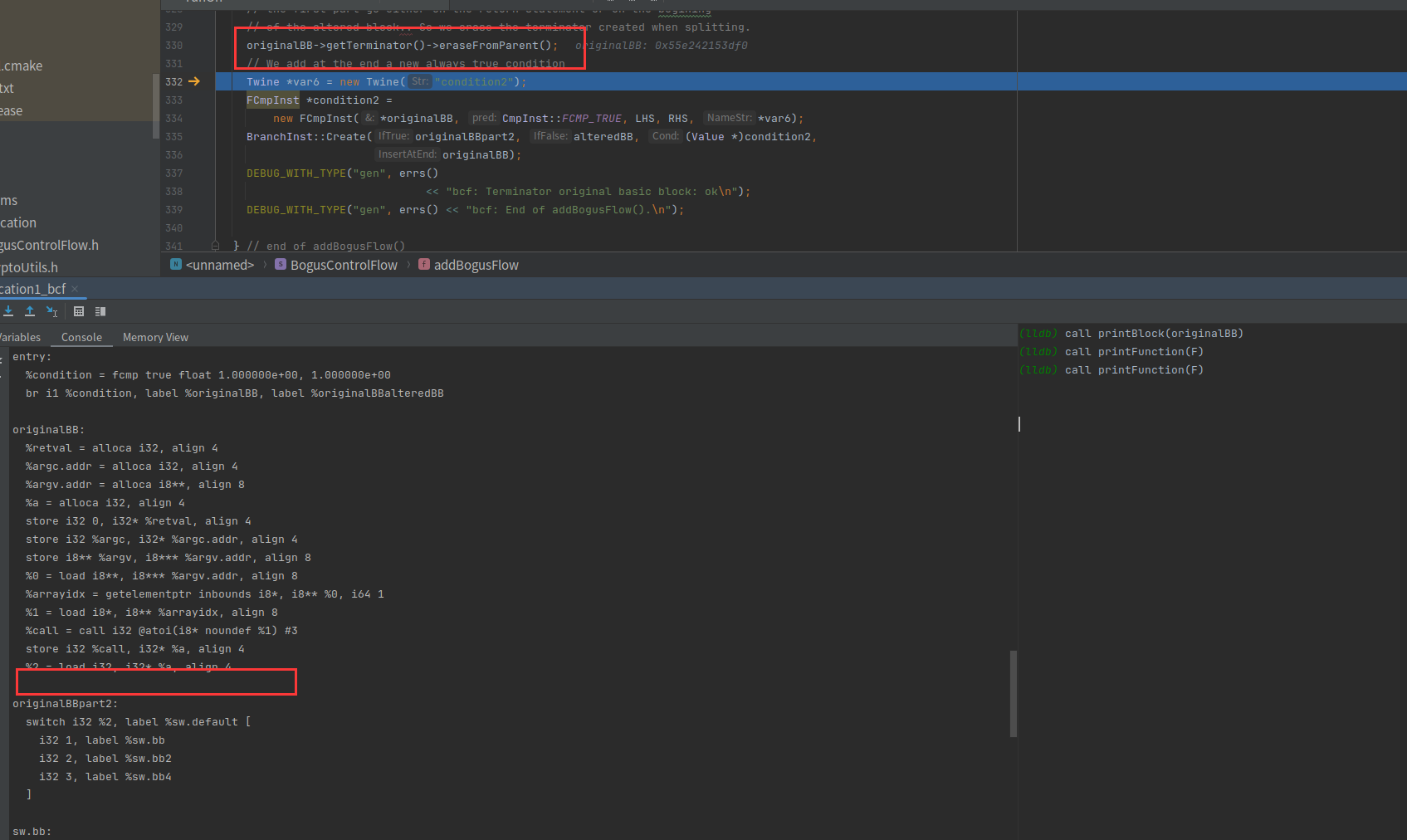
又创建一个浮点数比较,但是还是恒返回true,插入到originalBB的尾部
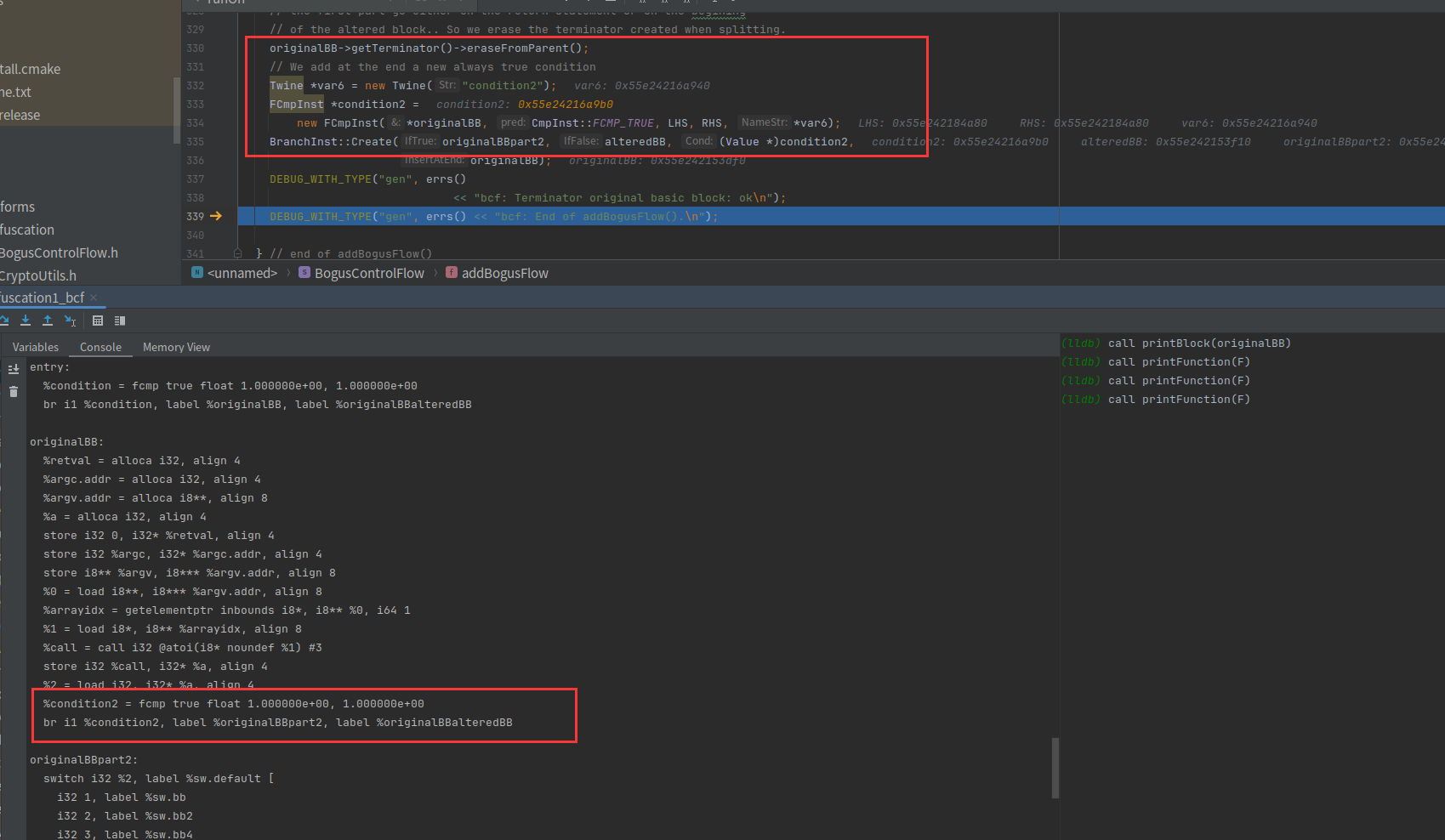
然后就结束了,我们比较一下对entry块的所有操作
我们又跳到这个循环中,打印一下此时的basicBlock,也就是第二个基本块
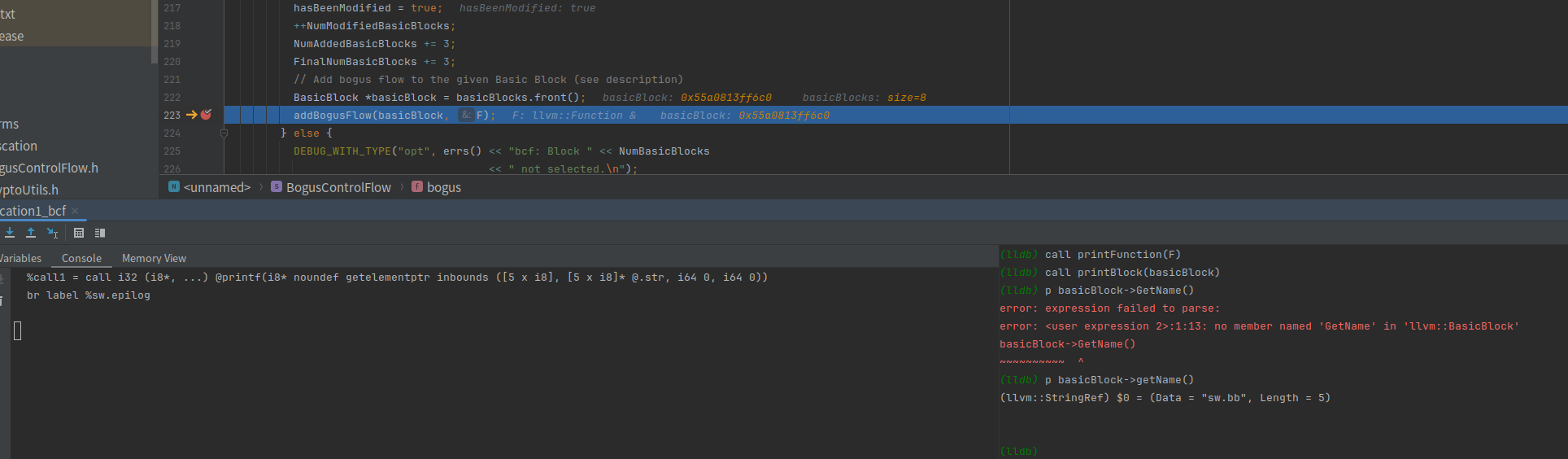
看一下执行完的效果
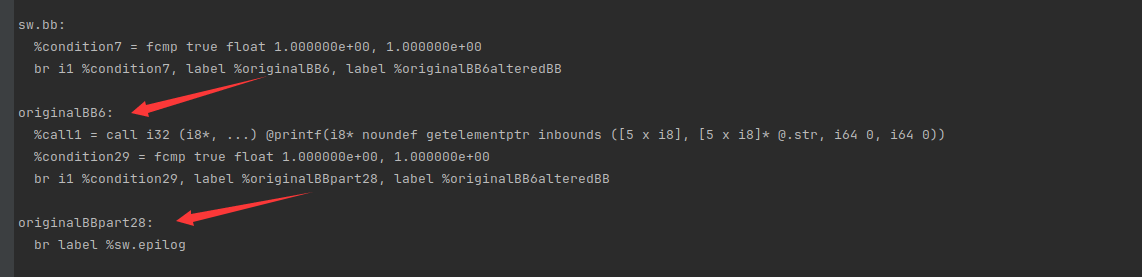
虚假块

剩下的基本块操作类似,就不展开了。
我们现在回过头调doF函数
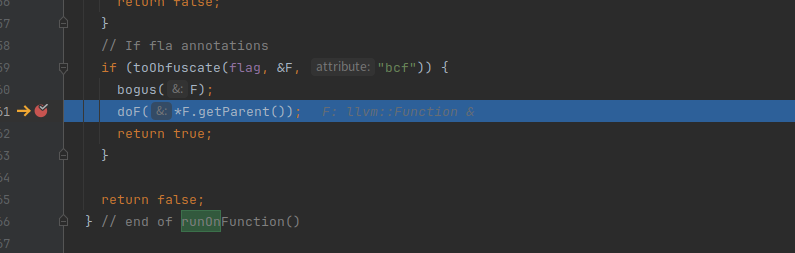
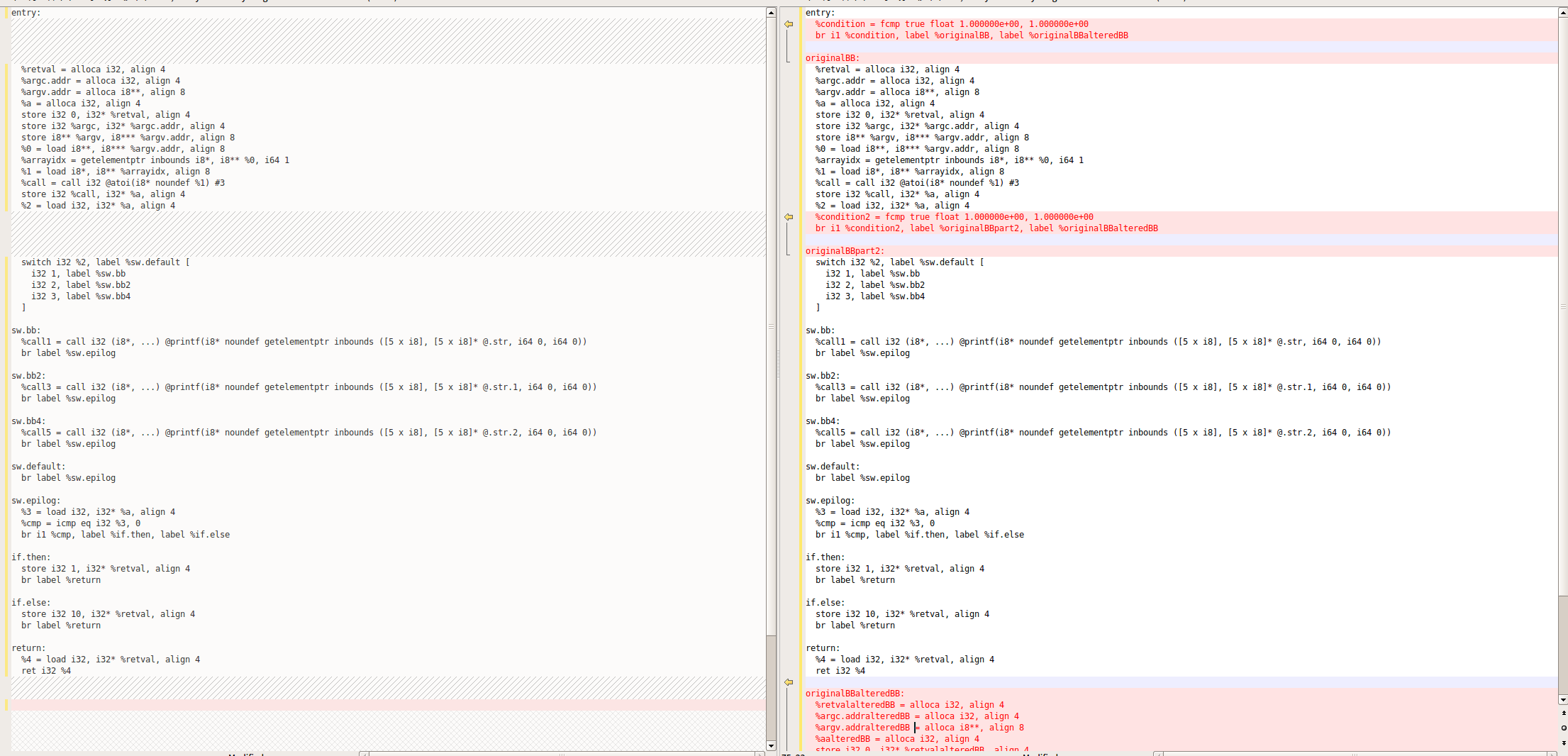
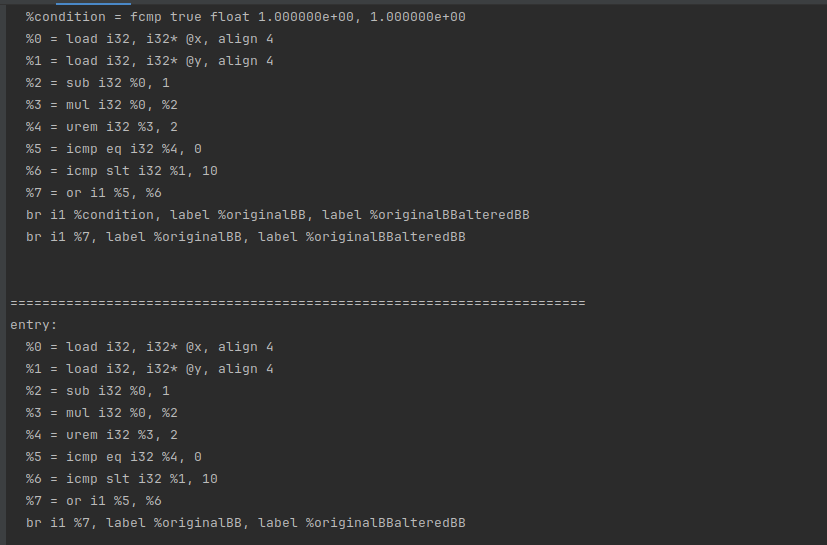
此时的ir
========================================================================
entry:
%condition = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition, label %originalBB, label %originalBBalteredBB
originalBB:
%retval = alloca i32, align 4
%argc.addr = alloca i32, align 4
%argv.addr = alloca i8**, align 8
%a = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 %argc, i32* %argc.addr, align 4
store i8** %argv, i8*** %argv.addr, align 8
%0 = load i8**, i8*** %argv.addr, align 8
%arrayidx = getelementptr inbounds i8*, i8** %0, i64 1
%1 = load i8*, i8** %arrayidx, align 8
%call = call i32 @atoi(i8* noundef %1) #3
store i32 %call, i32* %a, align 4
%2 = load i32, i32* %a, align 4
%condition2 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition2, label %originalBBpart2, label %originalBBalteredBB
originalBBpart2:
switch i32 %2, label %sw.default [
i32 1, label %sw.bb
i32 2, label %sw.bb2
i32 3, label %sw.bb4
]
sw.bb:
%condition7 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition7, label %originalBB6, label %originalBB6alteredBB
originalBB6:
%call1 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([5 x i8], [5 x i8]* @.str, i64 0, i64 0))
%condition29 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition29, label %originalBBpart28, label %originalBB6alteredBB
originalBBpart28:
br label %sw.epilog
sw.bb2:
%condition11 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition11, label %originalBB10, label %originalBB10alteredBB
originalBB10:
%call3 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([5 x i8], [5 x i8]* @.str.1, i64 0, i64 0))
%condition213 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition213, label %originalBBpart212, label %originalBB10alteredBB
originalBBpart212:
br label %sw.epilog
sw.bb4:
%condition15 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition15, label %originalBB14, label %originalBB14alteredBB
originalBB14:
%call5 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([5 x i8], [5 x i8]* @.str.2, i64 0, i64 0))
%condition217 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition217, label %originalBBpart216, label %originalBB14alteredBB
originalBBpart216:
br label %sw.epilog
sw.default:
%condition19 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition19, label %originalBB18, label %originalBB18alteredBB
originalBB18:
%condition221 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition221, label %originalBBpart220, label %originalBB18alteredBB
originalBBpart220:
br label %sw.epilog
sw.epilog:
%condition23 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition23, label %originalBB22, label %originalBB22alteredBB
originalBB22:
%3 = load i32, i32* %a, align 4
%cmp = icmp eq i32 %3, 0
%condition225 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition225, label %originalBBpart224, label %originalBB22alteredBB
originalBBpart224:
br i1 %cmp, label %if.then, label %if.else
if.then:
%condition27 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition27, label %originalBB26, label %originalBB26alteredBB
originalBB26:
store i32 1, i32* %retval, align 4
%condition229 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition229, label %originalBBpart228, label %originalBB26alteredBB
originalBBpart228:
br label %return
if.else:
%condition31 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition31, label %originalBB30, label %originalBB30alteredBB
originalBB30:
store i32 10, i32* %retval, align 4
%condition233 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition233, label %originalBBpart232, label %originalBB30alteredBB
originalBBpart232:
br label %return
return:
%condition35 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition35, label %originalBB34, label %originalBB34alteredBB
originalBB34:
%4 = load i32, i32* %retval, align 4
%condition237 = fcmp true float 1.000000e+00, 1.000000e+00
br i1 %condition237, label %originalBBpart236, label %originalBB34alteredBB
originalBBpart236:
ret i32 %4
originalBBalteredBB:
%retvalalteredBB = alloca i32, align 4
%argc.addralteredBB = alloca i32, align 4
%argv.addralteredBB = alloca i8**, align 8
%aalteredBB = alloca i32, align 4
store i32 0, i32* %retvalalteredBB, align 4
store i32 %argc, i32* %argc.addralteredBB, align 4
store i8** %argv, i8*** %argv.addralteredBB, align 8
%5 = load i8**, i8*** %argv.addralteredBB, align 8
%arrayidxalteredBB = getelementptr inbounds i8*, i8** %5, i64 1
%6 = load i8*, i8** %arrayidxalteredBB, align 8
%callalteredBB = call i32 @atoi(i8* noundef %6) #3
store i32 %callalteredBB, i32* %aalteredBB, align 4
%7 = load i32, i32* %aalteredBB, align 4
br label %originalBB
originalBB6alteredBB:
%call1alteredBB = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([5 x i8], [5 x i8]* @.str, i64 0, i64 0))
br label %originalBB6
originalBB10alteredBB:
%call3alteredBB = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([5 x i8], [5 x i8]* @.str.1, i64 0, i64 0))
br label %originalBB10
originalBB14alteredBB:
%call5alteredBB = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([5 x i8], [5 x i8]* @.str.2, i64 0, i64 0))
br label %originalBB14
originalBB18alteredBB:
br label %originalBB18
originalBB22alteredBB:
%8 = load i32, i32* %a, align 4
%cmpalteredBB = icmp eq i32 %8, 0
br label %originalBB22
originalBB26alteredBB:
store i32 1, i32* %retval, align 4
br label %originalBB26
originalBB30alteredBB:
store i32 10, i32* %retval, align 4
br label %originalBB30
originalBB34alteredBB:
%9 = load i32, i32* %retval, align 4
br label %originalBB34
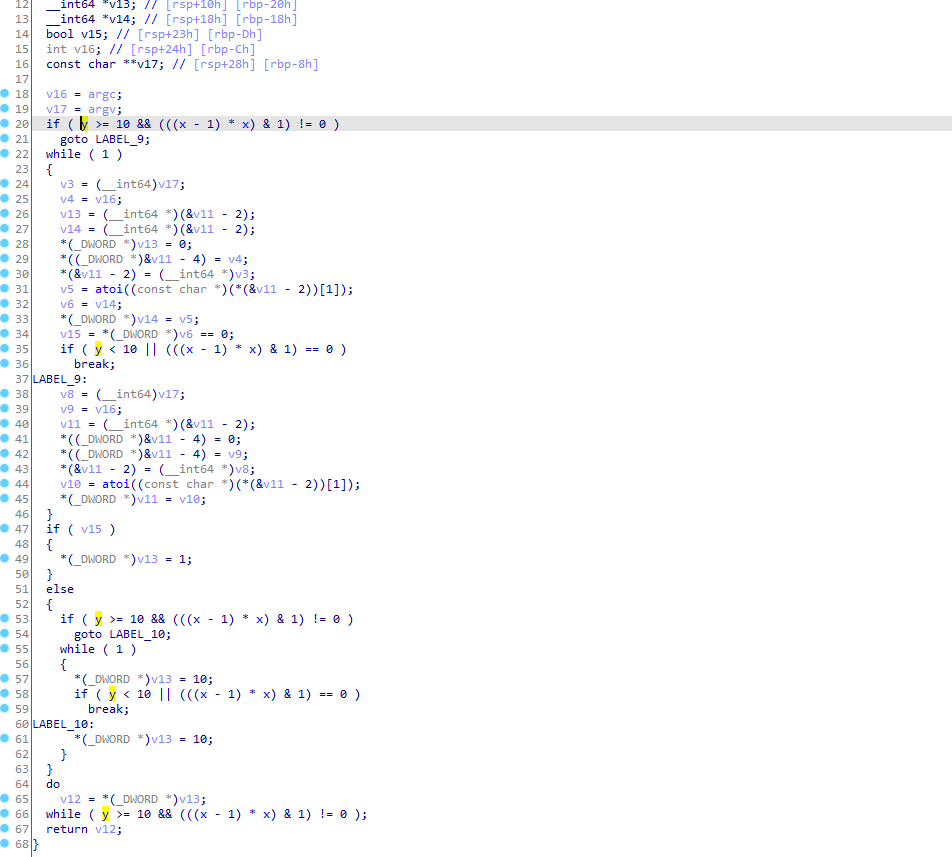
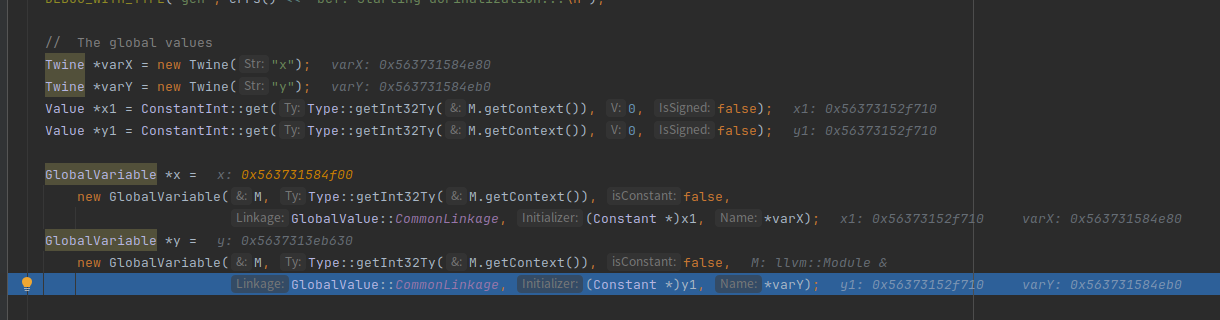
========================================================================创建两个浮点数变量,并且设置为全局变量
第一个Module是最外层的,它的成员是Function
Instruction *tbb = fi->getTerminator()拿出了的第一个基本块的最后一句指令
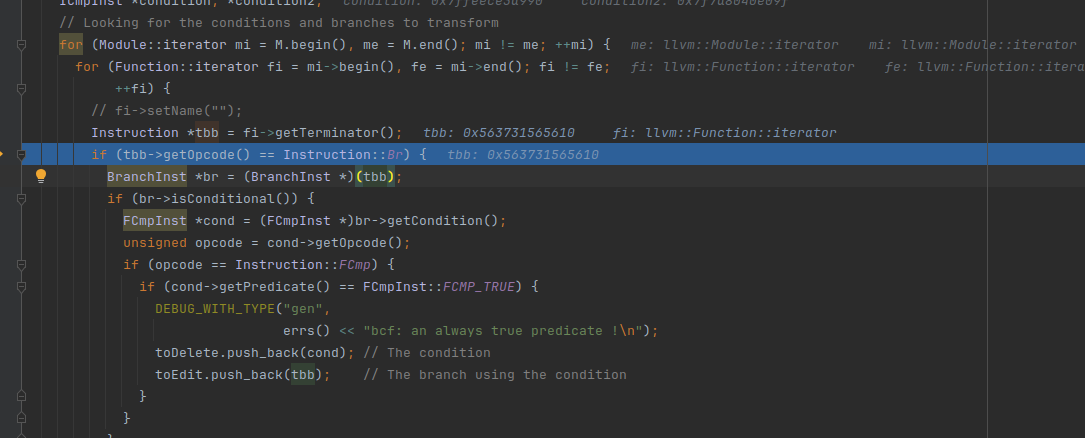
判断是否是br指令,如果是就转为br指令
然后判断是否是有条件跳转,如果是就拿出它的跳转条件:%condition = fcmp true float 1.000000e+00, 1.000000e+00
获取opcode,比较是否使用的fcmp
如果使用的fcmp,就判断是否是FCMP_TRUE,所以第一个基本块成立
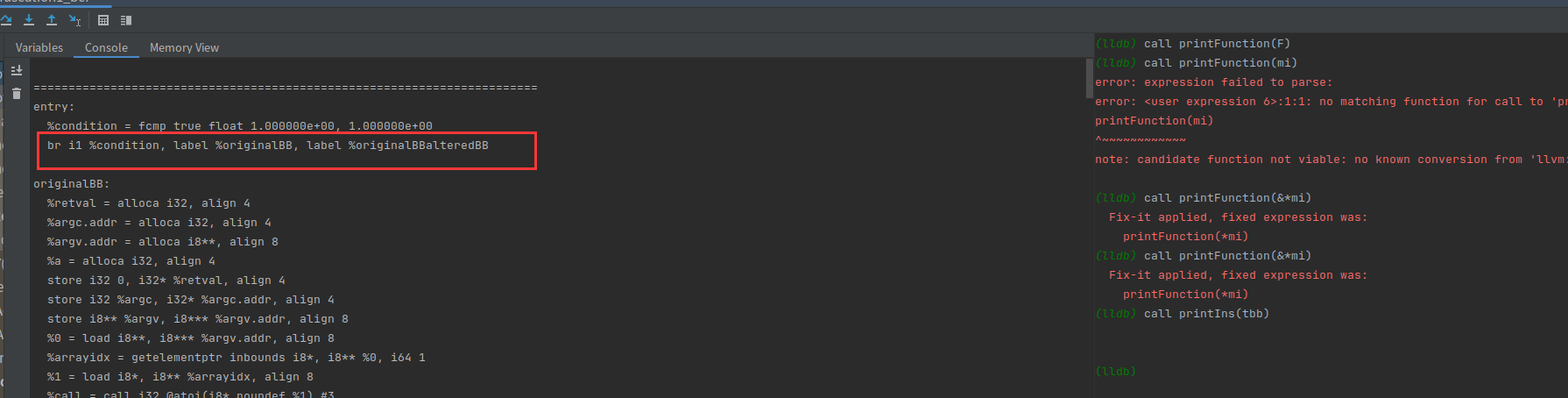
接下来处理toEdit,toEdit存放的都是符合条件的br指令
先加载了两个浮点数,x和y
创建sub、Urem、ICMP_EQ、ICMP_SLT指令
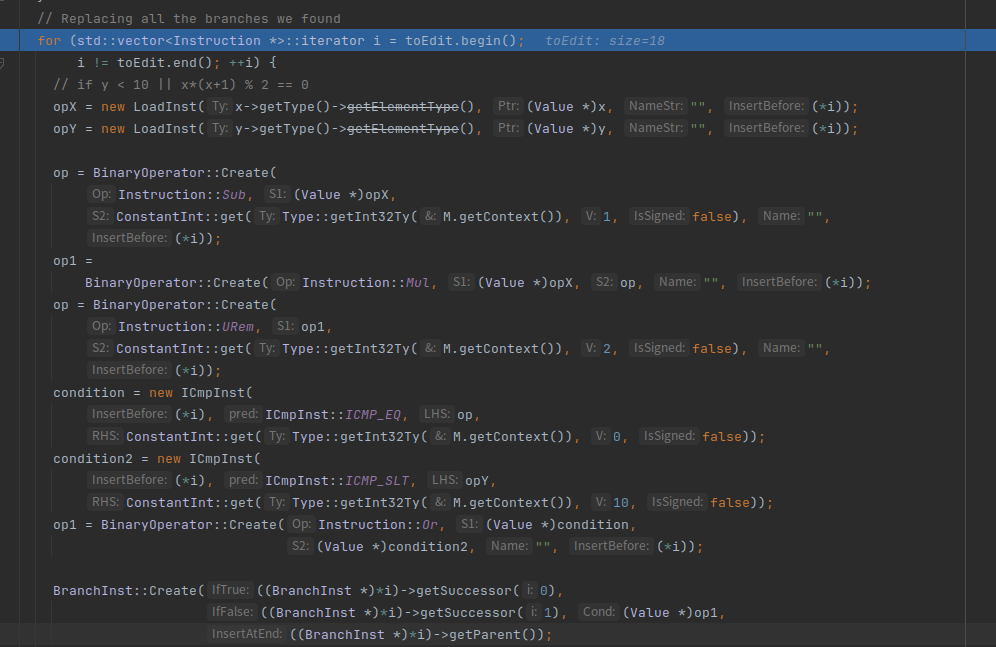

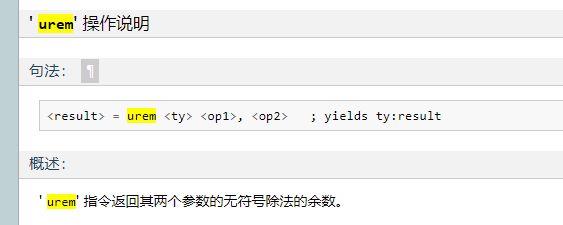
urem是取余
我们翻译成为伪代码 x*(x-1)%2和0作比较,y<10,两者结果or一下
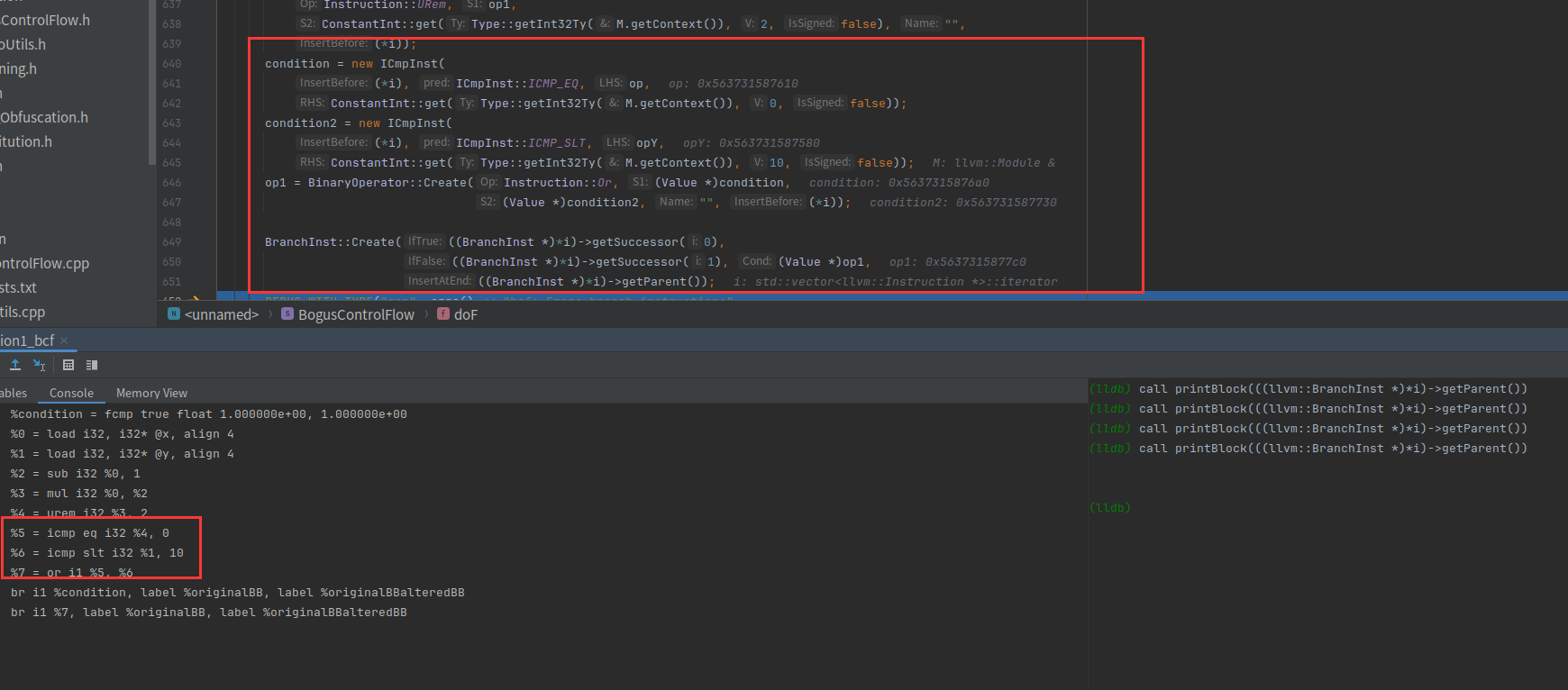
然后在br i1 %condition, label %originalBB, label %originalBBalteredBB后面插入br i1 %7, label %originalBB, label %originalBBalteredBB,用 x*(x-1)%2|y<10结果做条件跳转。
其实x和y在这里都是0,所以这个结果为1,还是恒跳转到originalBB
然后调用(*i)->eraseFromParent()把br i1 %condition, label %originalBB, label %originalBBalteredBB删了
接下来就是把%condition = fcmp true float 1.000000e+00, 1.000000e+00给删了
相当于替换了原先的条件跳转
后面就没有了,bcf执行完毕
21、调试ollvm-sub源码
先看一下原版ir和sub之后的ir
#include <stdio.h>
int main(int argc, char const *argv[])
{
int n = ((((argc + 8) & 16) | 0xF) ^ 33);
if (n >= 10) {
printf("hello ollvm:%d\r\n", n);
} else {
printf("hello whitebird\r\n");
}
return 0;
}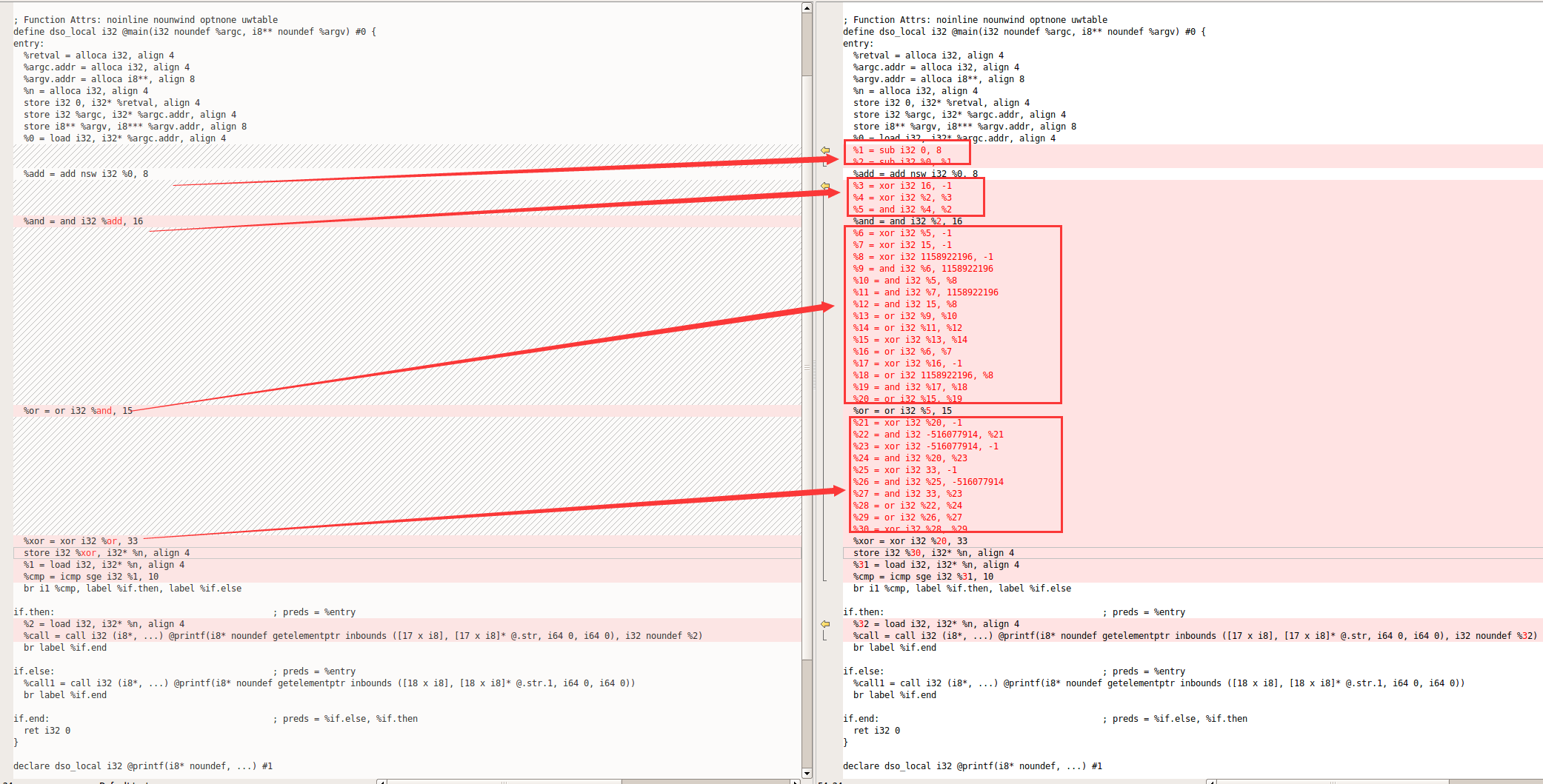
对加法、减法、布尔运算都进行了指令替换的操作
现在开始调试
-Xclang -load -Xclang /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -flegacy-pass-manager -mllvm -sub -emit-llvm -S /home/whitebird/test/hello_ollvm.c -o /home/whitebird/test/hello_ollvm_sub.ll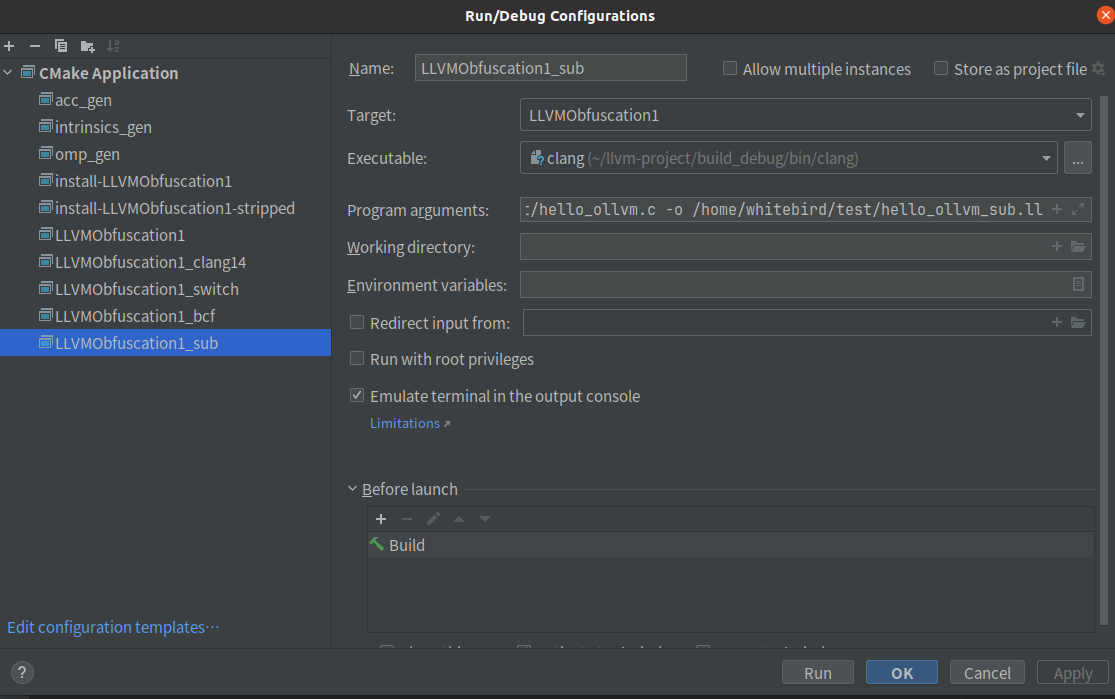
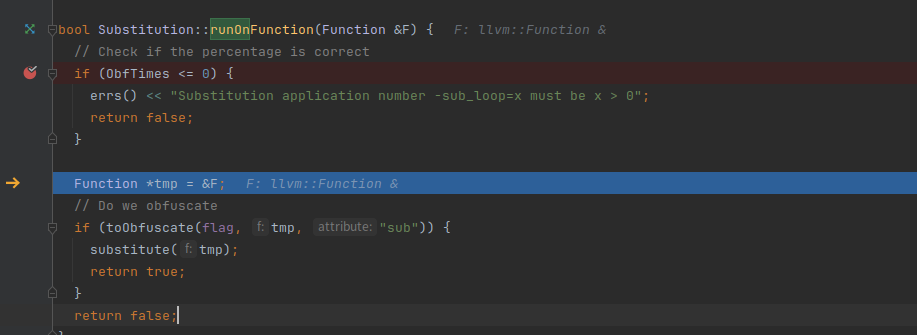
先检测ObfTimes,默认是1,然后检测sub是否开启,如果开启就执行substitute
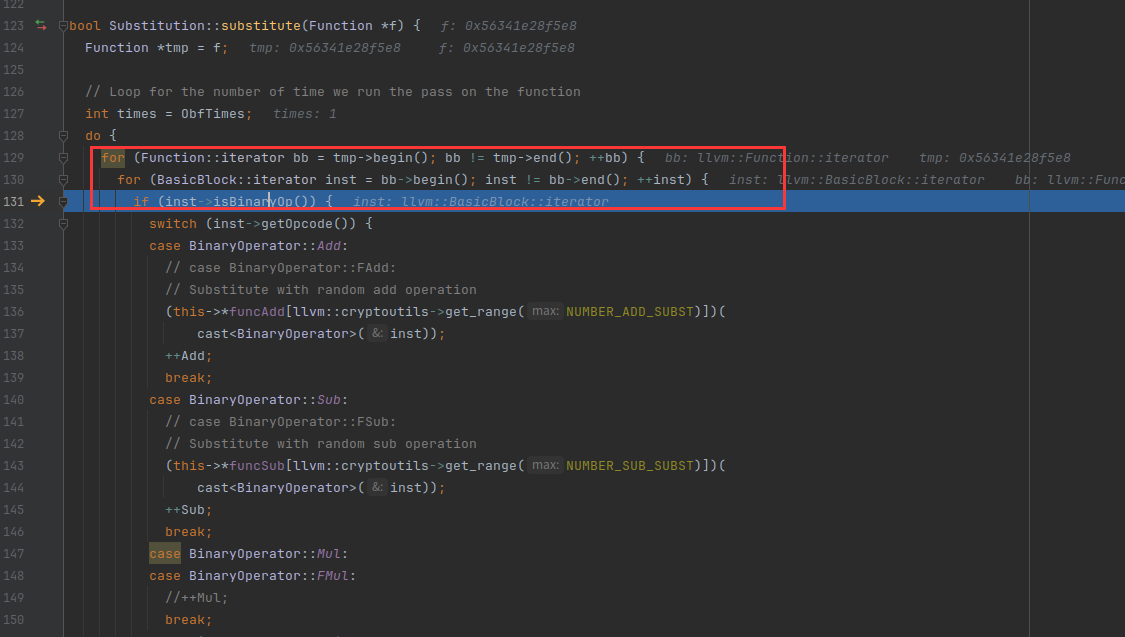
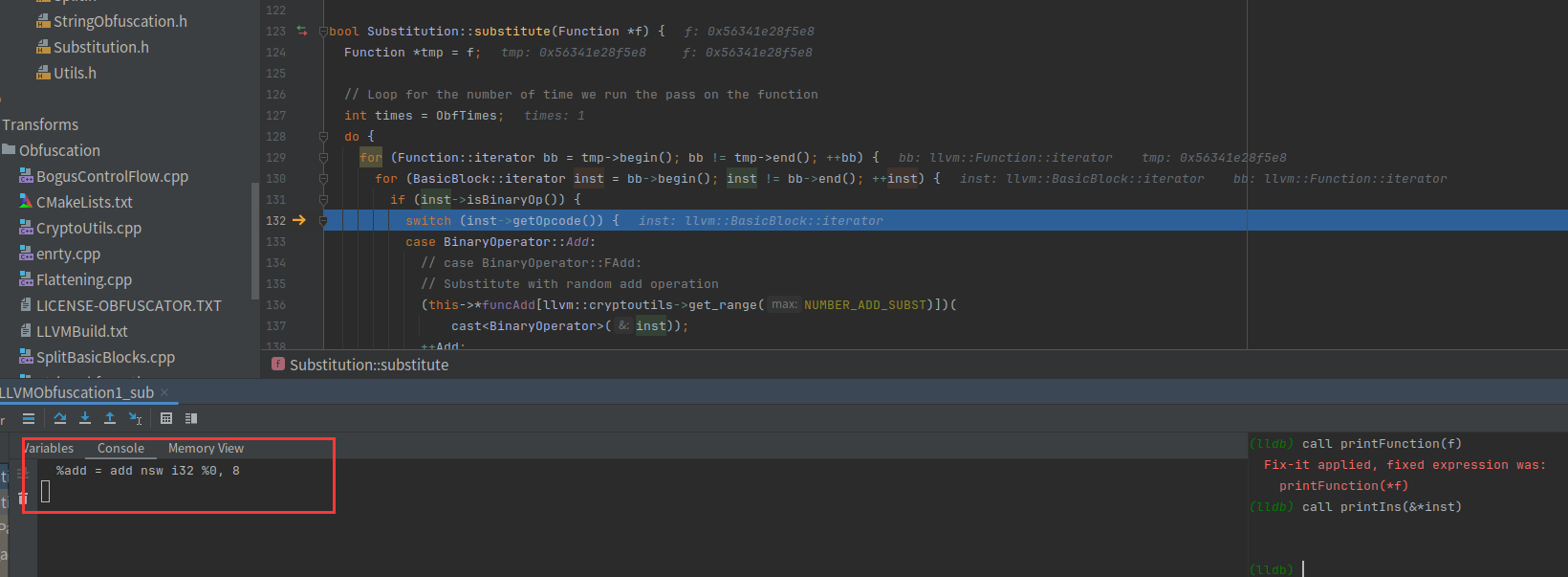
遍历每一条指令,找到符合条件的,也就是inst->isBinaryOp())
从定义中找到binaryOp的定义
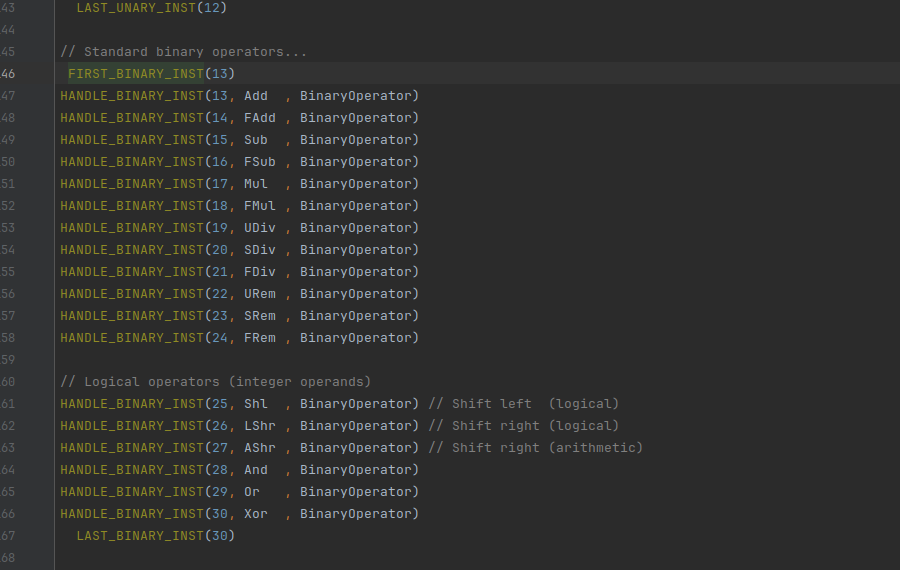
可以看到第一条进入处理的指令是%add = add nsw i32 %0, 8,add是binaryOp
根据binaryOp进行switch选择走对应的处理函数,不过源码中只实现了Add、Sub、And、Or、Xor对应的处理函数
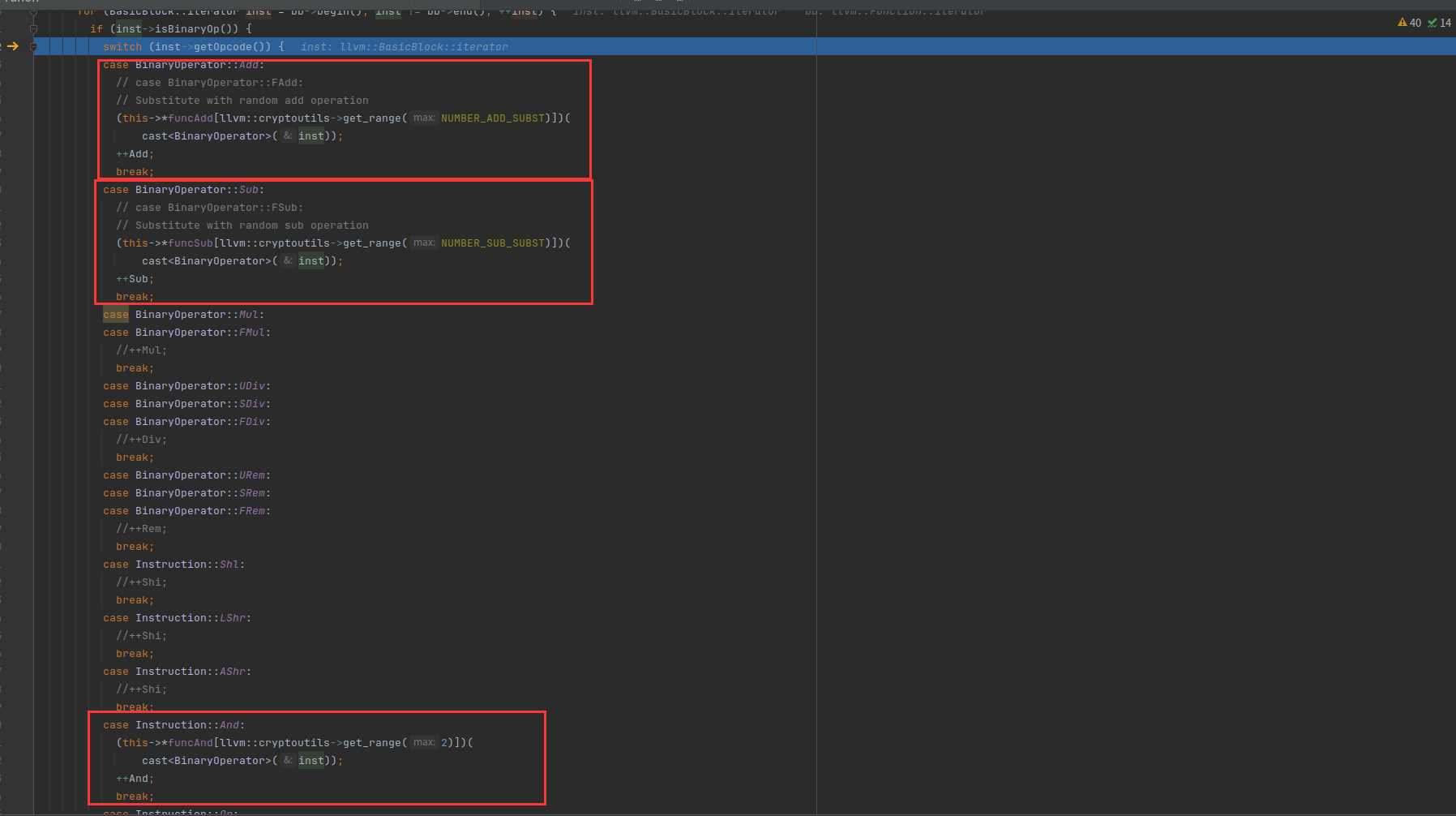
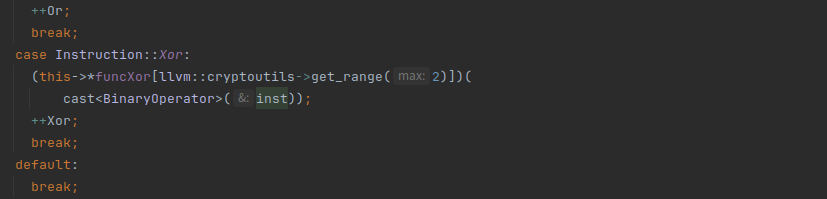
用函数指针进行调用,Add对应有四种指令替换,Sub有三种,And两种,Or两种,Xor两种
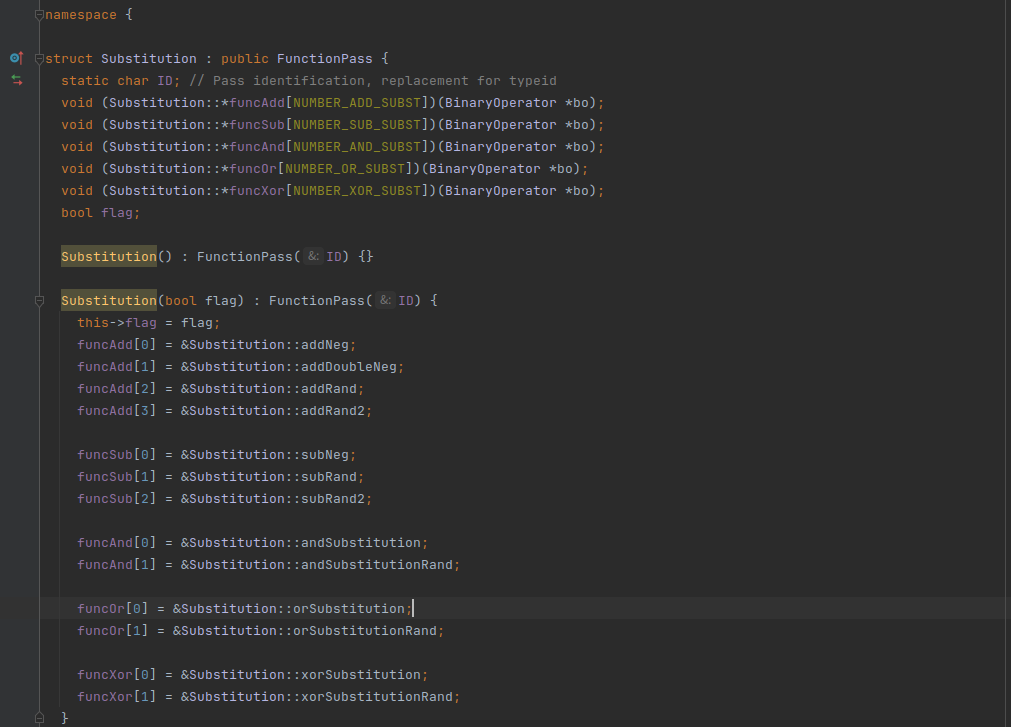
比如addNeg和addDoubleNeg的实现就不一样
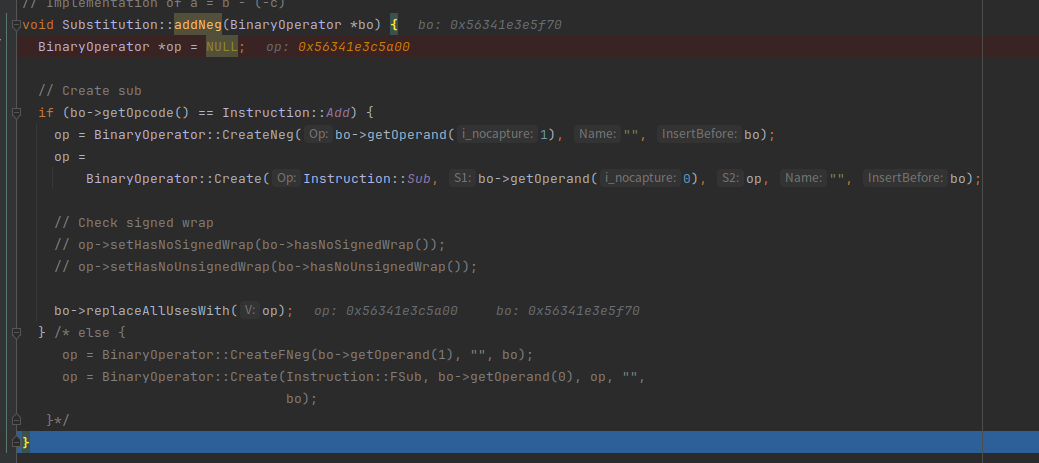
注释上写addNeg:a = b - (-c) addDoubleNeg:a = -(-b + (-c))
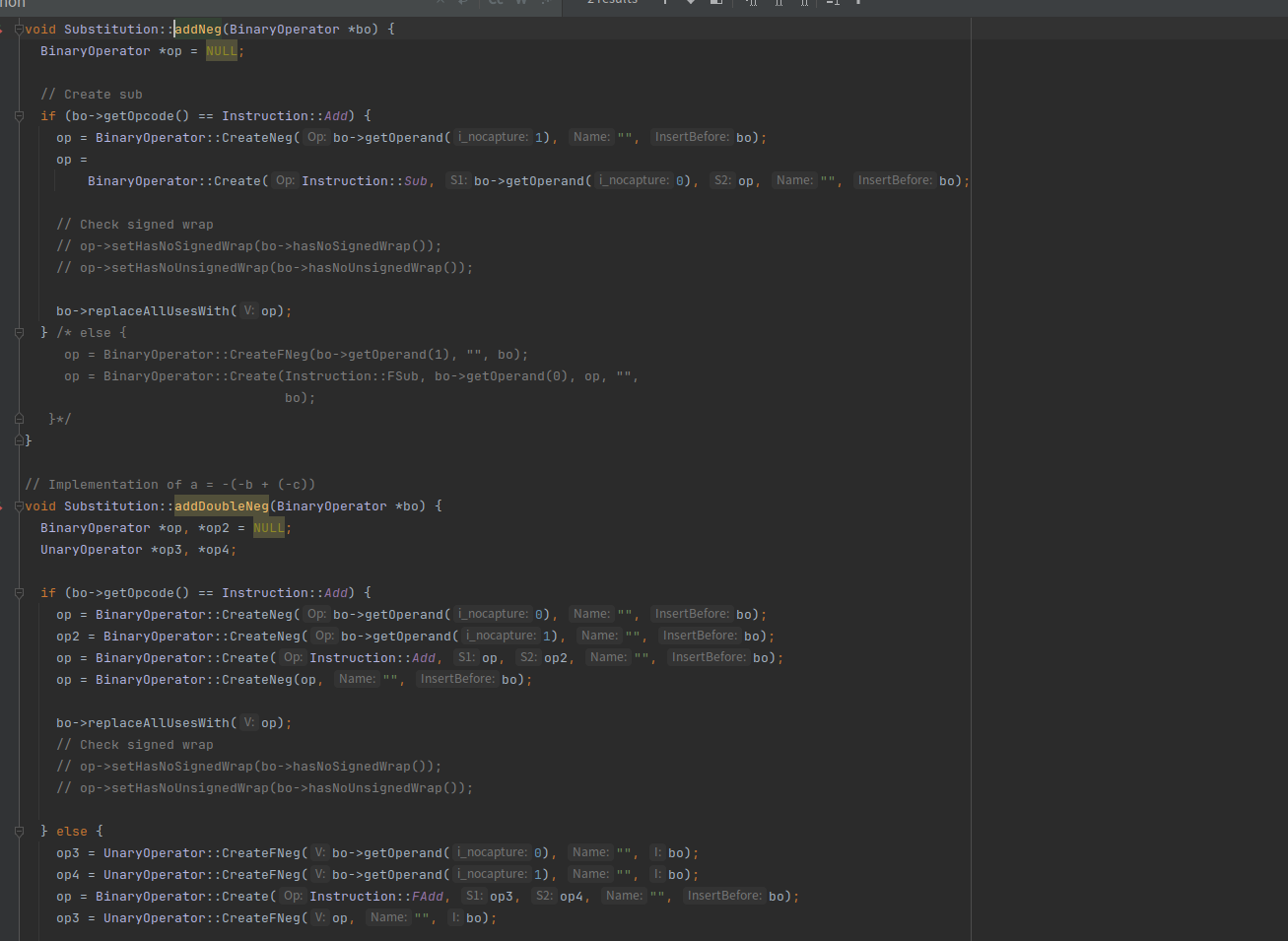
我们可以给这些函数都下个断点,然后继续调试
这里也是随机调用的
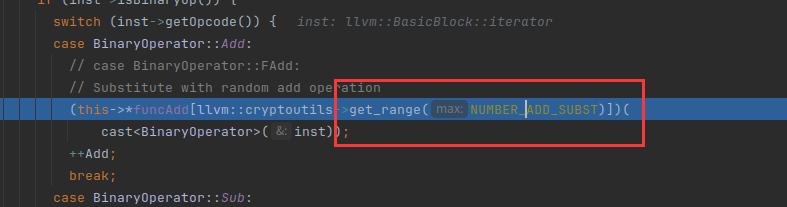
//对原始bo运算的第二个操作数求反,也就是%add = add nsw i32 %0, 8第二个操作数8求反
op = BinaryOperator::CreateNeg(bo->getOperand(1), "", bo);
//原运算的第一个bo操作数和求反运算的结果相减
op =BinaryOperator::Create(Instruction::Sub, bo->getOperand(0), op, "", bo);重点关注这两行,%0-(-8)
接着进入与操作
// Create NOT on second operand => ~c
op = BinaryOperator::CreateNot(bo->getOperand(1), "", bo);
// Create XOR => (b^~c)
BinaryOperator *op1 =
BinaryOperator::Create(Instruction::Xor, bo->getOperand(0), op, "", bo);
// Create AND => (b^~c) & b
op = BinaryOperator::Create(Instruction::And, op1, bo->getOperand(0), "", bo);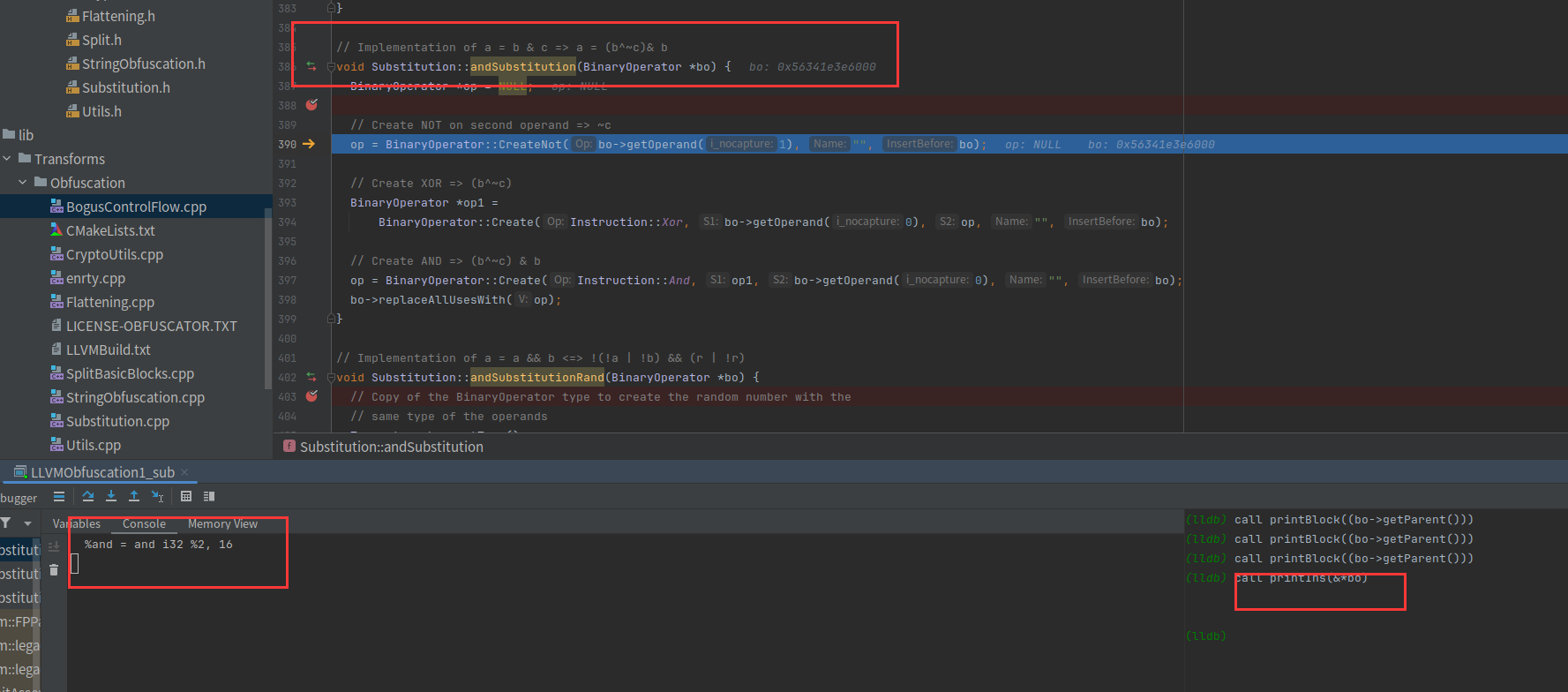
再接着就是or操作了,or操作替换的指令有点多,但是逻辑是a = b | c => a = (b & c) | (b ^ c)
xor指令的替换指令也比较多,逻辑是a = a ^ b <=> (a ^ r) ^ (b ^ r) <=> (!a && r || a && !r) ^ (!b && r || b && !r)
对于加上-mllvm -sub_loop其实和上面类似,不过因为我们第一次指令替换完引入的新指令中都有add、xor等,所以在第二次指令替换时,就会对这些add、xor指令也做替换,就会导致代码很大,有点类似于代码膨胀
22、调试ollvm-split源码
测试代码
#include <stdio.h>
int main(int argc, char const *argv[])
{
int n = ((((argc + 8) & 16) | 0xF) ^ 33);
if (n >= 10) {
printf("hello ollvm:%d\r\n", n);
} else {
printf("hello whitebird\r\n");
}
return 0;
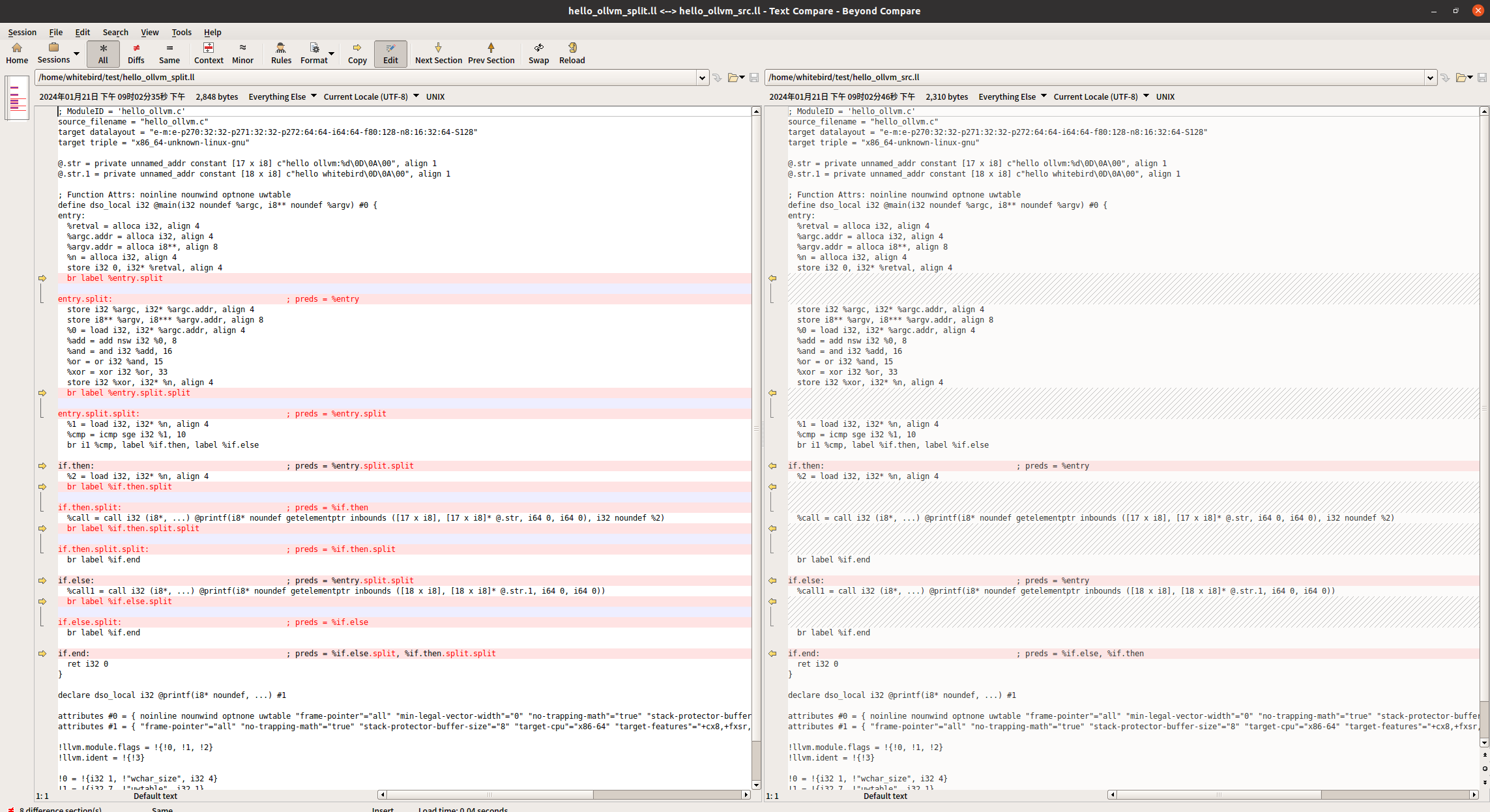
}对比原来的ir和split的ir
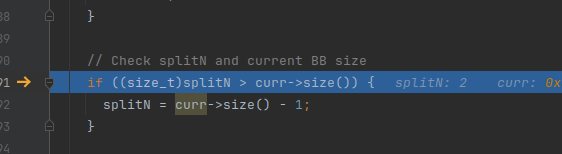
-Xclang -load -Xclang /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -flegacy-pass-manager -mllvm -split -emit-llvm -S /home/whitebird/test/hello_ollvm.c -o /home/whitebird/test/hello_ollvm_split.ll判断要分割的数量是否在1-10之间
默认值是2
保存所有的基本块

我们原来的ir就是4个基本块,现在取出第一个
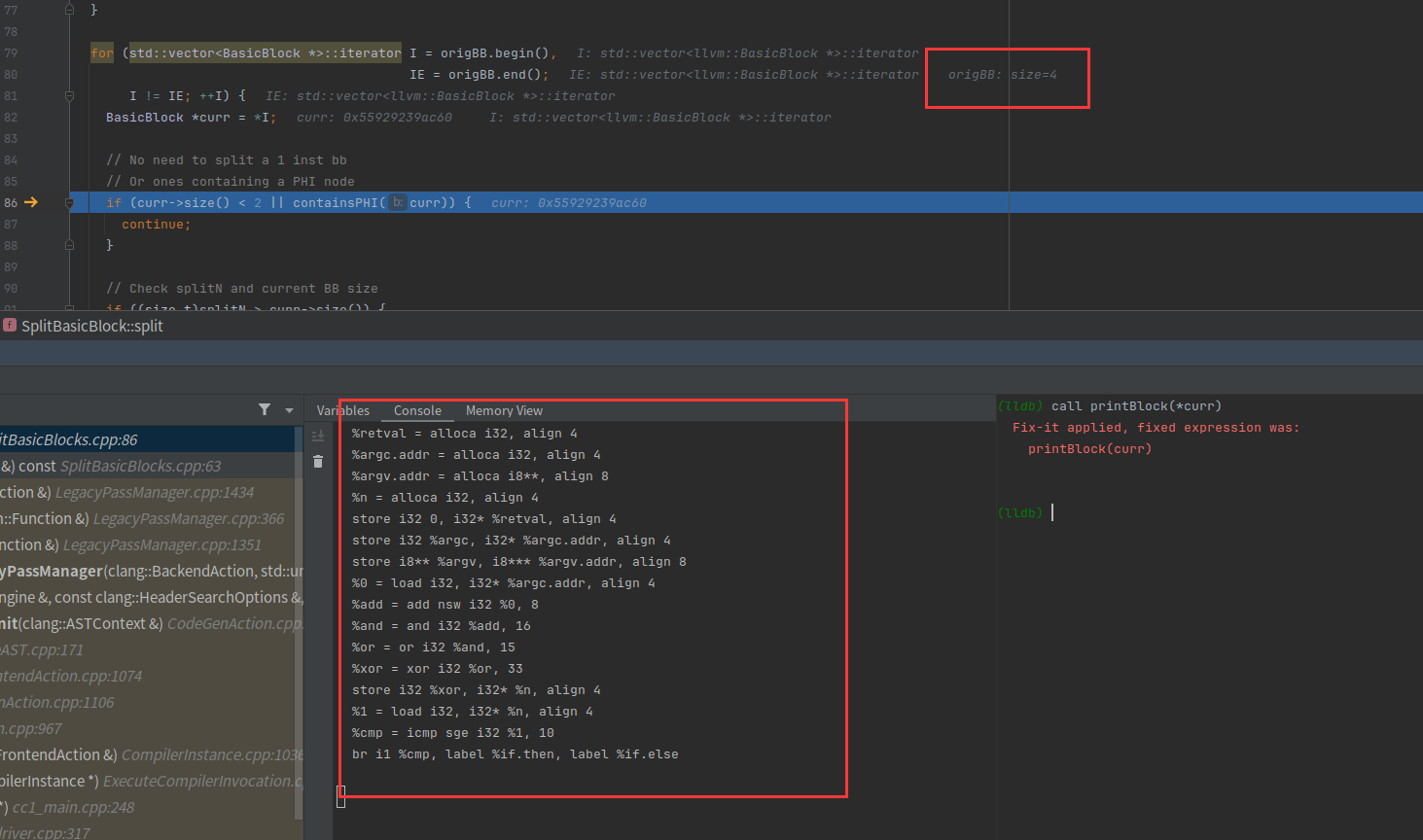
判断该基本块的大小是否小于2,可以看到我们有16行指令,也就是大小为16,如果小于2表示只有一行指令,自然不能分割。
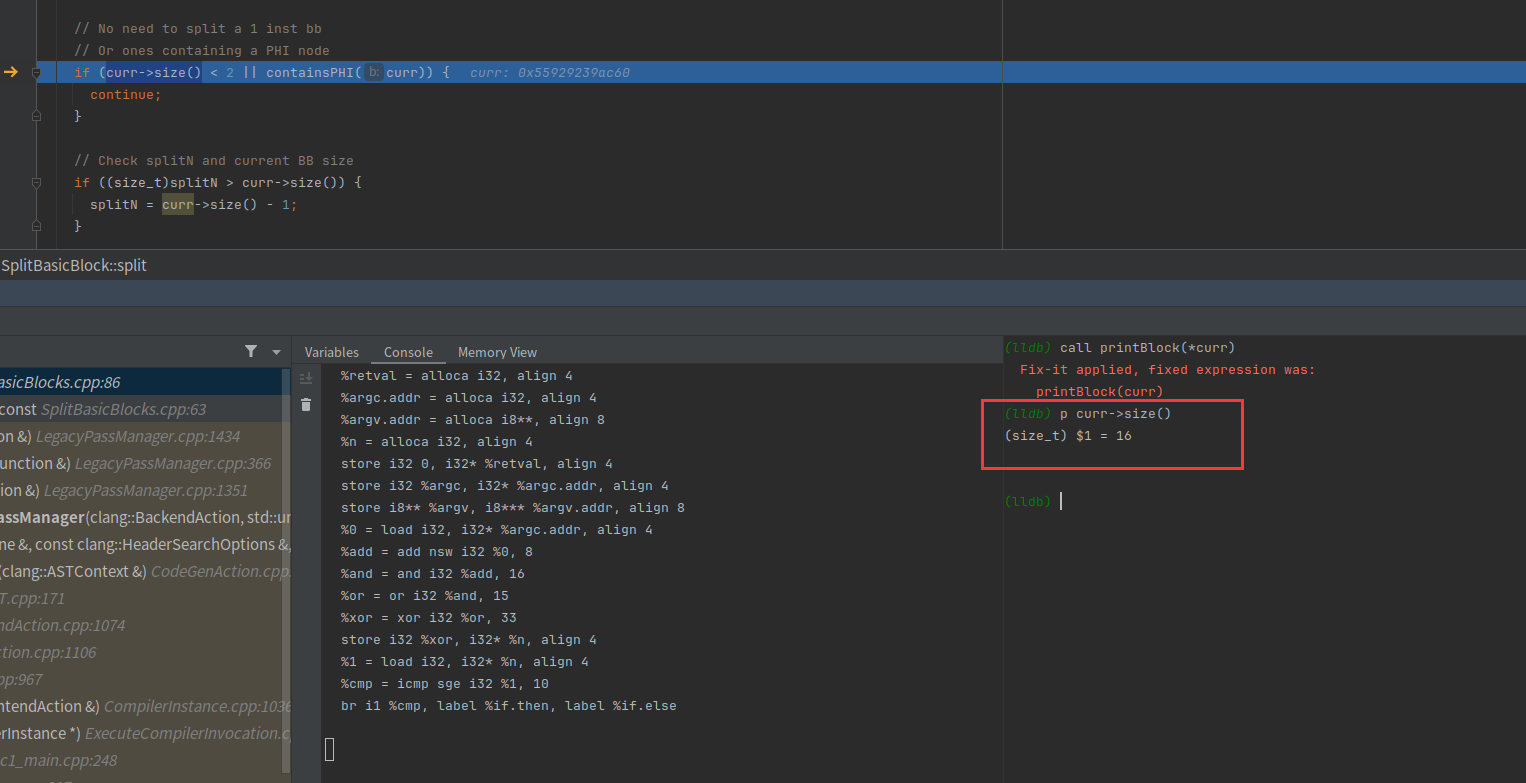
splitN太大就会被设置成基本块大小-1,防止不够分割
把1到基本块大小的数放到test中,然后再进行打乱
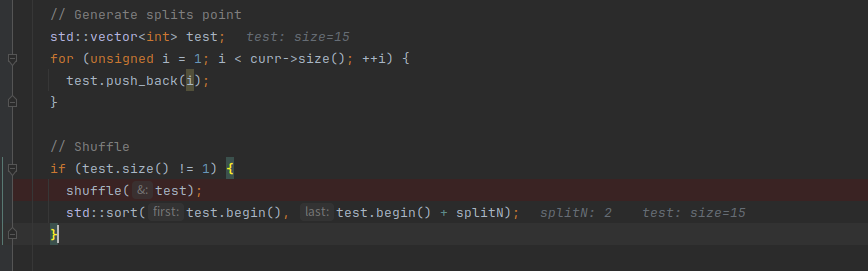
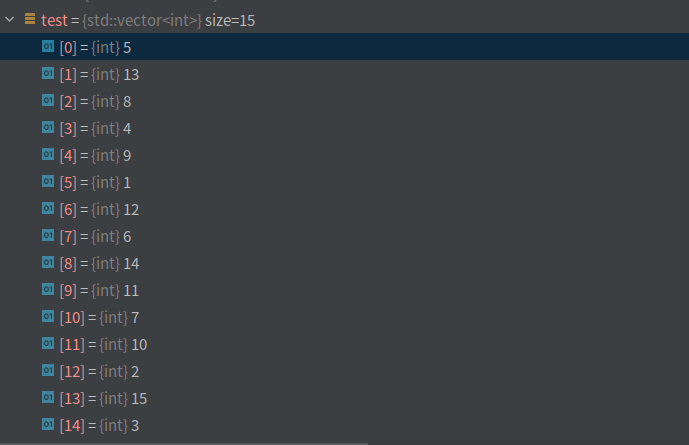
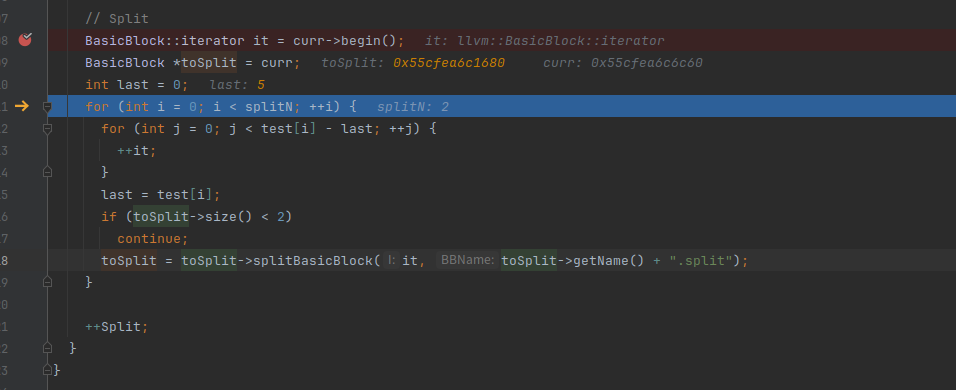
第一层循环是要分割的块数,是我们自己传入的,默认是2,第二层循环就是遍历指令找切割点
没分割的ir
%retval = alloca i32, align 4
%argc.addr = alloca i32, align 4
%argv.addr = alloca i8**, align 8
%n = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 %argc, i32* %argc.addr, align 4
store i8** %argv, i8*** %argv.addr, align 8
%0 = load i32, i32* %argc.addr, align 4
%add = add nsw i32 %0, 8
%and = and i32 %add, 16
%or = or i32 %and, 15
%xor = xor i32 %or, 33
store i32 %xor, i32* %n, align 4
%1 = load i32, i32* %n, align 4
%cmp = icmp sge i32 %1, 10
br i1 %cmp, label %if.then, label %if.elseBasicBlock::iterator it = curr->begin()得到ir的第一行指令
%retval = alloca i32, align 4test[i] - last为test[0]-0=5,所以分割点在store i32 %argc, i32* %argc.addr, align 4
再把last设置为test[i],用于下一次分割使用
toSplit = toSplit->splitBasicBlock(it, toSplit->getName() + “.split”)开始对基本块进行分割,下面是分割完第一次的toSplit
第二次分割时,test[1]为13,last为5,所以j小于8,我们的it移动到toSplit+8的位置
可以看到是 %1 = load i32, i32* %n, align 4
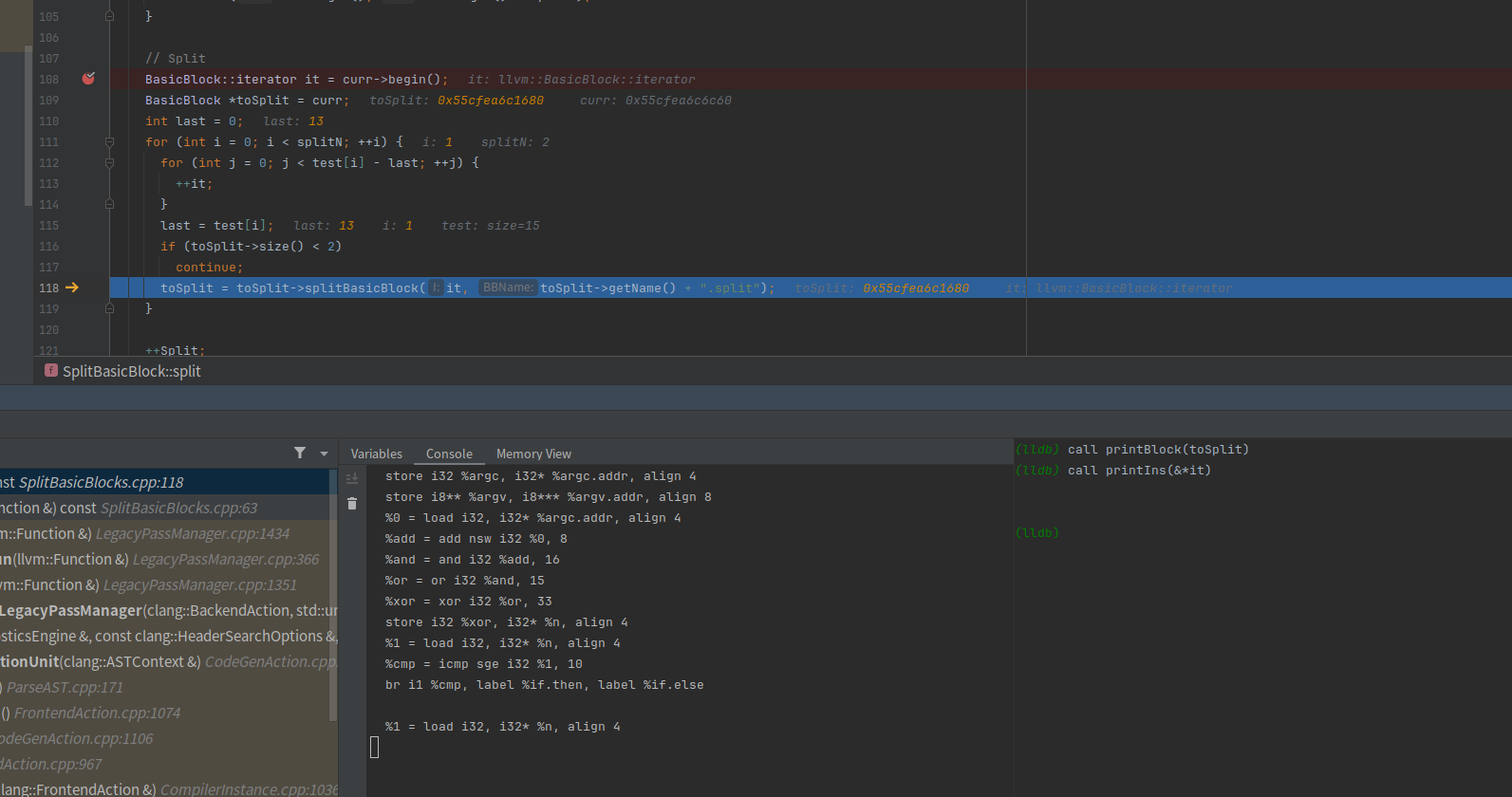
执行分割,还剩一个基本块里面有三条指令,此时外层循环2次分割已经达到,所以就跳出循环了
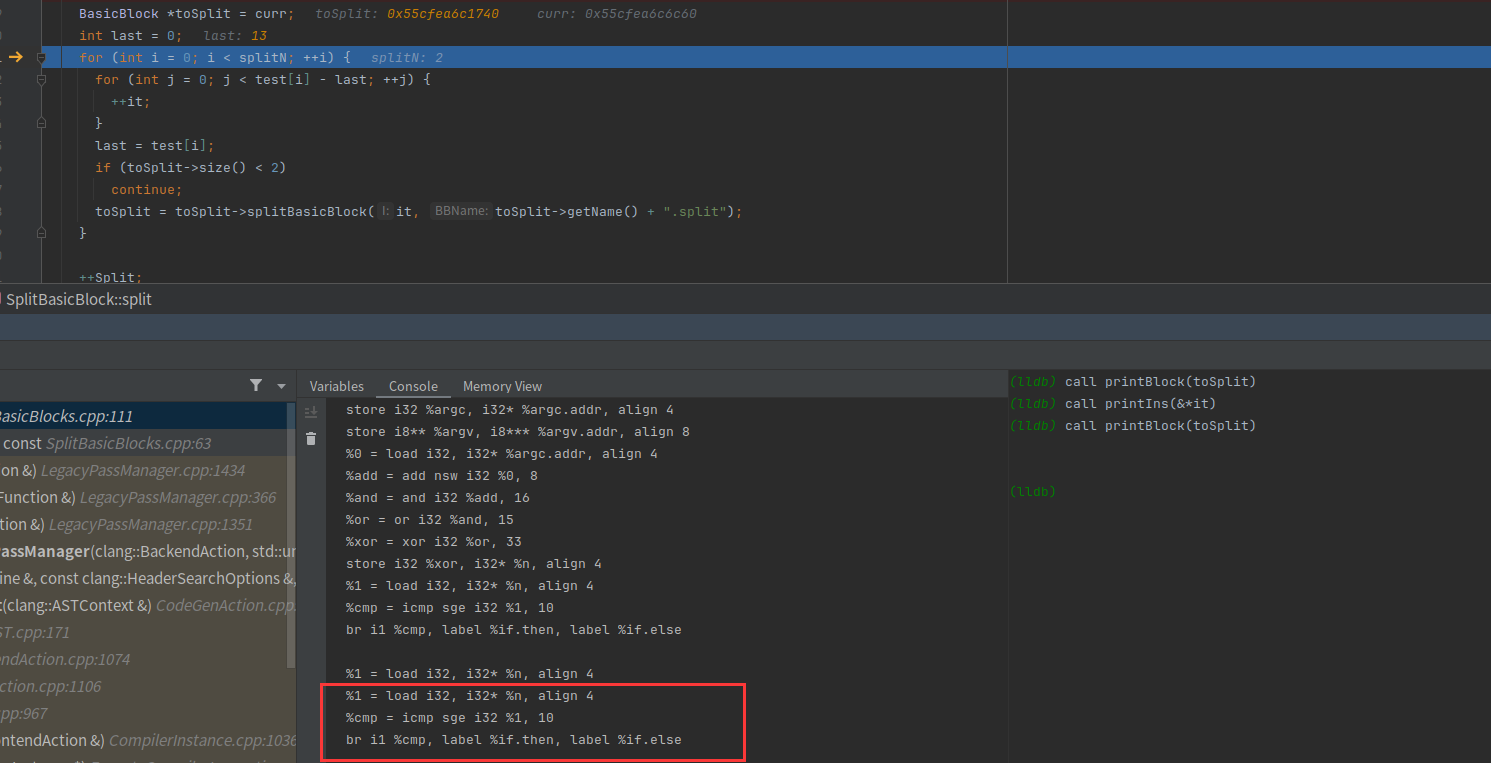
此时的整个源码的ir
========================================================================
entry:
%retval = alloca i32, align 4
%argc.addr = alloca i32, align 4
%argv.addr = alloca i8**, align 8
%n = alloca i32, align 4
store i32 0, i32* %retval, align 4
br label %entry.split
entry.split:
store i32 %argc, i32* %argc.addr, align 4
store i8** %argv, i8*** %argv.addr, align 8
%0 = load i32, i32* %argc.addr, align 4
%add = add nsw i32 %0, 8
%and = and i32 %add, 16
%or = or i32 %and, 15
%xor = xor i32 %or, 33
store i32 %xor, i32* %n, align 4
br label %entry.split.split
entry.split.split:
%1 = load i32, i32* %n, align 4
%cmp = icmp sge i32 %1, 10
br i1 %cmp, label %if.then, label %if.else
if.then:
%2 = load i32, i32* %n, align 4
%call = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([17 x i8], [17 x i8]* @.str, i64 0, i64 0), i32 noundef %2)
br label %if.end
if.else:
%call1 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([18 x i8], [18 x i8]* @.str.1, i64 0, i64 0))
br label %if.end
if.end:
ret i32 0
========================================================================每个新分割的块名都是原块名+.split,每多一次分割,.split也会多一次
取出第二个基本块开始分割
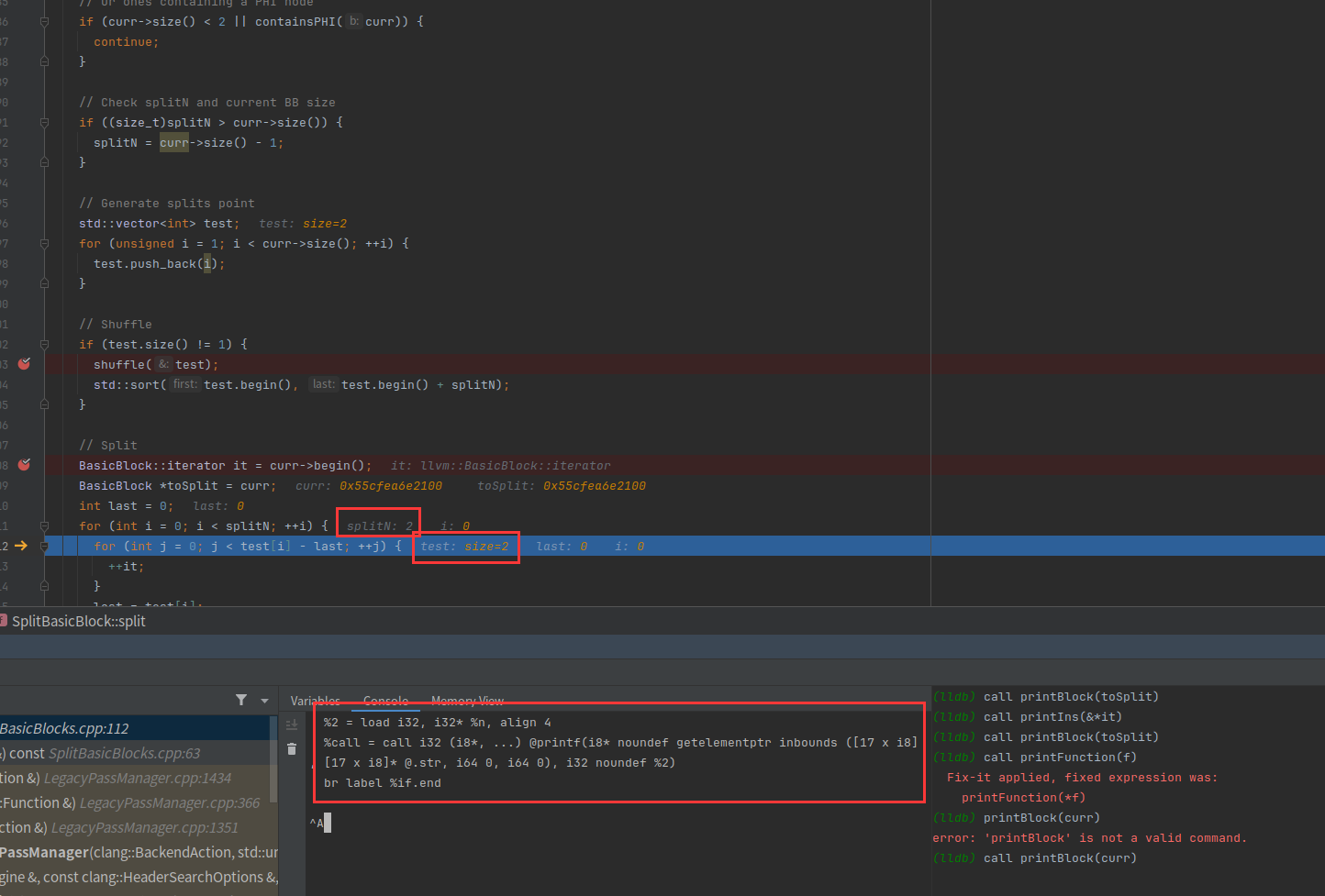
size大小是2,成员分别是1和2
第二次分割的基本块还是大于2,所以可以继续执行分割
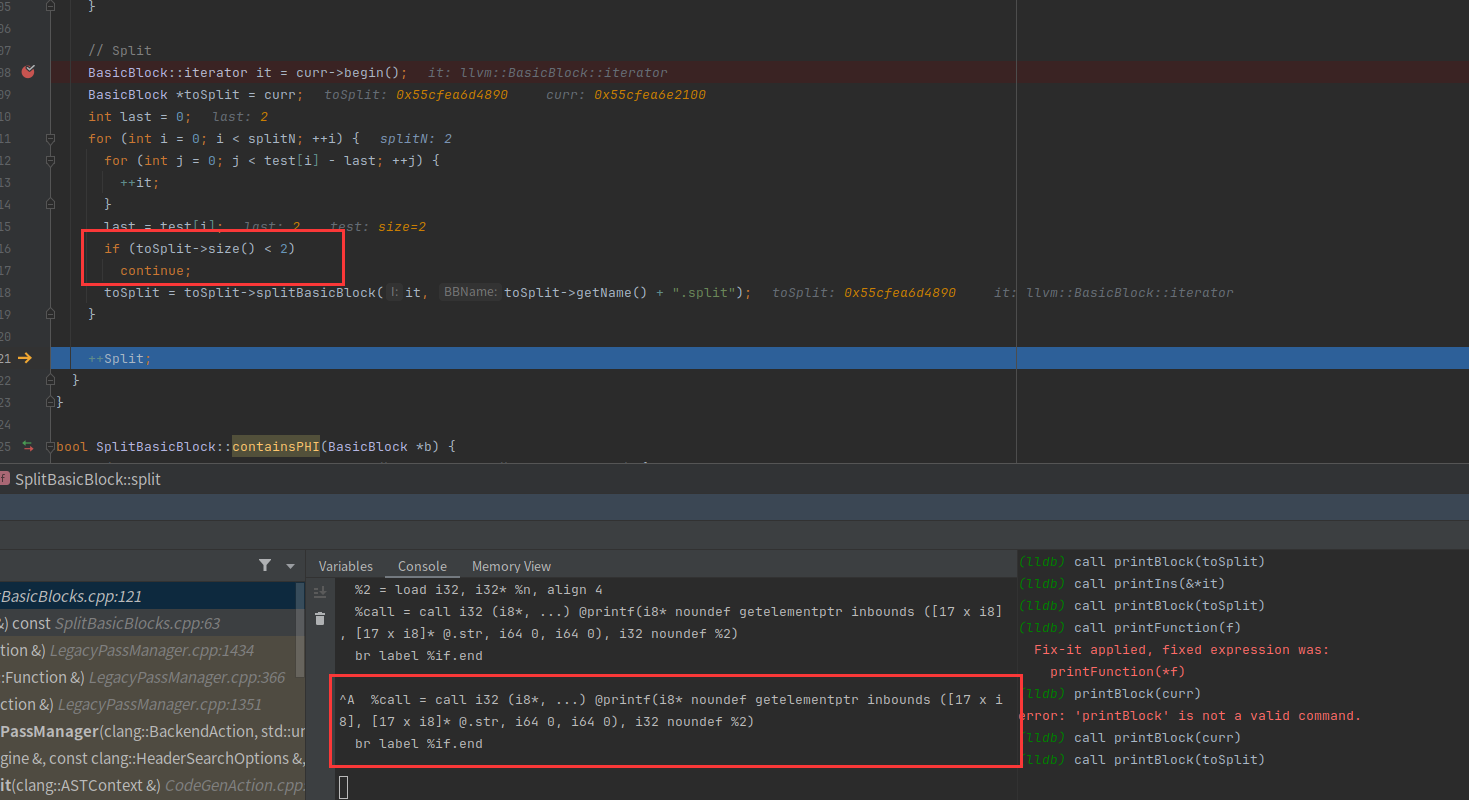
两次分割完的ir
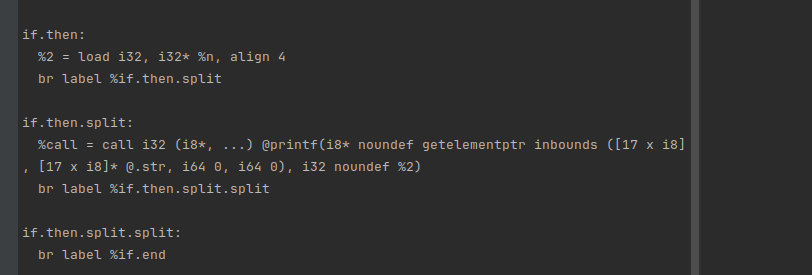
后面的过程类似,就不展开分析了
23、编写字符串加密pass
我们先准备一下pass的基本代码
Stringobf.h
#ifndef OLLVM_STRINGOBF_H
#define OLLVM_STRINGOBF_H
#include "llvm/ADT/Statistic.h"
#include "llvm/IR/Function.h"
#include "llvm/IR/Module.h"
#include "llvm/Pass.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Transforms/IPO.h"
#include "llvm/Transforms/Obfuscation/CryptoUtils.h"
#include "llvm/Transforms/Obfuscation/Utils.h"
#include "llvm/Transforms/Scalar.h"
#include "llvm/Transforms/Utils/Local.h" // For DemoteRegToStack and DemotePHIToStack
namespace llvm {
Pass *createStringObf(bool flag);
} // namespace llvm
#endif //OLLVM_STRINGOBF_HStringobf.cpp
#include "llvm/Transforms/Obfuscation/Stringobf.h"
#include "llvm/Transforms/Obfuscation/Utils.h"
using namespace llvm;
namespace {
struct StringObf : public FunctionPass {
static char ID; // Pass identification, replacement for typeid
bool flag;
StringObf() : FunctionPass(ID) {}
StringObf(bool flag) : FunctionPass(ID) { this->flag = flag; }
bool runOnFunction(Function &F){
if (toObfuscate(flag, &F, "enc_str")) {
}
return false;
};
};
}
char StringObf::ID = 0;
static RegisterPass<StringObf> X("enc_str", "String obf");
Pass *llvm::createStringObf(bool flag) {
return new StringObf(flag);
}enrty.cpp
static cl::opt<bool> StringEnc("enc_str", cl::init(false),
cl::desc("String encode"));
PM.add(createStringObf(StringEnc)); 剩下最重要的核心逻辑,如何把c++的加密方式在pass中实现
我们的功能是实现字符串加密,那么第一步应该是取得这个函数中的全部字符串,那么我们先看看ir中字符串的特征

可以看到,这个str是一个操作数,想要获取全部字符串,就得先遍历所有指令块中的操作数。然后再根据字符串的特征来进行过滤。
下面先看如何遍历所有指令块。
bool runOnFunction(Function &F){
if (toObfuscate(flag, &F, "enc_str")) {
//遍历函数中每一个基本块
for (BasicBlock &bb :F) {
//遍历基本块中每一条指令
// errs() << bb.getName() << "\r\n";
for(Instruction & ins :bb){
// errs() << ins << "\r\n";
//访问指令(Instruction)的操作数(operands)
for(Value *val:ins.operands()){
//相当于val但删除了任何指针强制转换
Value* stripOp=val->stripPointerCasts();
if(stripOp->getName().contains(".str")){
errs()<<ins<<"\n";
errs()<<*val<<"\n";
errs()<<*stripOp<<"\n";
}
}
}
}
}
return false;
};然后开始运行
-Xclang -load -Xclang /home/whitebird/llvm/cmake-build-debug/ollvm/lib/Transforms/Obfuscation/LLVMObfuscation1.so -flegacy-pass-manager -mllvm -enc_str -emit-llvm -S /home/whitebird/test/hello_ollvm.c -o /home/whitebird/test/hello_ollvm_enc_str.ll上面遍历了函数中的所有基本快,然后遍历所有指令块,然后遍历所有操作数,然后获取操作数的值,判断该操作数是否是一个字符串,并且打印这个指令块,操作数,以及取到的操作数的值,下面看看打印的结果
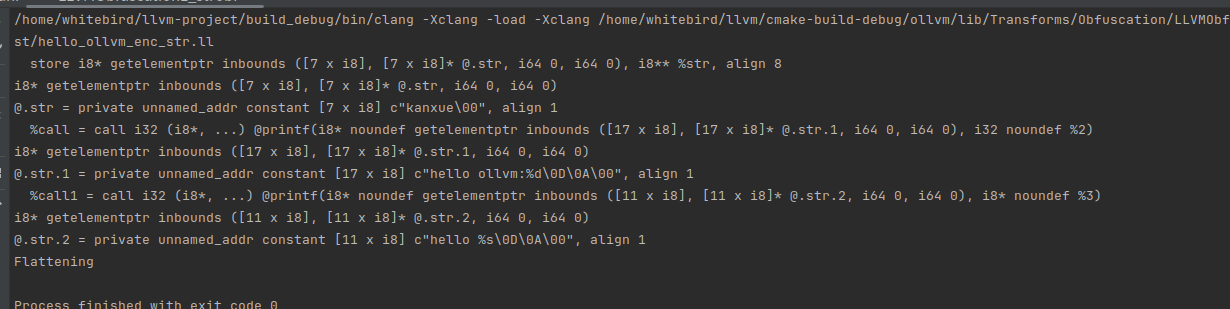
那么看到了,我们想获取的字符串是在stripOp中。那么接下来就把所有字符串全部获取出来并转换成string
//封装一个转换操作数值为字符串的函数
std::string ConvertOpToString(Value* op){
GlobalVariable* globalVar= dyn_cast<GlobalVariable>(op);
if(!globalVar){
errs()<<"dyn cast gloabl err";
return "";
}
ConstantDataSequential* cds=dyn_cast<ConstantDataSequential>(globalVar->getInitializer());
if(!cds){
errs()<<"dyn cast constant data err";
return "";
}
return cds->getRawDataValues().str();
}之前看到的字符串的ir代码看到所有字符串都是全局的,所以要先转换成全局的对象,然后再转换成数值。然后看这里的打印结果
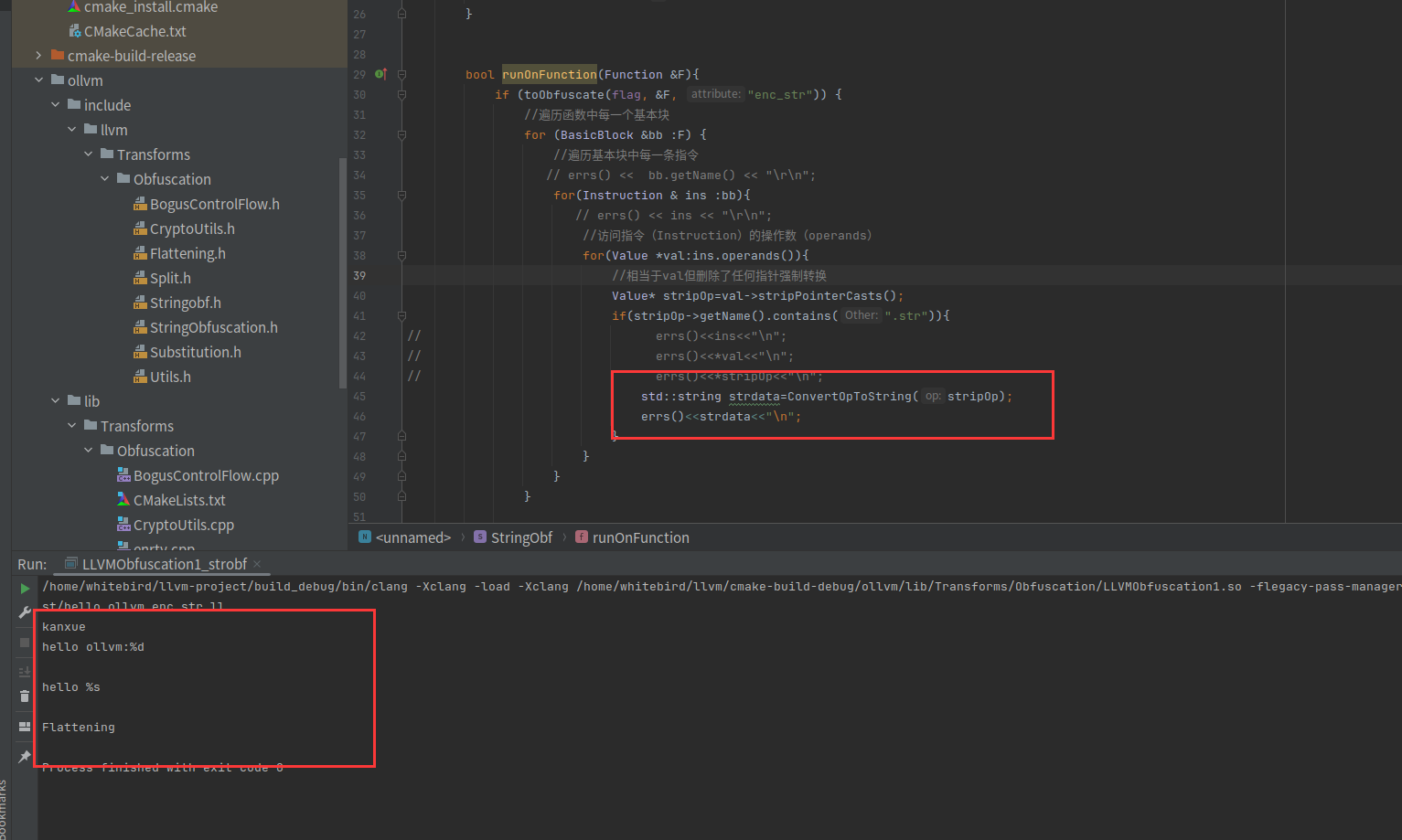
获取到所有的字符串了之后。接下来。我们要先把这个字符串加密,然后再用插入指令块来进行解密。下面继续完善,先把之前搞好的加密算法迁移进来。
uint8_t randkey=0;
randkey=llvm::cryptoutils->get_uint8_t();
for(int i=0;i<strdata.size();i++) {
strdata[i]^=randkey;
}
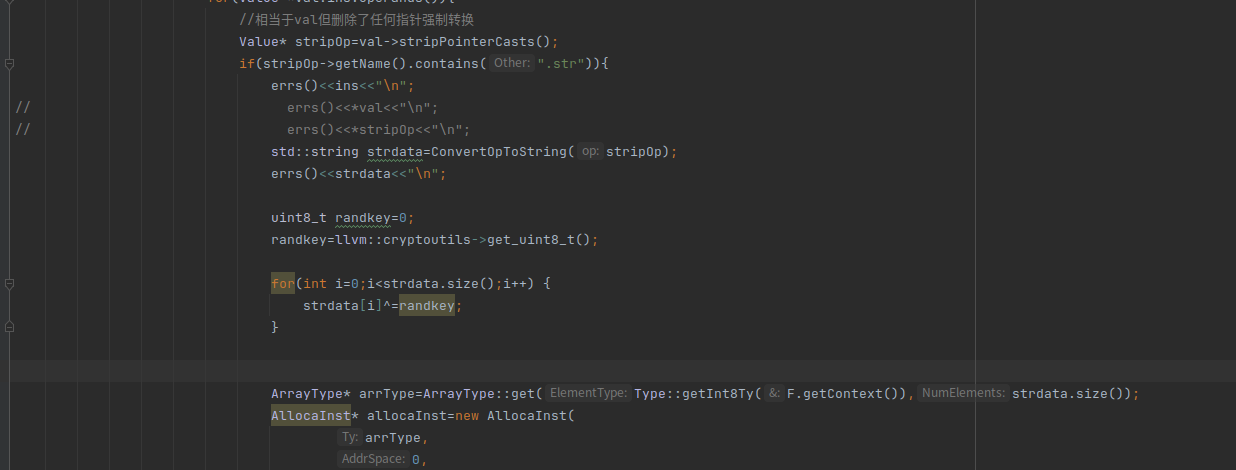
接下来的处理就是插入指令块来对这个加密数据strdata进行解密还原处理。
我们想要处理这个加密后的数据,首先要申请内存来存放这个加密后的数据,然后再对加密后的数据遍历进行还原。
//创建一个LLVM数组类型 (ArrayType),其元素类型为i8(8位整数,通常用于表示字符)和指定的大小(strdata.size())
ArrayType* arrType=ArrayType::get(Type::getInt8Ty(F.getContext()),strdata.size());
//创建一个LLVM分配指令 (AllocaInst),用于在堆栈上保留内存以存储数组
AllocaInst* allocaInst=new AllocaInst(
arrType,
0,
llvm::ConstantInt::get(Type::getInt32Ty(F.getContext()), strdata.size()),
Twine(stripOp->getName() + ".array"),
&ins
);
//创建一个Twine对象,它是一个轻量级字符串表示形式
Twine* twine_bitcast = new Twine(stripOp->getName() + ".bitcast");
//创建一个位广播指令(BitCastInst),用于转换指针类型。它将指针“allocaInst”转换为“i8*”类型的指针(指向8位整数的指针,通常用于表示字节地址)
BitCastInst* bitCastInst_str = new BitCastInst(allocaInst, Type::getInt8PtrTy(F.getParent()->getContext()), twine_bitcast->str(), &ins);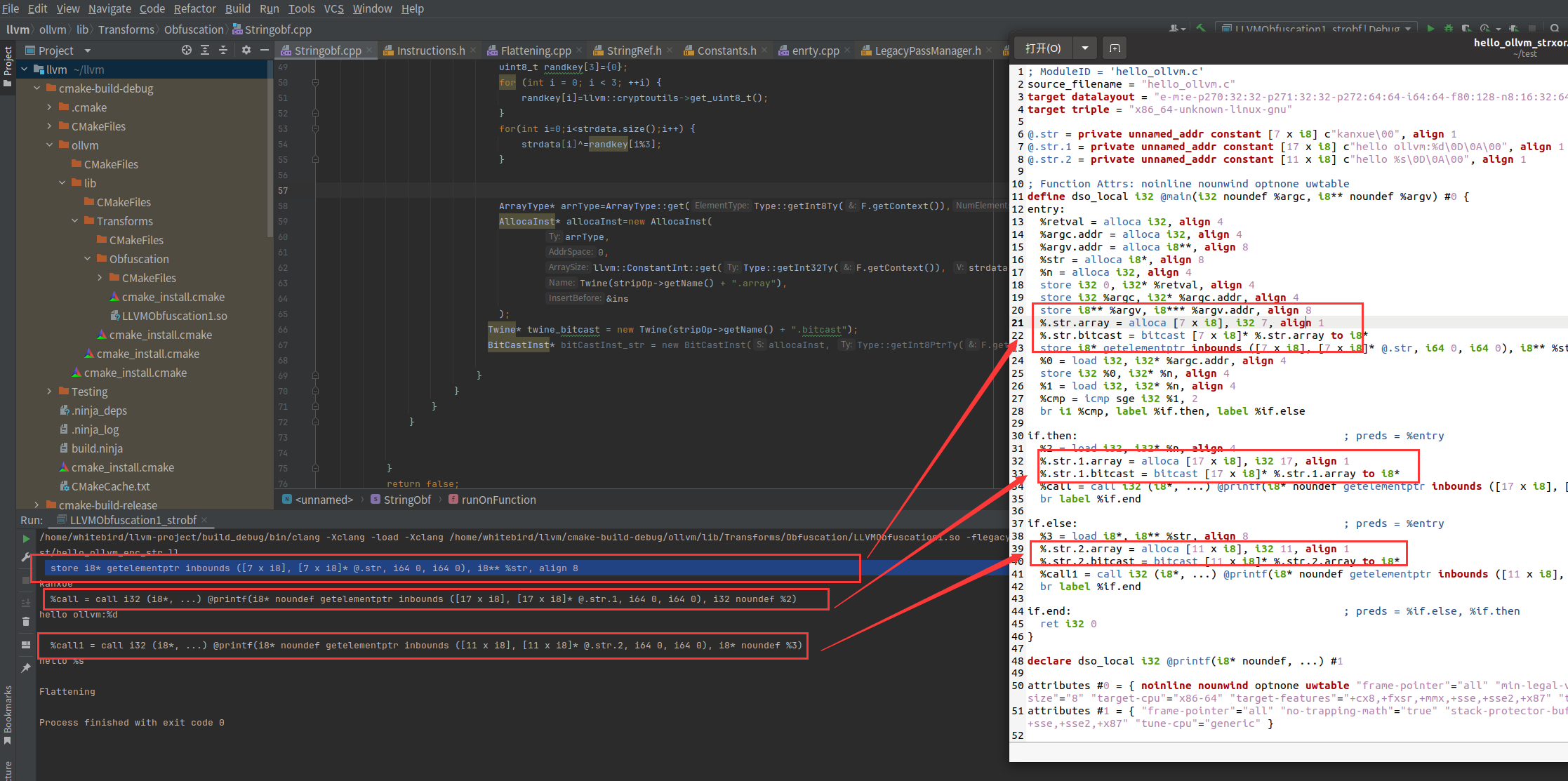
接下来就是解密的逻辑处理
bool runOnFunction(Function &F){
IRBuilder<> builder(F.getContext());
if (toObfuscate(flag, &F, "enc_str")) {
//遍历函数中每一个基本块
for (BasicBlock &bb :F) {
//遍历基本块中每一条指令
// errs() << bb.getName() << "\r\n";
for(Instruction & ins :bb){
// errs() << ins << "\r\n";
//访问指令(Instruction)的操作数(operands)
for(Value *val:ins.operands()){
//相当于val但删除了任何指针强制转换
Value* stripOp=val->stripPointerCasts();
GlobalVariable* globalVar= dyn_cast<GlobalVariable>(stripOp);
if(stripOp->getName().contains(".str")){
errs()<<ins<<"\n";
// errs()<<*val<<"\n";
// errs()<<*stripOp<<"\n";
std::string strdata=ConvertOpToString(stripOp);
errs()<<strdata<<"\n";
uint8_t randkey=0;
randkey=llvm::cryptoutils->get_uint8_t();
for(int i=0;i<strdata.size();i++) {
strdata[i]^=randkey;
}
ArrayType* arrType=ArrayType::get(Type::getInt8Ty(F.getContext()),strdata.size());
AllocaInst* allocaInst=new AllocaInst(
arrType,
0,
llvm::ConstantInt::get(Type::getInt32Ty(F.getContext()), strdata.size()),
Twine(stripOp->getName() + ".array"),
&ins
);
Twine* twine_bitcast = new Twine(stripOp->getName() + ".bitcast");
BitCastInst* bitCastInst_str = new BitCastInst(allocaInst, Type::getInt8PtrTy(F.getParent()->getContext()), twine_bitcast->str(), &ins);
ConstantInt* constantInt_xor_key = ConstantInt::get(Type::getInt8Ty(F.getContext()), randkey);
AllocaInst* allocaInst_xor_key = new AllocaInst(
Type::getInt8Ty(F.getContext()),
0,
nullptr,
Twine(stripOp->getName() + ".key"),
&ins
);
StoreInst* storeInst1_xor_key = new StoreInst(constantInt_xor_key, allocaInst_xor_key,&ins);
LoadInst* loadInst_xor_key = new LoadInst(Type::getInt8Ty(F.getContext()),allocaInst_xor_key, "",&ins);
for (int i = 0; i < strdata.size(); ++i) {
//创建了一个表示8位整数值i的常量整数指令
ConstantInt* index = ConstantInt::get(Type::getInt8Ty(F.getContext()), i);
//创建一个 GetElementPtrInst 指令,用于从数组中取元素
GetElementPtrInst* getElementPtrInst = GetElementPtrInst::CreateInBounds(
arrType,
allocaInst,
index,
Twine("")
);
getElementPtrInst->insertBefore(&ins);
//创建一 ConstantInt实例,表示一个8位整数的常量,其值是 strdata[i] 中的一个字符的 ASCII 值,将每个字符转换为相应的ASCII
ConstantInt* enc_ch = ConstantInt::get(Type::getInt8Ty(F.getContext()), strdata[i]);
BinaryOperator* xor_inst = BinaryOperator::CreateXor(enc_ch, loadInst_xor_key);
//这里有bug,在llvm14上用不了,还没有修好bug
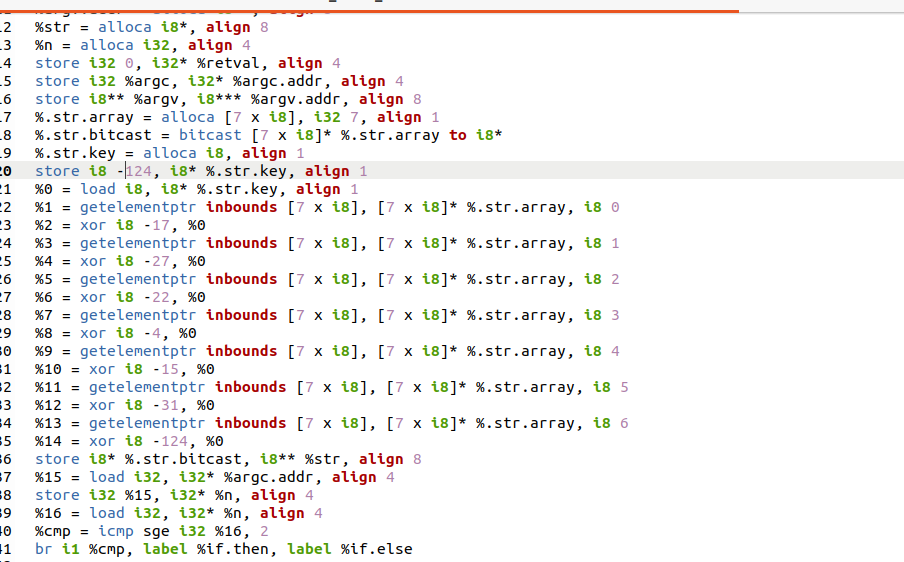
StoreInst* storeInst = new StoreInst(xor_inst, getElementPtrInst);
storeInst->insertAfter(xor_inst);
}
val->replaceAllUsesWith(bitCastInst_str);
globalVar->eraseFromParent();
}
}
}
}
}
return false;
};
24、移植OLLVM到NDK中
1、将ollvm移植到llvm源码中
2、将llvm编译:Release版本
3、下载AndroidNDK,将编译的Relase版本的bin,lib,include目录复制到AndroidNDK的android-ndk/toolchains/llvm/prebuilt/linux-86_64/目录下
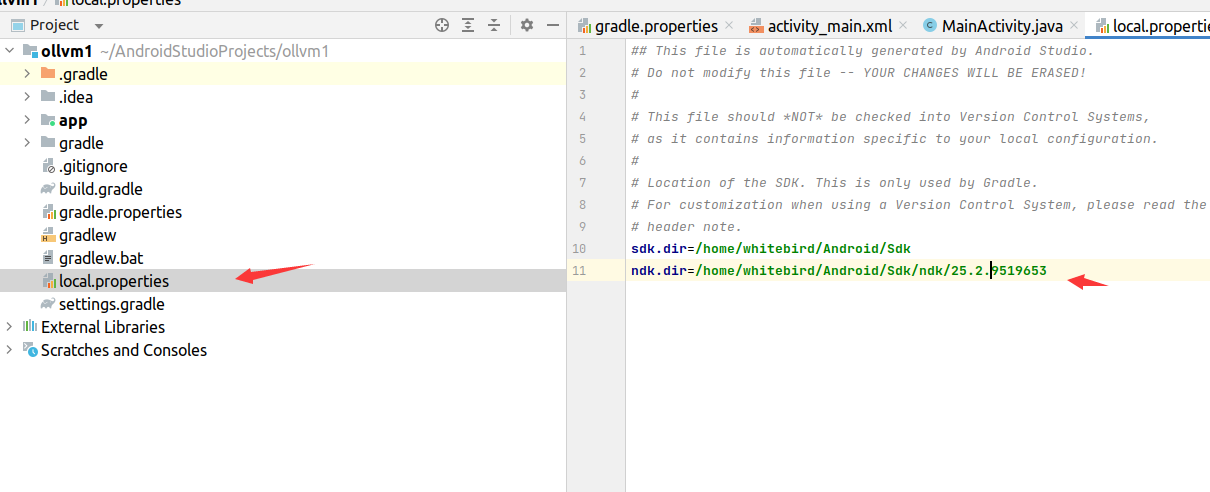
 4、Android studio项目,在Gradle Scripts目录下的local.properties文件中添加ndk.dir=步骤3中配置的ndk路径
4、Android studio项目,在Gradle Scripts目录下的local.properties文件中添加ndk.dir=步骤3中配置的ndk路径
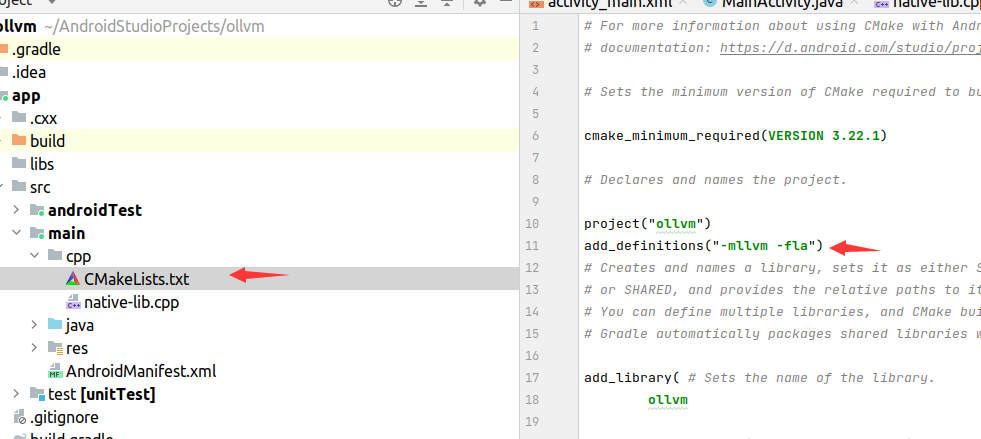
5、在cpp目录下的CMakeLists.txt中添加 add_definitions(“-mllvm -fla”)
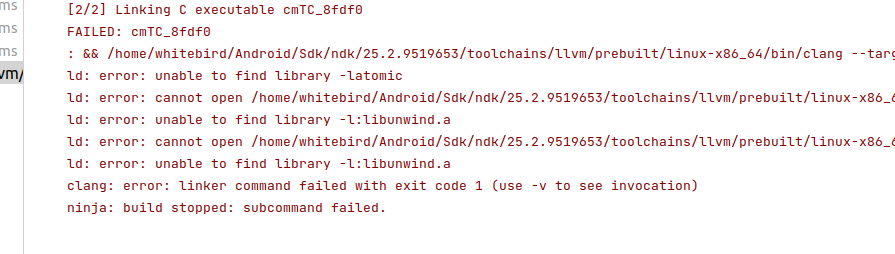
经过覆盖后,打开AS编译项目会报找不到 libunwind 等库的错,原因就是缺少lib/clang/…这些库
将 lib64 里的 clang 复制到 lib 目录
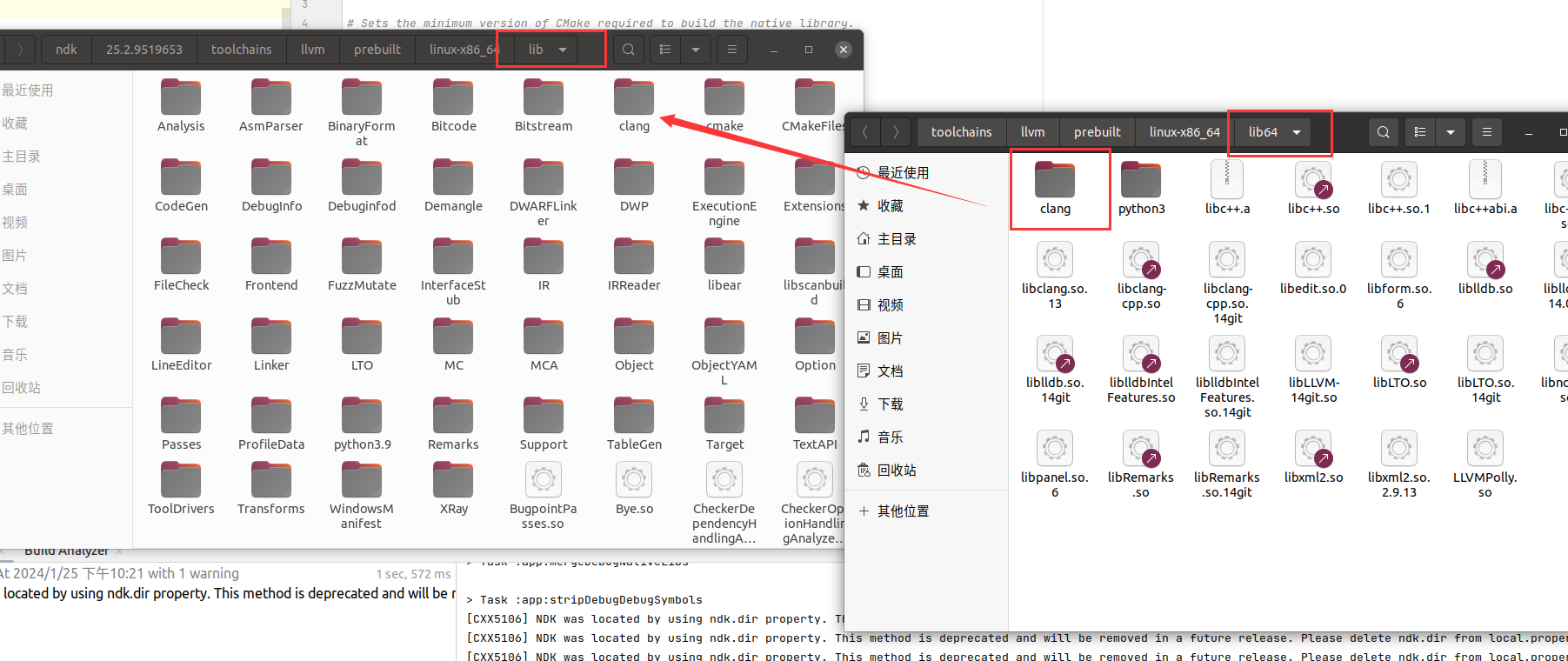
把名字改成与clang版本相同
现在把编译好的app拿出来进行分析
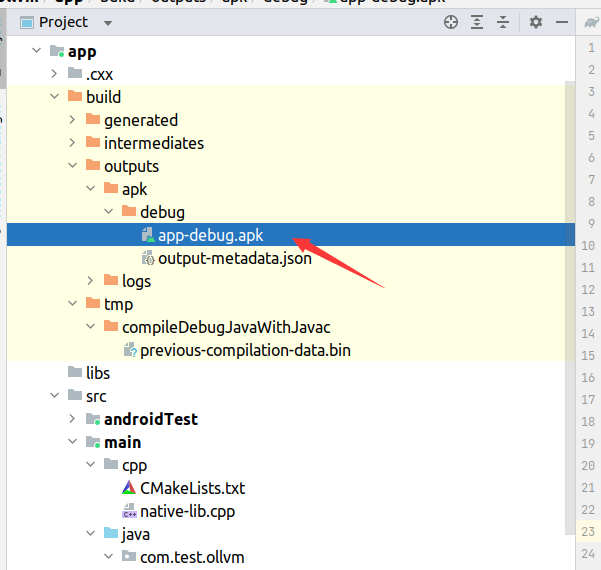
放到ida发现没效果,换了另外一个方法
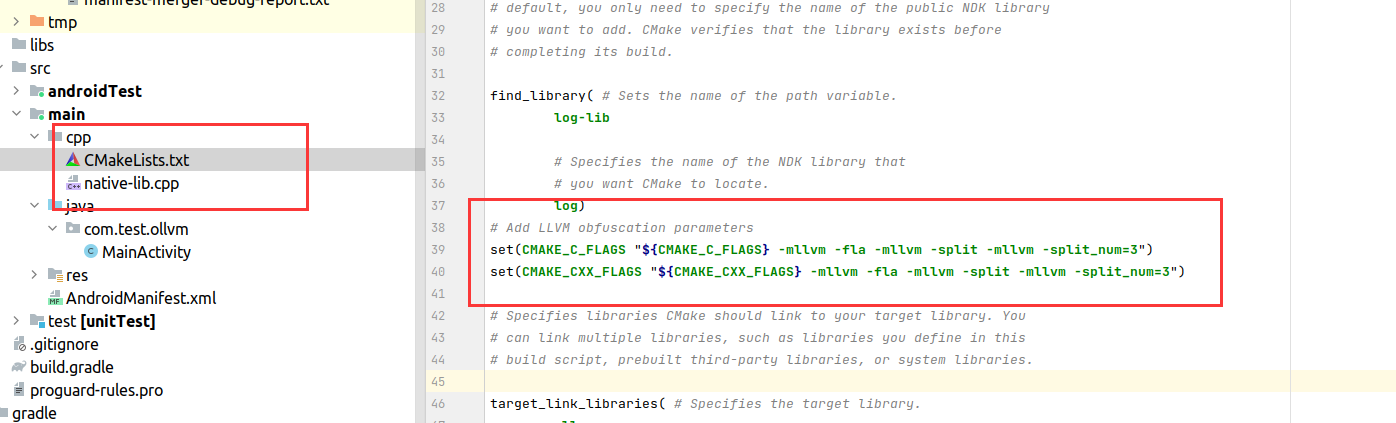
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mllvm -fla -mllvm -split -mllvm -split_num=3")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -mllvm -fla -mllvm -split -mllvm -split_num=3")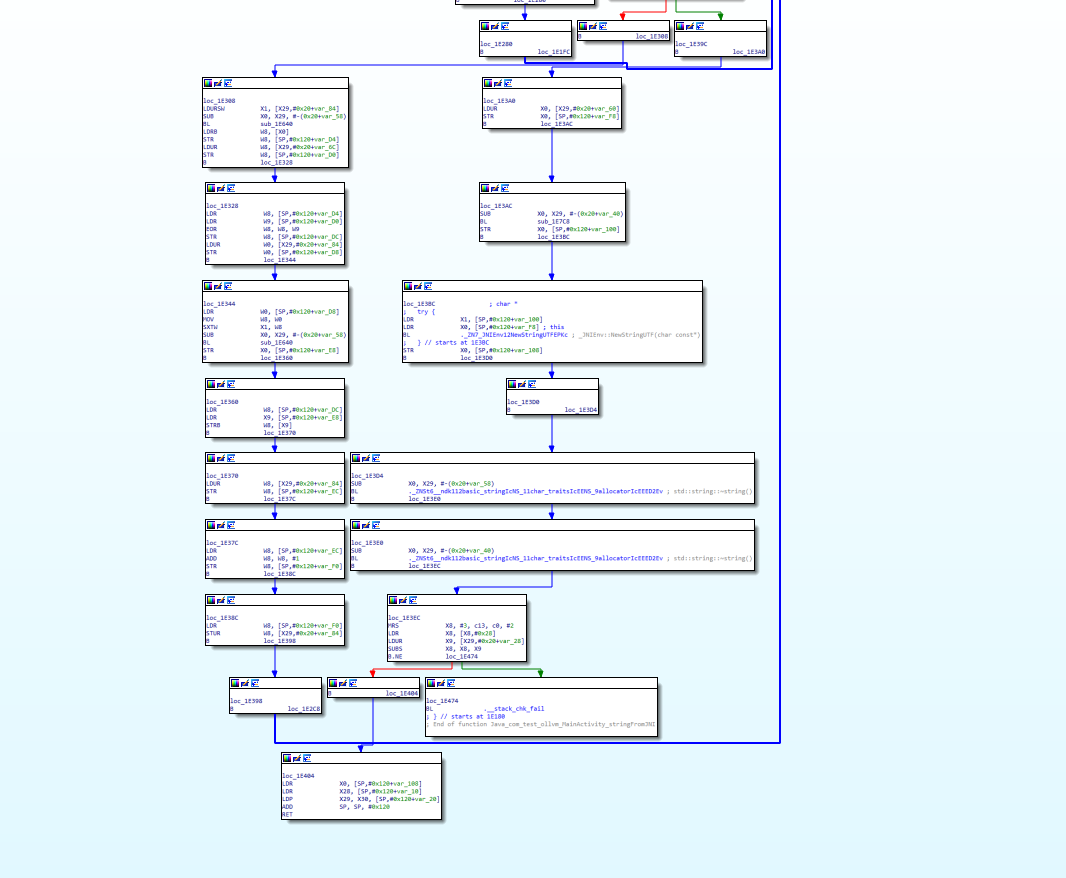
25、利用IDA Trace分析被OLLVM混淆的算法
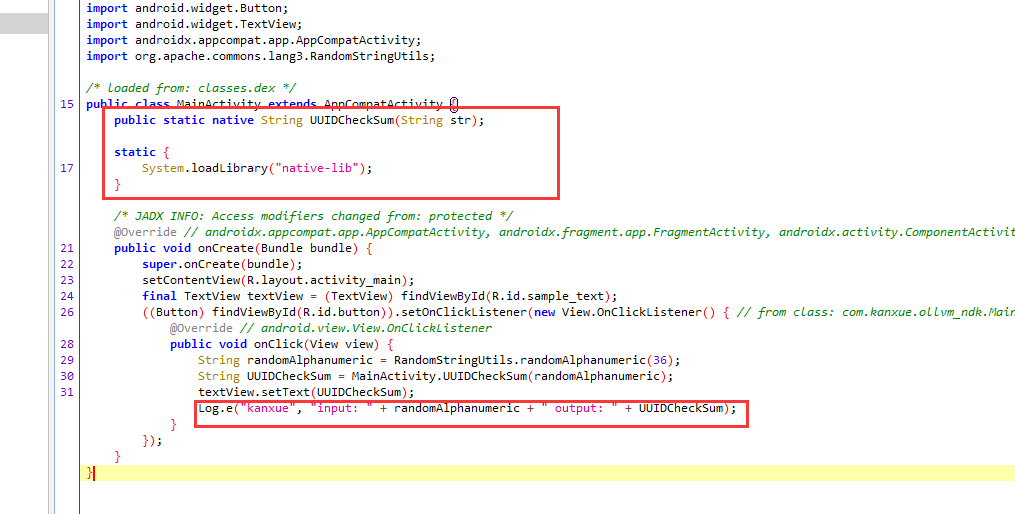
随机生成一个字符串,在 UUIDCheckSum中处理,而 UUIDCheckSum是一个native函数,所以我们重点分析native
存在ollvm
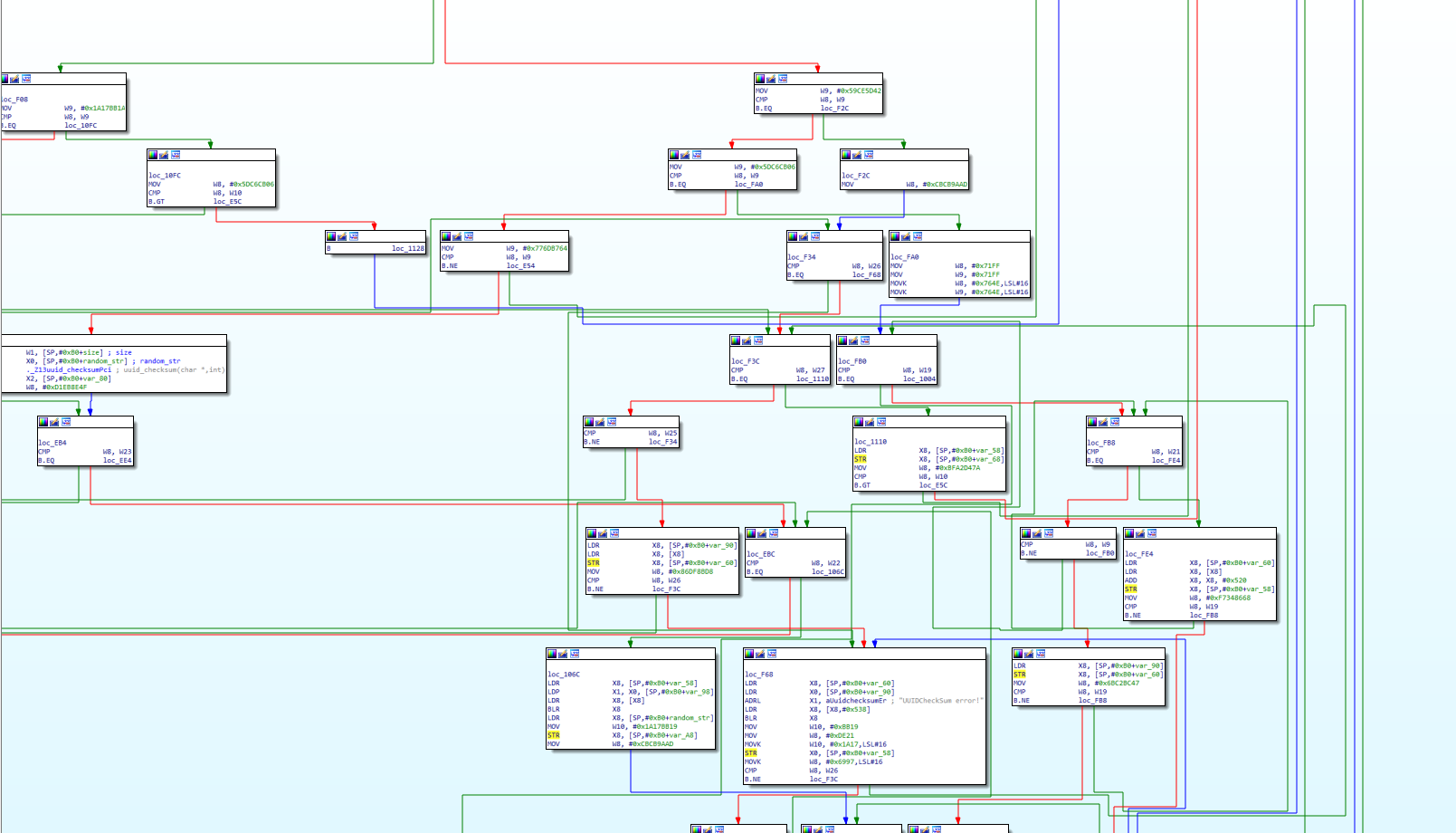
对于ollvm,我们一般都是交叉引用跟
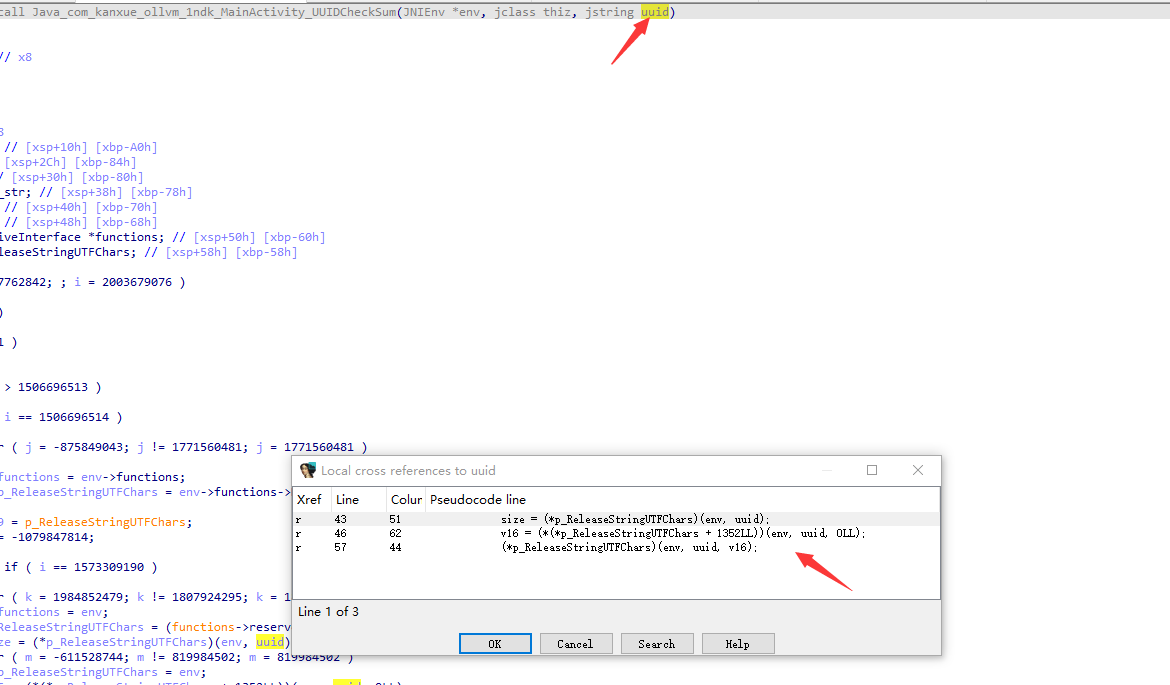
r 46 62 v16 = (*(*p_ReleaseStringUTFChars + 1352LL))(env, uuid, 0LL);解析的有问题
我们按Y改一下类型
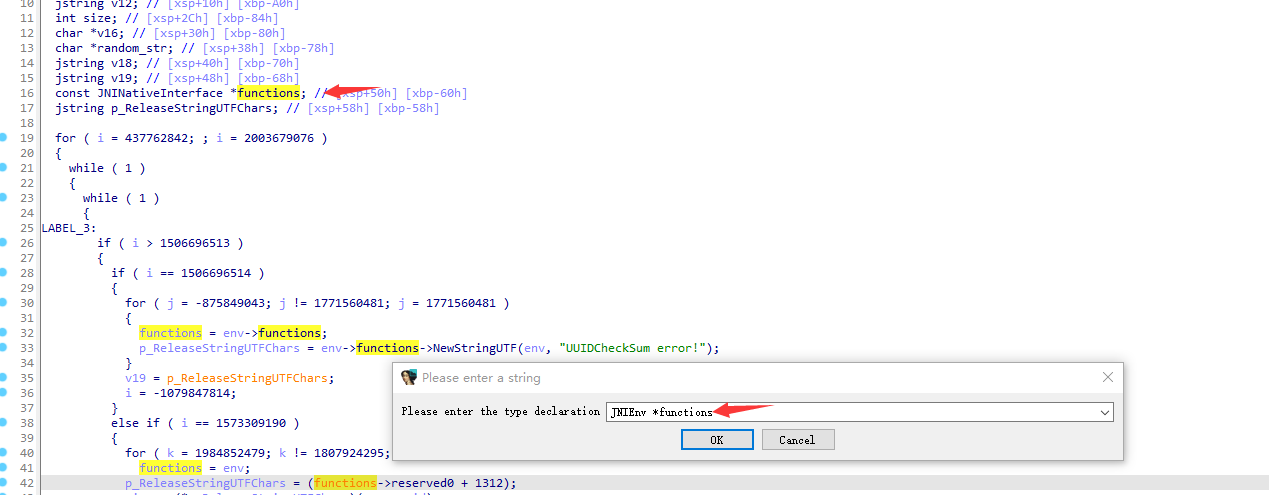
可以看到就是获取uuid的长度和内容
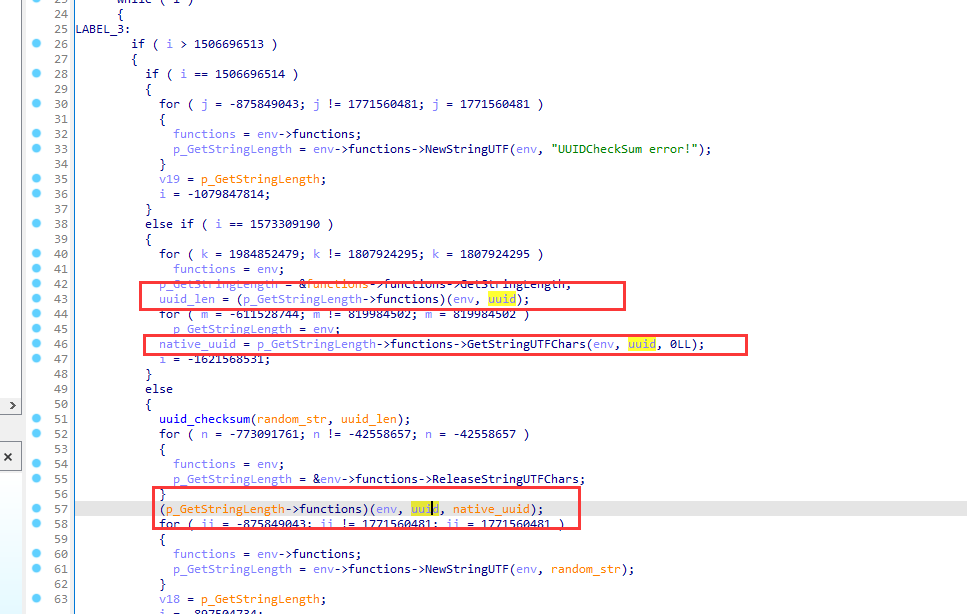
我们继续跟native_uuid
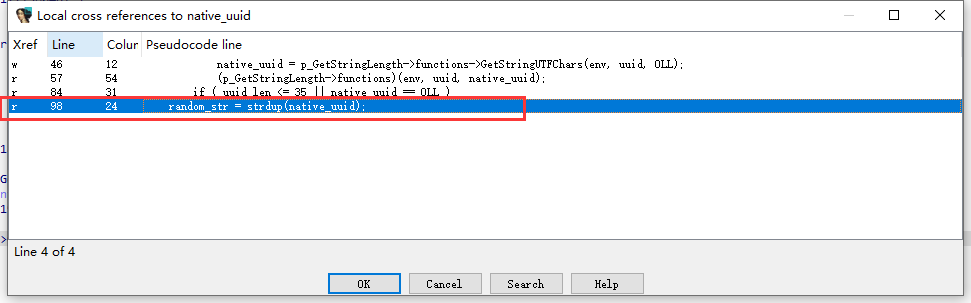
strdup()函数:将字符串复制到新建立的空间,所以我们继续跟random_str
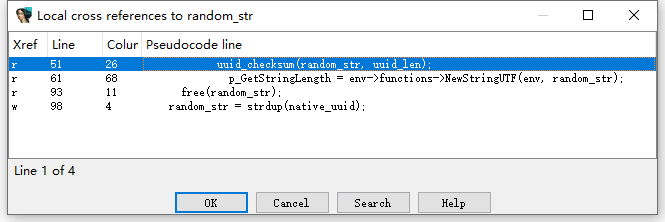
这时候就得进入uuid_checksum分析了
也是比较复杂的,得慢慢跟,现在我们介绍trace分析的方法
先介绍一下ida的trace
(1)Instruction tracing
调试器将为每条指令保存所有修改后的寄存器值。
https://www.hex-rays.com/products/ida/support/idadoc/1446.shtml
(2)Basic block tracing
调试器将保存到达临时基本块断点的所有地址。
https://www.hex-rays.com/products/ida/support/idadoc/1628.shtml
(3)Function tracing
调试器将保存发生函数调用或函数返回的所有地址。
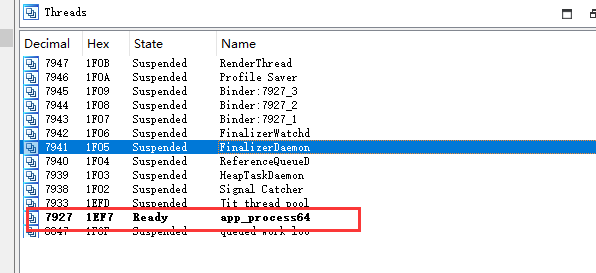
https://www.hex-rays.com/products/ida/support/idadoc/1447.shtml我们现在开始trace,首先创建一个空的ida,然后开启ida的调试server:android_server64
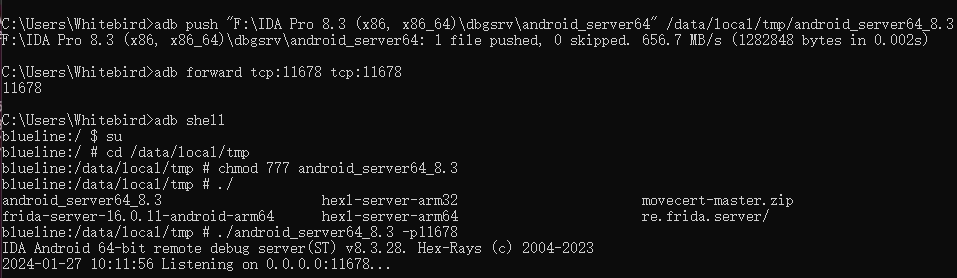
这边我们转发了端口是为了防止有一些app会检测ida的调试端口
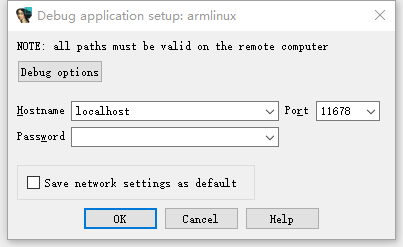
然后搜索我们要调试的app
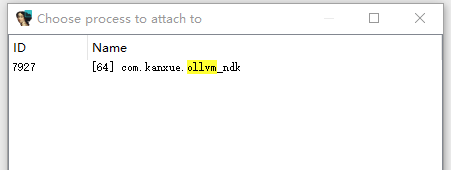
现在按F9就可以运行起来
我们分析java层代码发现有个logcat会记录输入输出,所以我们也监控一下

现在需要加载我们的trace脚本
# -*- coding: utf-8 -*-
import idaapi
import idc
import re
import ida_dbg
import ida_idd
from idaapi import *
from collections import OrderedDict
import logging
import time
import datetime
import os
debughook = None
def xx_hex(ea):
return hex(ea).rstrip("L").lstrip("0x")
def set_breakpoint(ea):
#idc.SetReg(ea, "T", 1)
idc.MakeCode(ea)
idc.add_bpt(ea)
def my_get_reg_value(register):
rv = ida_idd.regval_t()
ida_dbg.get_reg_val(register, rv)
current_addr = rv.ival
return current_addr
def suspend_other_thread():
current_thread = idc.get_current_thread()
thread_count = idc.get_thread_qty()
for i in range(0, thread_count):
other_thread = idc.getn_thread(i)
if other_thread != current_thread:
idc.suspend_thread(other_thread)
def resume_process():
current_thread = idc.get_current_thread()
thread_count = idc.get_thread_qty()
for i in range(0, thread_count):
other_thread = idc.getn_thread(i)
if other_thread != current_thread:
idc.resume_thread(other_thread)
idc.resume_thread(current_thread)
idc.resume_process()
class MyDbgHook(DBG_Hooks):
""" Own debug hook class that implementd the callback functions """
def __init__(self, modules_info, skip_functions, end_ea):
super(MyDbgHook, self).__init__()
self.modules_info = modules_info
self.skip_functions = skip_functions
self.trace_step_into_count = 0
self.trace_step_into_size = 1
self.trace_total_size = 300000
self.trace_size = 0
self.trace_lr = 0
self.end_ea = end_ea
self.bpt_trace = 0
self.Logger = None
self.line_trace = 0
print("__init__")
def start_line_trace(self):
self.bpt_trace = 0
self.line_trace = 1
self.start_hook()
def start_hook(self):
self.hook()
print("start_hook")
def dbg_process_start(self, pid, tid, ea, name, base, size):
print("Process started, pid=%d tid=%d name=%s" % (pid, tid, name))
def dbg_process_exit(self, pid, tid, ea, code):
self.unhook()
if self.Logger:
self.Logger.log_close()
print("Process exited pid=%d tid=%d ea=0x%x code=%d" % (pid, tid, ea, code))
def dbg_process_detach(self, pid, tid, ea):
self.unhook()
self.Logger.log_close()
return 0
def dbg_bpt(self, tid, ea):
print("Break point at 0x%x tid=%d" % (ea, tid))
if ea in self.end_ea:
ida_dbg.enable_insn_trace(False)
ida_dbg.enable_step_trace(False)
ida_dbg.suspend_process()
return 0
return 0
def dbg_trace(self, tid, ea):
#print("Trace tid=%d ea=0x%x" % (tid, ea))
# return values:
# 1 - do not log this trace event;
# 0 - log it
if self.line_trace:
in_mine_so = False
for module_info in self.modules_info:
# print (module_info)
so_base = module_info["base"]
so_size = module_info["size"]
if so_base <= ea <= (so_base + so_size):
in_mine_so = True
break
self.trace_size += 1
if (not in_mine_so) or (ea in self.skip_functions):
if (self.trace_lr != 0) and (self.trace_step_into_count < self.trace_step_into_size):
self.trace_step_into_count += 1
return 0
if (self.trace_lr != 0) and (self.trace_step_into_count == self.trace_step_into_size):
ida_dbg.enable_insn_trace(False)
ida_dbg.enable_step_trace(False)
ida_dbg.suspend_process()
if self.trace_size > self.trace_total_size:
self.trace_size = 0
ida_dbg.request_clear_trace()
ida_dbg.run_requests()
ida_dbg.request_run_to(self.trace_lr)
ida_dbg.run_requests()
self.trace_lr = 0
self.trace_step_into_count = 0
return 0
if self.trace_lr == 0:
self.trace_lr = my_get_reg_value("X30") #arm thumb LR, arm64 X30
return 0
def dbg_run_to(self, pid, tid=0, ea=0):
# print("dbg_run_to 0x%x pid=%d" % (ea, pid))
if self.line_trace:
ida_dbg.enable_insn_trace(True)
ida_dbg.enable_step_trace(True)
ida_dbg.request_continue_process()
ida_dbg.run_requests()
def unhook():
global debughook
# Remove an existing debug hook
try:
if debughook:
print("Removing previous hook ...")
debughook.unhook()
debughook.Logger.log_close()
except:
pass
def starthook():
global debughook
if debughook:
debughook.start_line_trace()
def main():
global debughook
unhook()
skip_functions = []
modules_info = []
start_ea = 0
end_ea = []
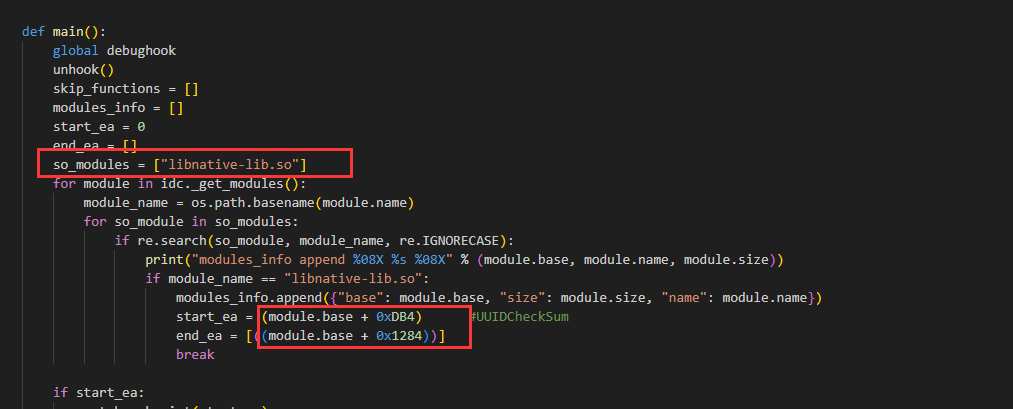
so_modules = ["libnative-lib.so"]
for module in idc._get_modules():
module_name = os.path.basename(module.name)
for so_module in so_modules:
if re.search(so_module, module_name, re.IGNORECASE):
print("modules_info append %08X %s %08X" % (module.base, module.name, module.size))
if module_name == "libnative-lib.so":
modules_info.append({"base": module.base, "size": module.size, "name": module.name})
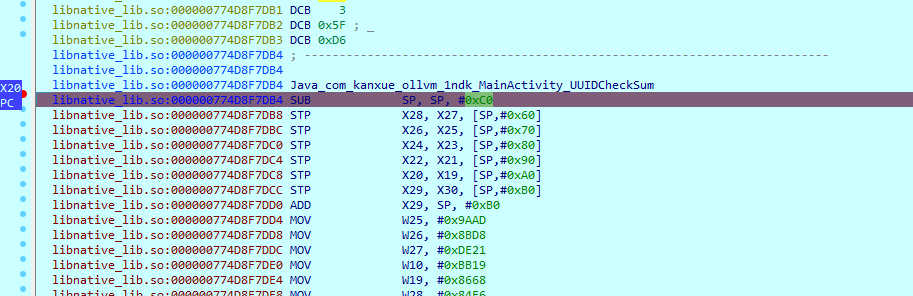
start_ea = (module.base + 0xDB4) #UUIDCheckSum
end_ea = [((module.base + 0x1284))]
break
if start_ea:
set_breakpoint(start_ea)
if end_ea:
for ea in end_ea:
set_breakpoint(ea)
if skip_functions:
print("skip_functions")
for skip_function in skip_functions:
print ("%08X" % skip_function)
debughook = MyDbgHook(modules_info, skip_functions, end_ea)
pass
if __name__ == "__main__":
main()
pass这个脚本正常不用改,我们需要修改的地方如下,主要是trace的so和偏移
有个报错,我们修改一下
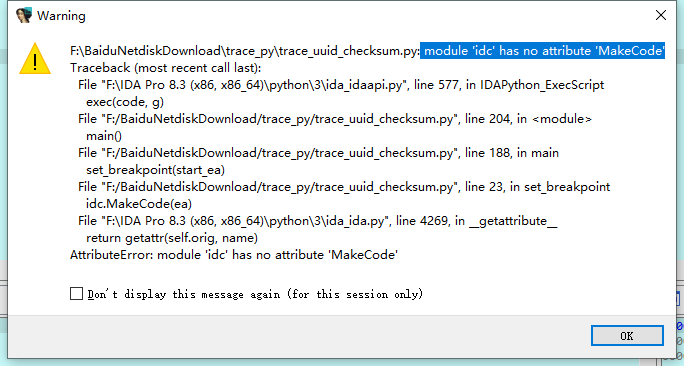
新版本ida不兼容旧版本的api
https://hex-rays.com/products/ida/support/ida74_idapython_no_bc695_porting_guide.shtml

我们做一个替换
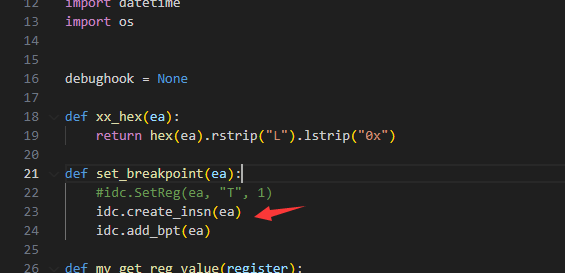
现在正常了
自动帮我们在函数开始和结尾下了断点

当我现在点击check后就断了下来
先开启starthook()

然后挂起其他无关线程,防止有检测的线程

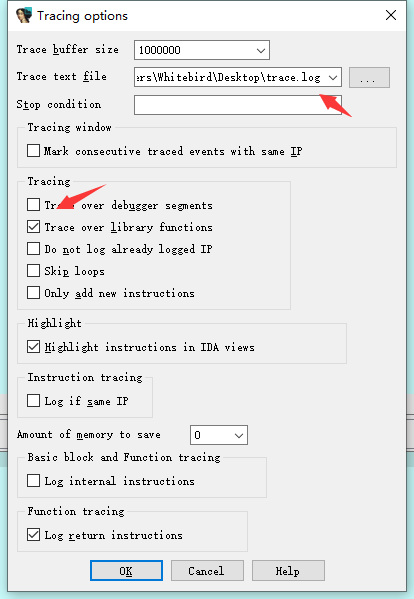
设置trace
取消勾选和设置保存log的路径
我们选择指令级trace,点击一下就行
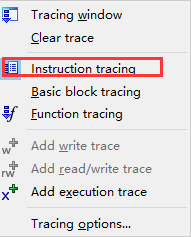
这个时候我们继续运行
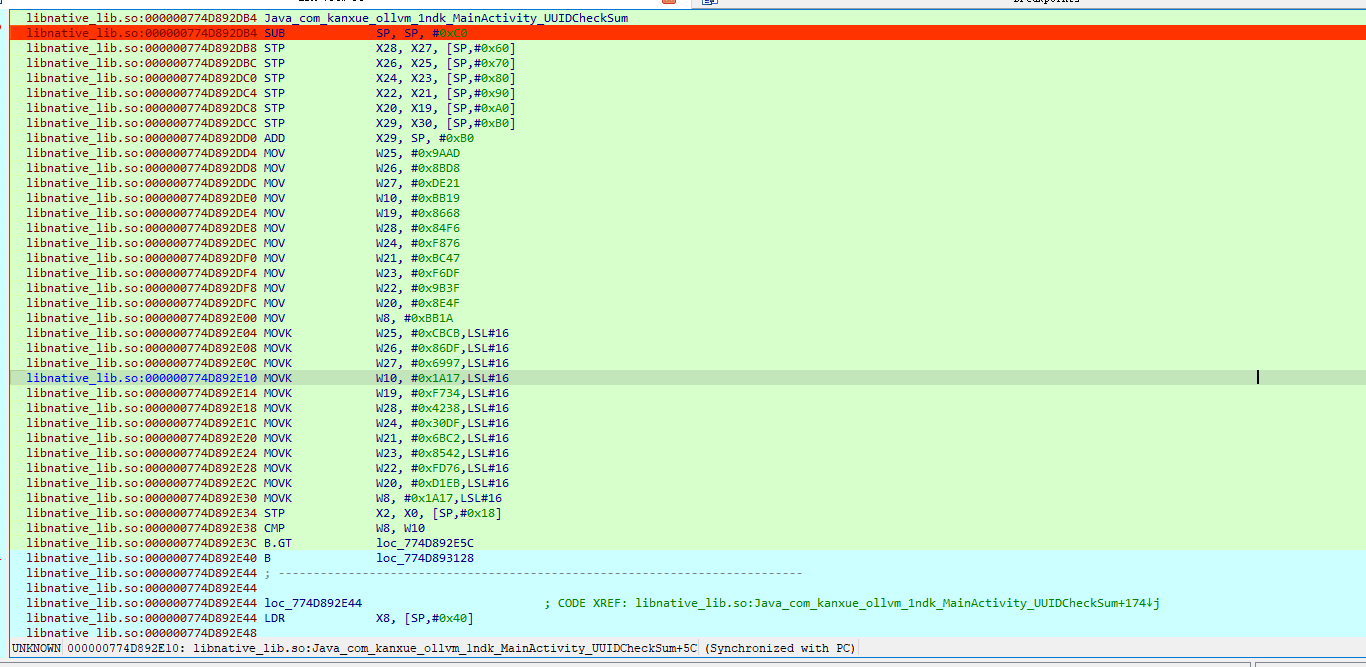
可以看到有些指令变色了,这个变色的就是已经执行到的指令
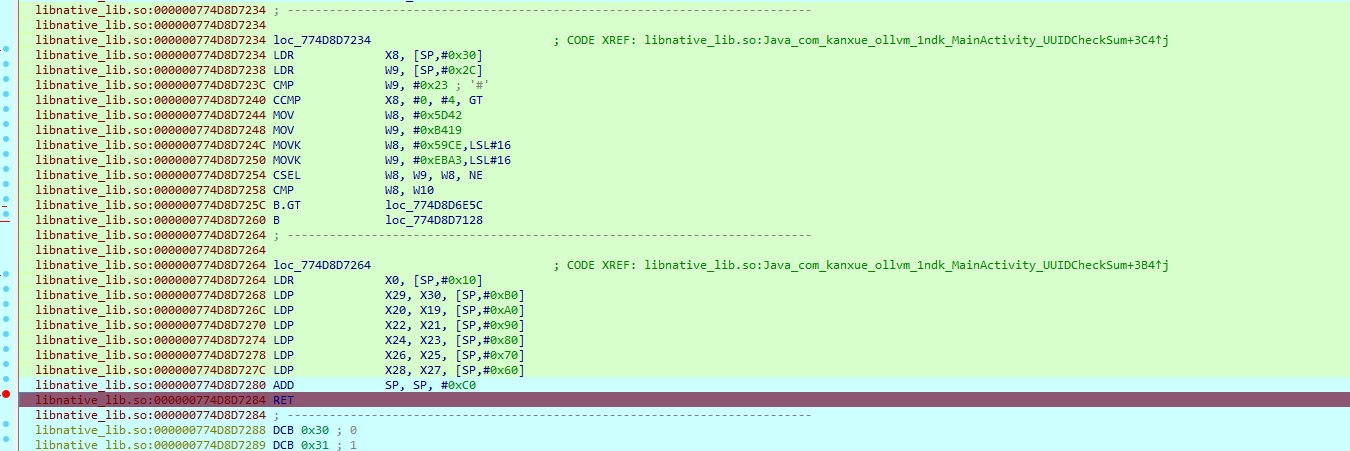
等个十几秒跑完,此时暂停在ret了
此时恢复所有的线程

现在的input
01-27 10:50:23.759 8839 8839 E kanxue : input: fxylU6VJAqyRI6rwQ9UjQHWYLMTfCFErIlnA output: fxylU6VJ-qyRI-4wQ9-jQHWL-MTfCFErIl67我们的日志用010打开,因为搜索方便,而且速度快
现在分析log
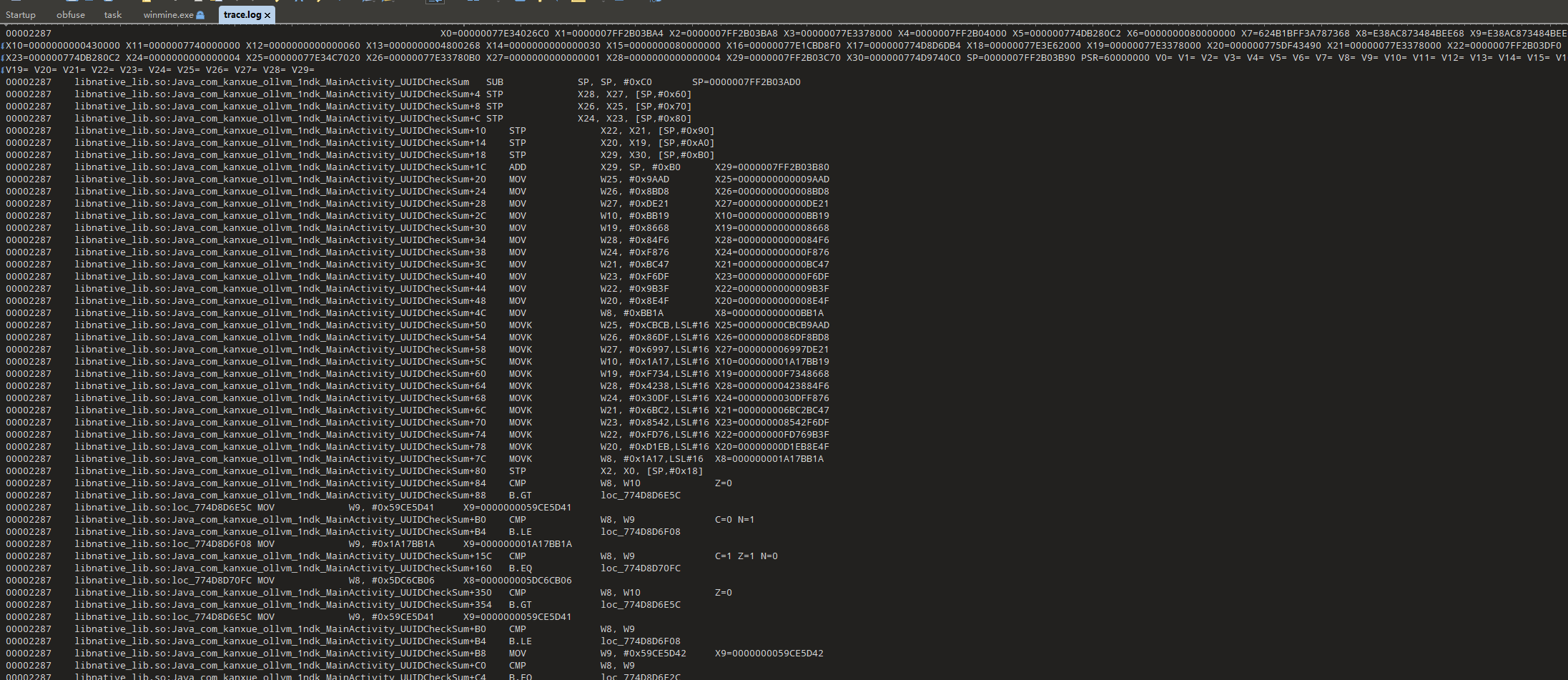
通过之前的分析我们知道加密逻辑在uuid_checksum中
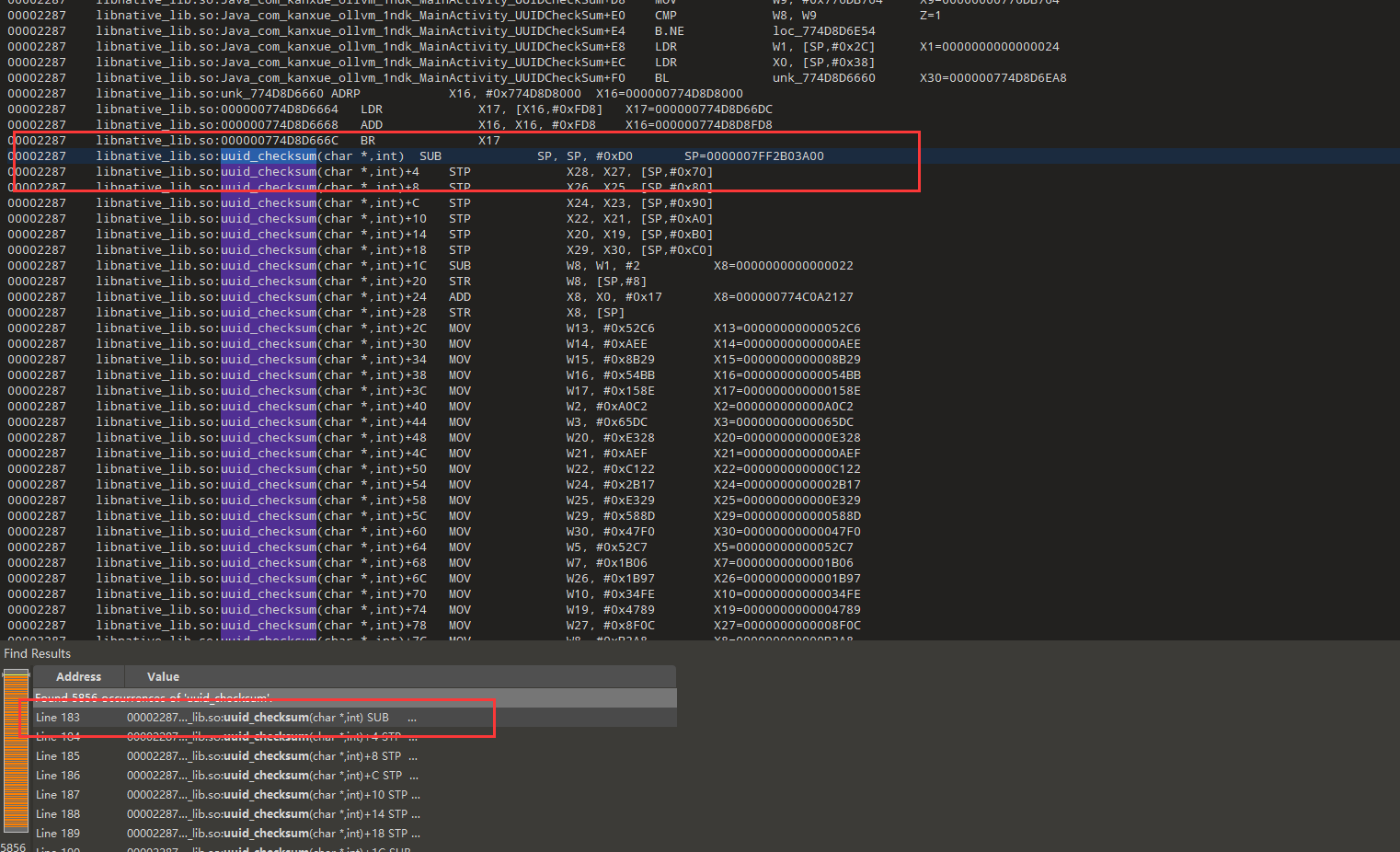
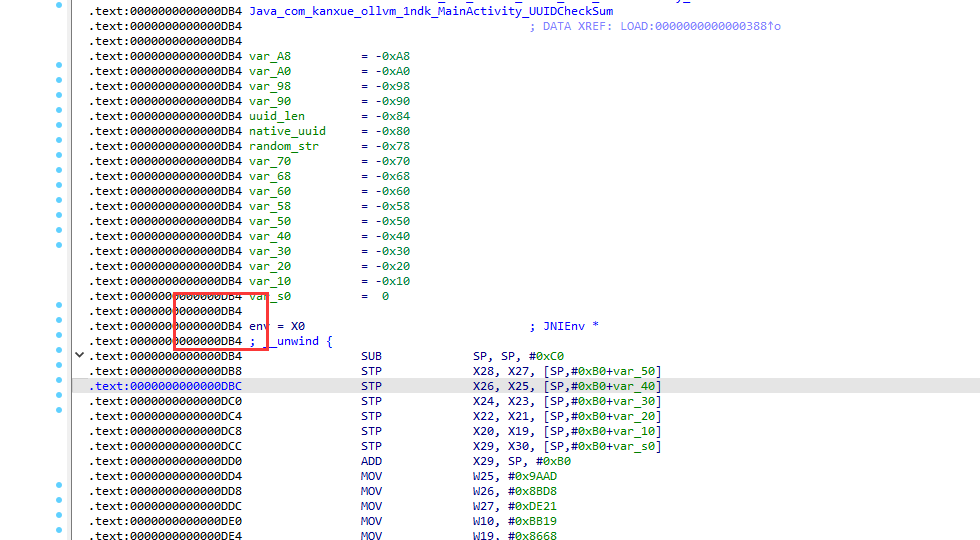
我们从这开始分析,x0是参数1:字符串地址,x1是参数2:字符串长度
我们写了个注释
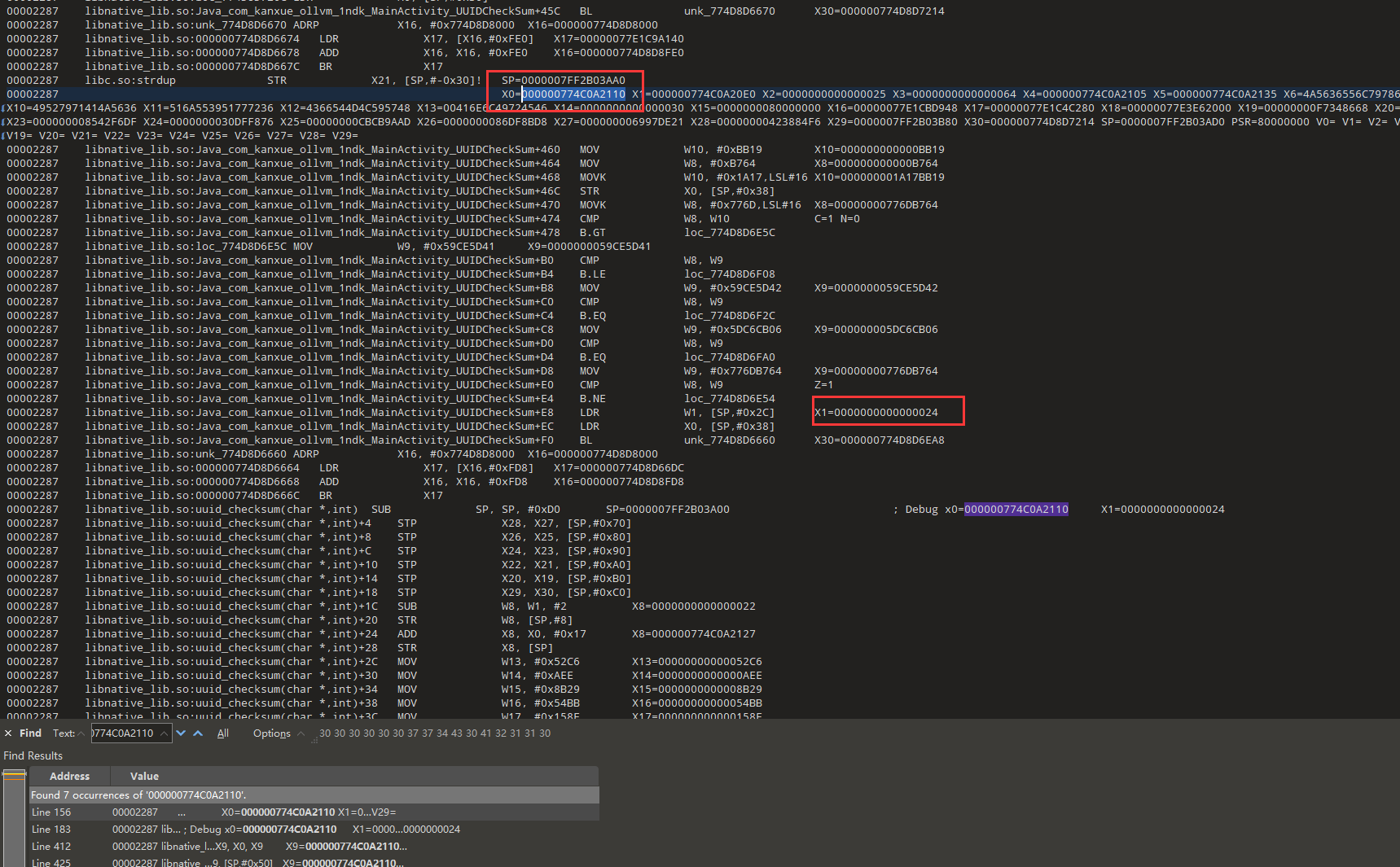
字符串长度-2
我们搜索x0,发现x9=x9+x0,而此时的x9=0,所以x9=x0,然后继续搜x9,又发现[x9]取出了值0x66,对应字符是f
我们的输入中第一个字符就是f,加密的结果第一个也是f,可能是赋值操作
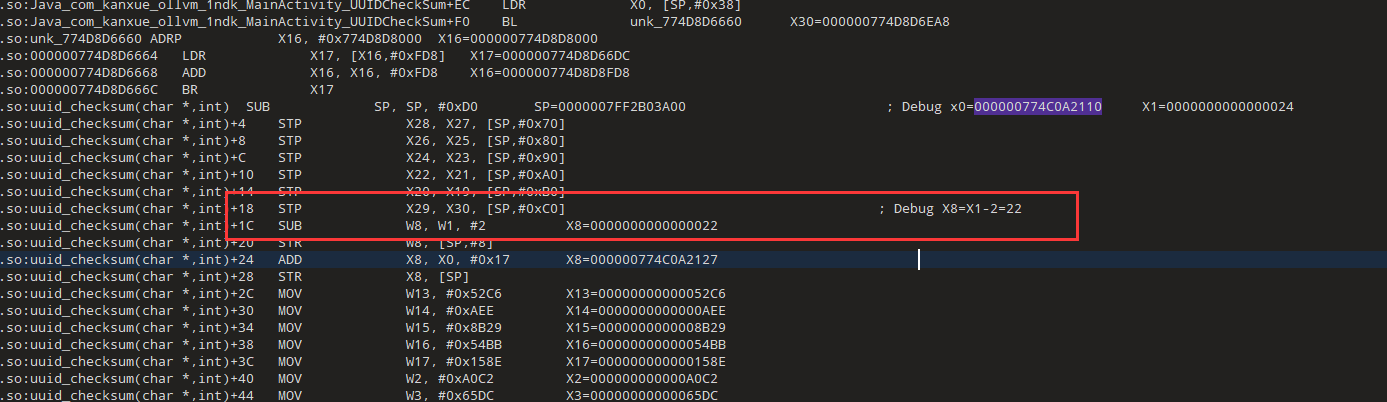
01-27 10:50:23.759 8839 8839 E kanxue : input: fxylU6VJAqyRI6rwQ9UjQHWYLMTfCFErIlnA output: fxylU6VJ-qyRI-4wQ9-jQHWL-MTfCFErIl67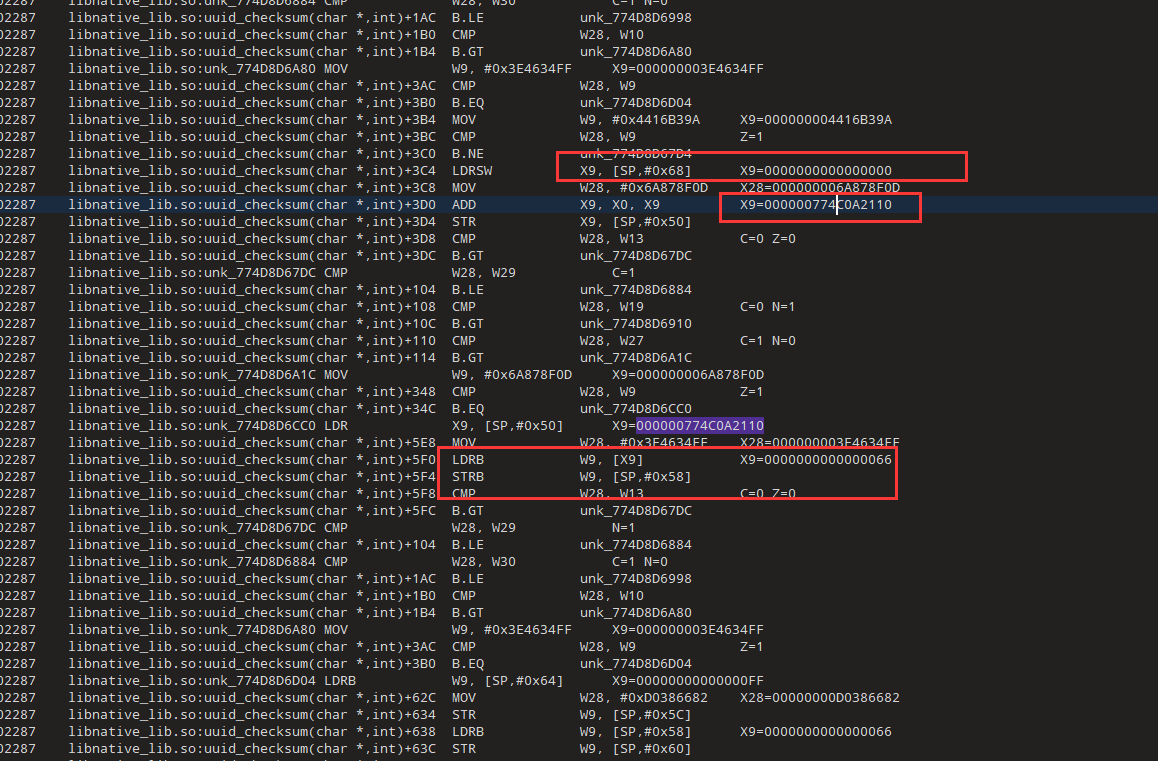
我们搜索了取值指令,发现有多处调用
libnative_lib.so:uuid_checksum(char *,int)+5F0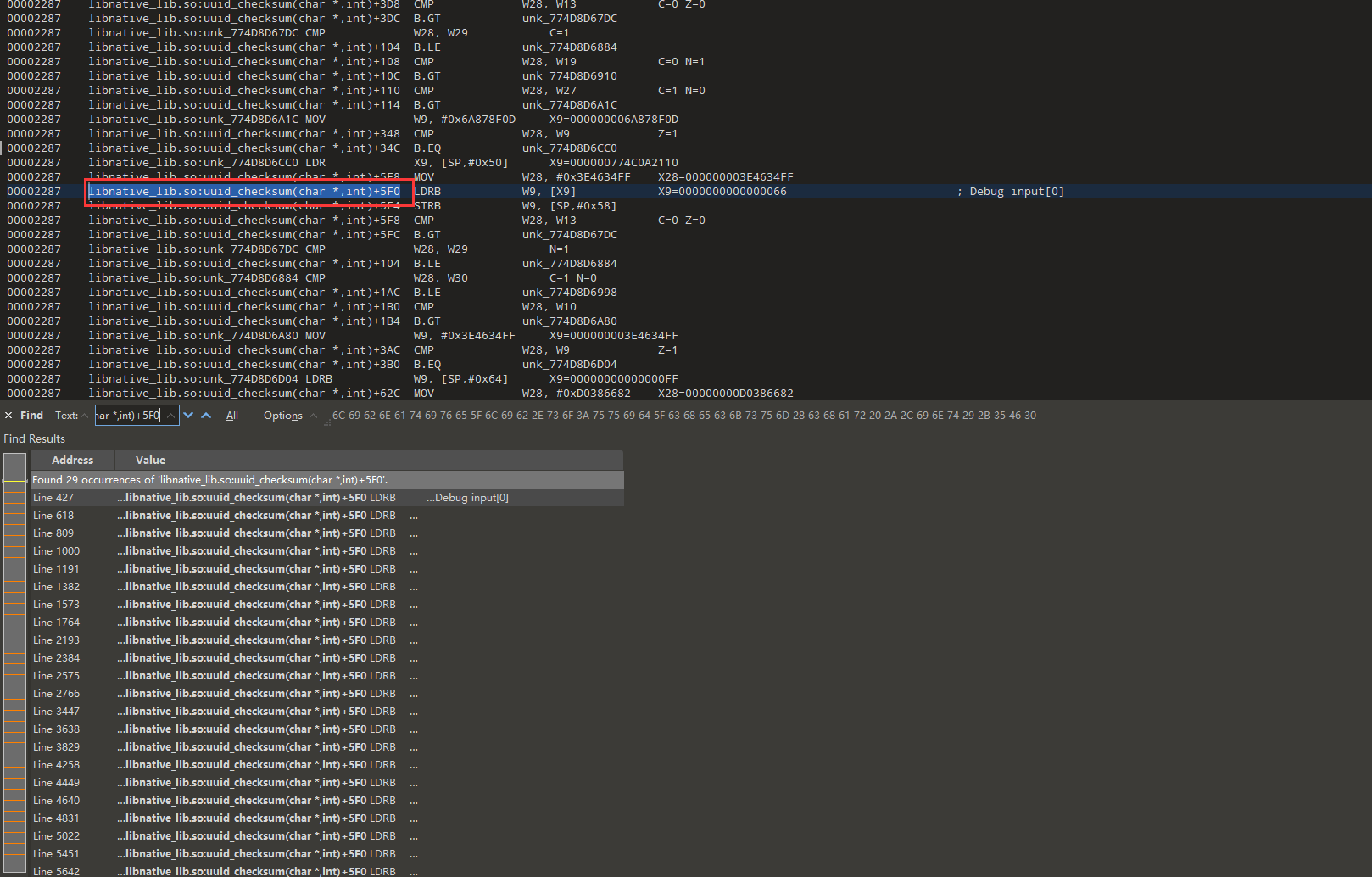
发现第二个取值0x78,而且索引是1,对应字符是x
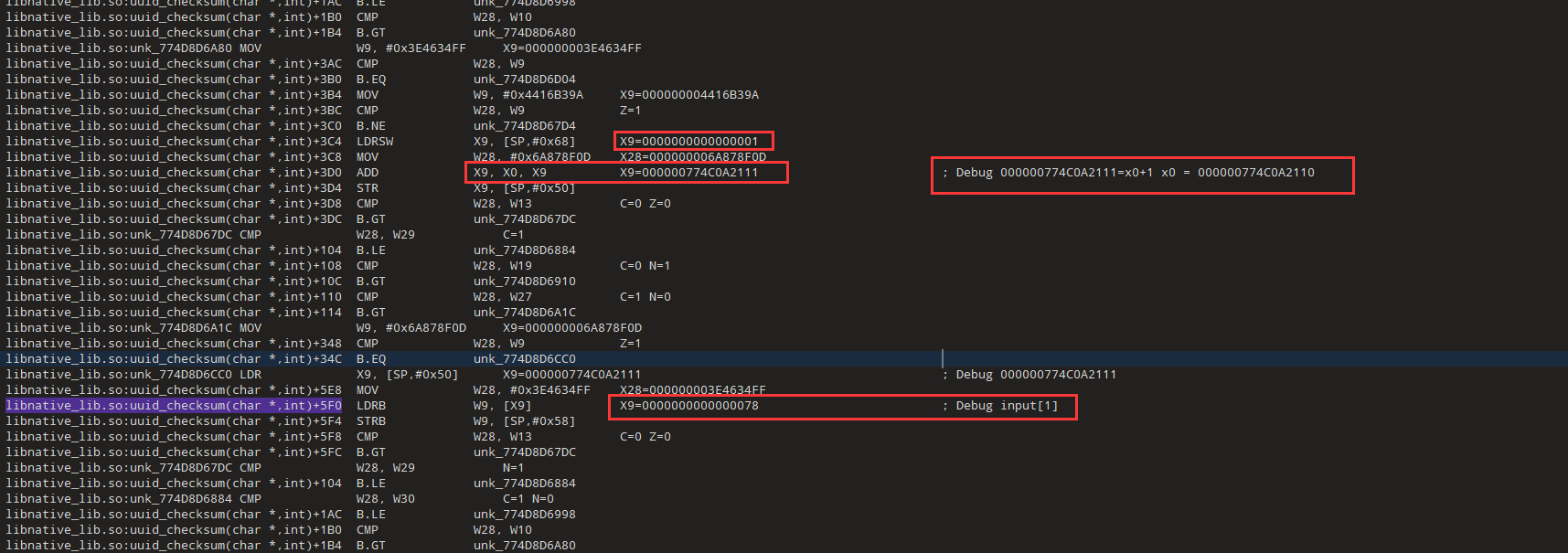
我们现在搜索libnative_lib.so:unk_774D8D6CC0 LDR X9, [SP,#0x50]
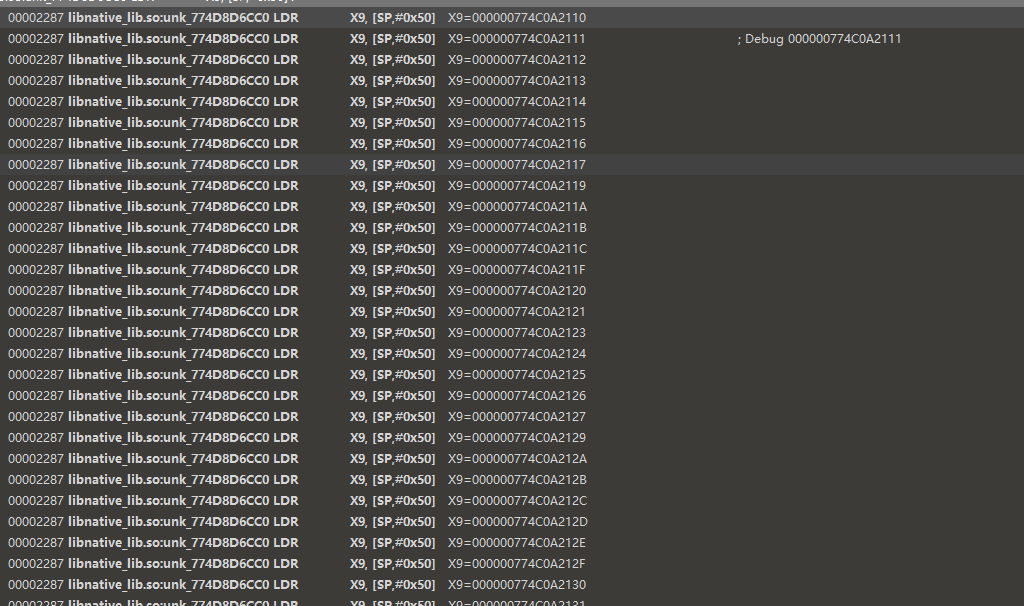
可以发现少了000000774C0A2118,有些地方做了处理,我们继续分析
先观察一下输入输出
input: fxylU6VJAqyRI6rwQ9UjQHWYLMTfCFErIlnA
output: fxylU6VJ-qyRI-4wQ9-jQHWL-MTfCFErIl67fxylU6VJ猜测是直接复制的,对A进行了特殊处理,也就是索引是8的时候
可以看到把-进行了赋值替换A
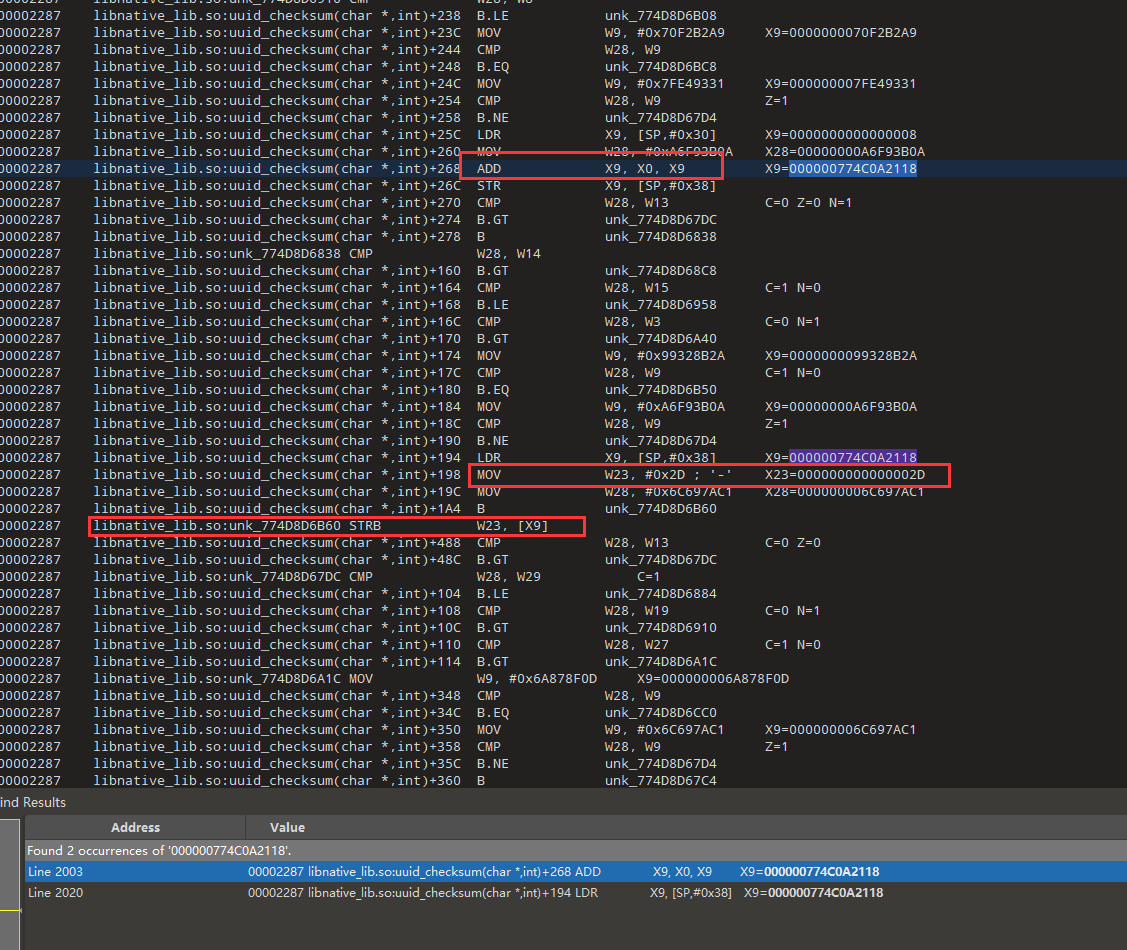
qyRI猜测也是直接复制的,我们看6怎么变成-,和上面一样直接进行了赋值操作
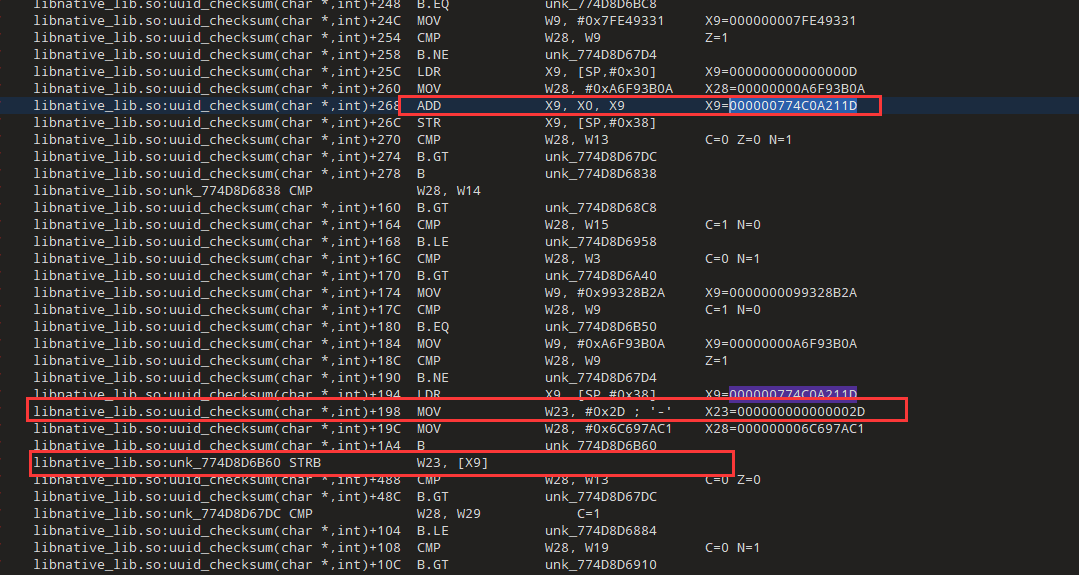
接下来看r怎么变成4,也是直接赋值的
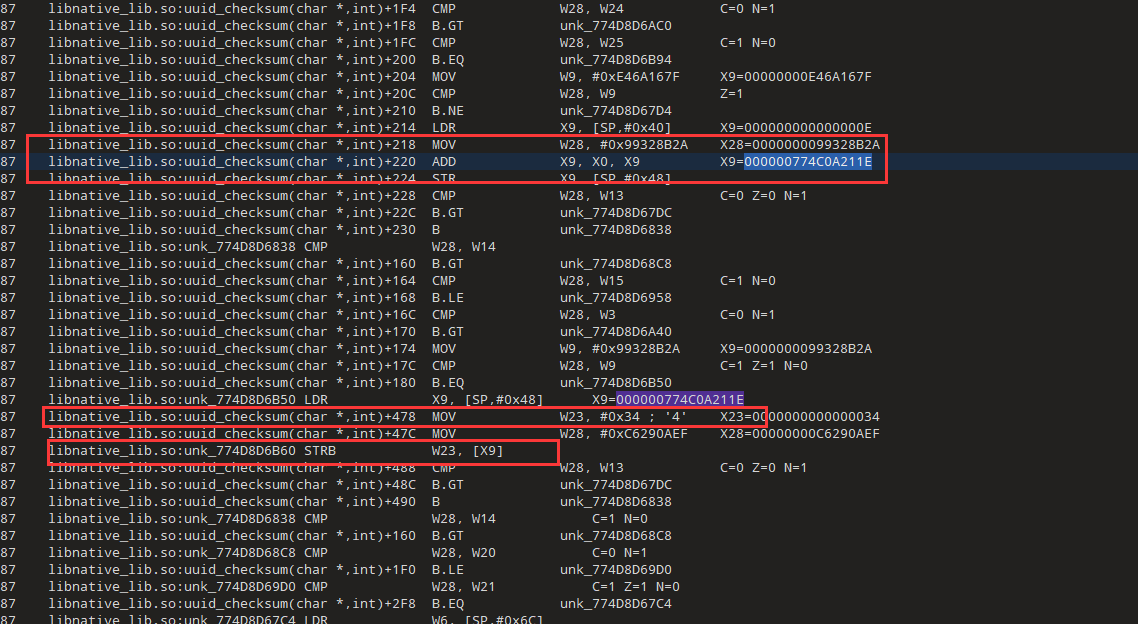
input: fxylU6VJAqyRI6rwQ9U jQHWYLMTfCFErIlnA
output: fxylU6VJ-qyRI-4wQ9- jQHWL-MTfCFErIl67现在前面部分已经分析完了,我们继续分析后面的部分,wQ9很显然也是直接复制
然后看U变成-,也是直接赋值的,索引是0x12,可以自己数一下
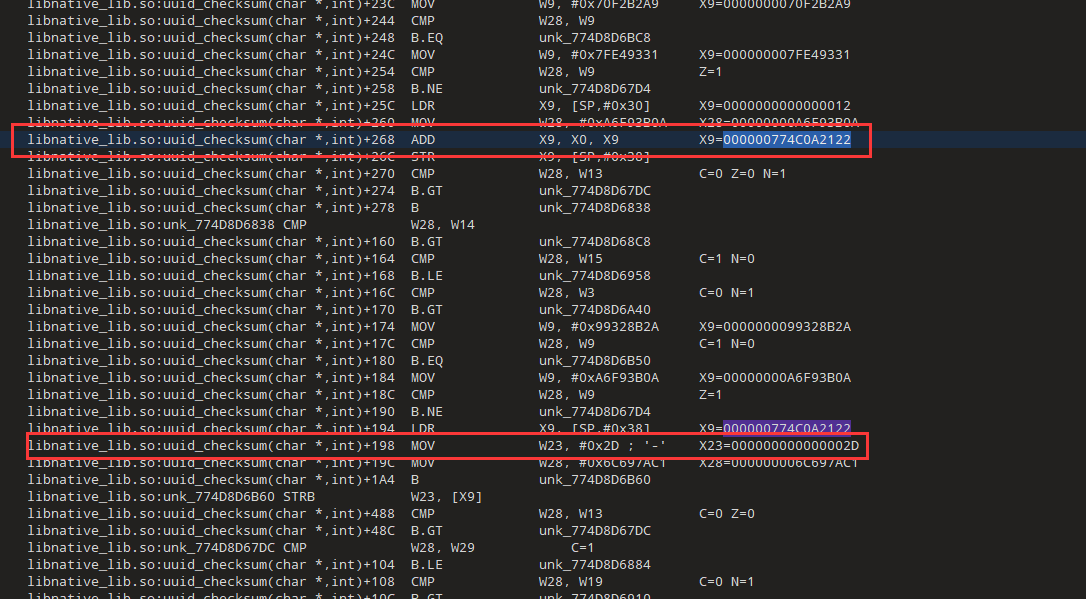
jQHW猜测也是直接复制,现在看一下Y变成L的过程,索引0x17,直接赋值0x4c,对应ASCII是L
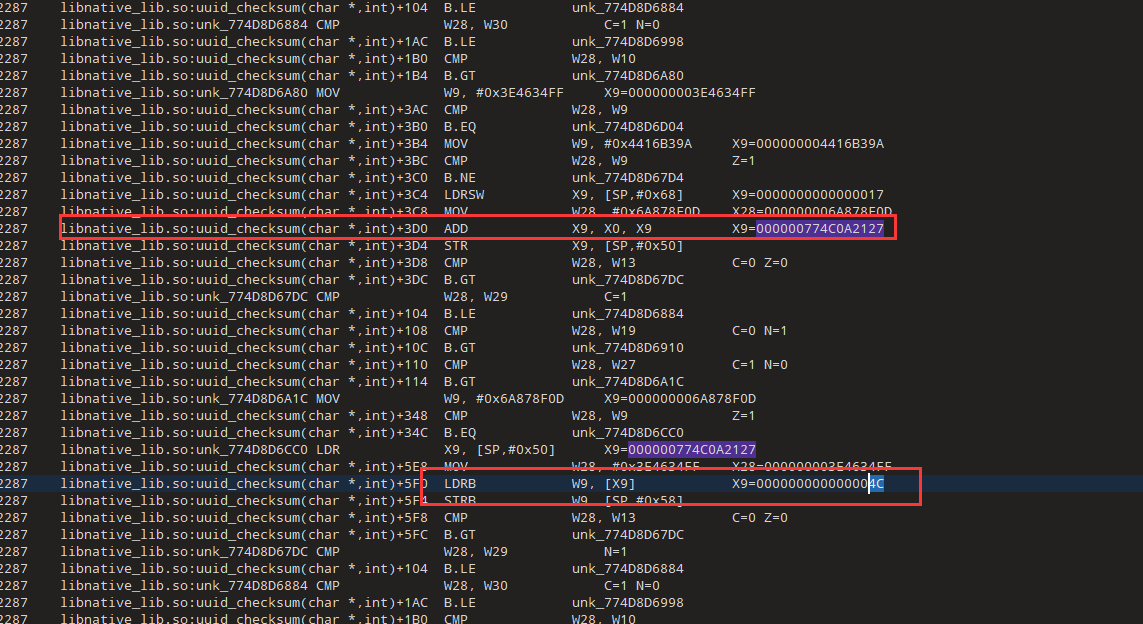
input: fxylU6VJAqyRI6rwQ9UjQHWY LMTfCFErIlnA
output: fxylU6VJ-qyRI-4wQ9-jQHWL -MTfCFErIl67看一下0x18的位置,应该也是直接赋值-
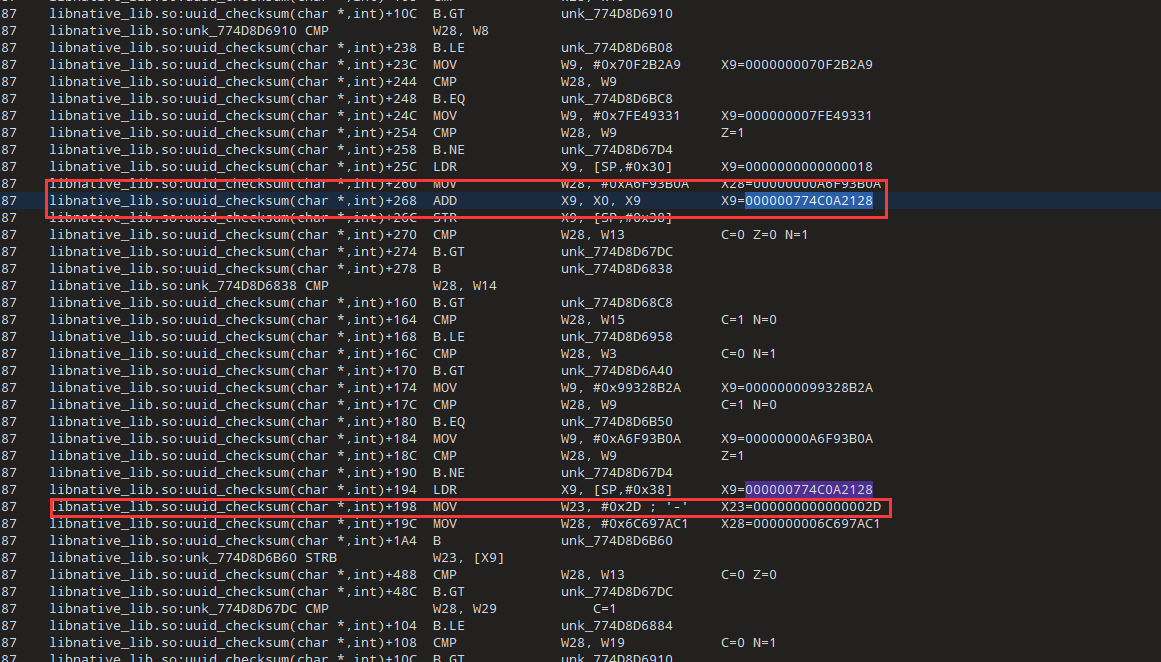
MTfCFErIl是直接复制的的,我们现在还差最后两位
input: fxylU6VJ A qyRI 6 r wQ9 U jQHW Y L MTfCFErIl nA
output: fxylU6VJ - qyRI - 4 wQ9 - jQHW L - MTfCFErIl 67
input: EejEzH6W E EWMi L r pWZ Y xTAD U F XJ1biCkfx Dt
output: EejEzH6W - EWMi - 4 pWZ - xTAD F - XJ1biCkfx c9
input: QzNfJPHh P doFc n y ewb P nOl0 G i kddw7p7c9 ih
output: QzNfJPHh - doFc - 4 ewb - nOl0 i - kddw7p7c9 9a
input: 0pvvK1r1 s iPtY Z V IVy T 3uV7 H 8 27jA313cd VJ
output: 0pvvK1r1 - iPtY - 4 IVy - 3uV7 8 - 27jA313cd 83
input: mCMCAlEH 9 ZDOd 2 W c26 x q4om 1 L 7ZGBGHWhE Yh
output: mCMCAlEH - ZDOd - 4 c26 - q4om L - 7ZGBGHWhE 0b
input: lq19d6tS h FYoC q 2 c2T f yTcR 2 i 0PfY843d0 f3
output: lq19d6tS - FYoC - 4 c2T - yTcR i - 0PfY843d0 f8我们先验证一下前面的分析,可以多弄几组数据
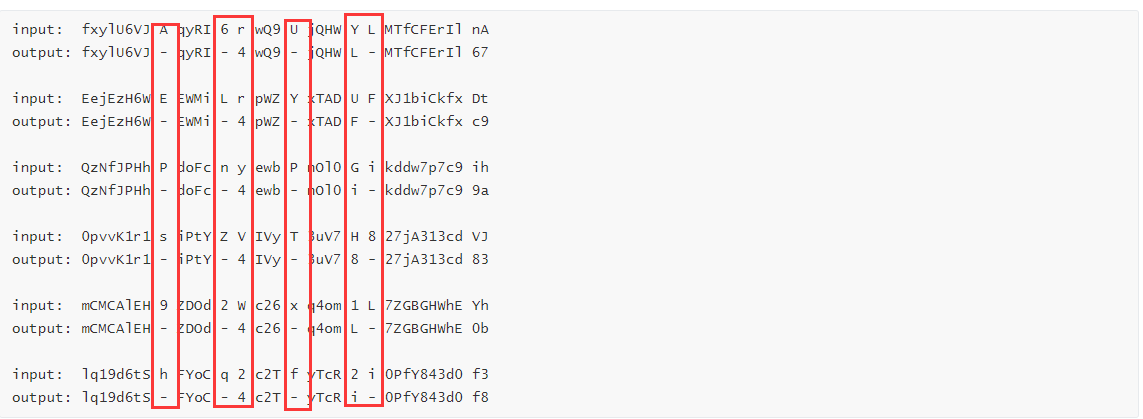
索引8、0xd、0x12、0x18都是直接替换成-,索引0xe的位置全部替换成4
但是最后一组有些问题,Y->L、U->F、G->i、H->8、1->L、2->i不是固定的,仔细看发现是赋值为后一位字符:Y的下一位是L
我们分析log验证一下
我们搜索一下0x4c的来源
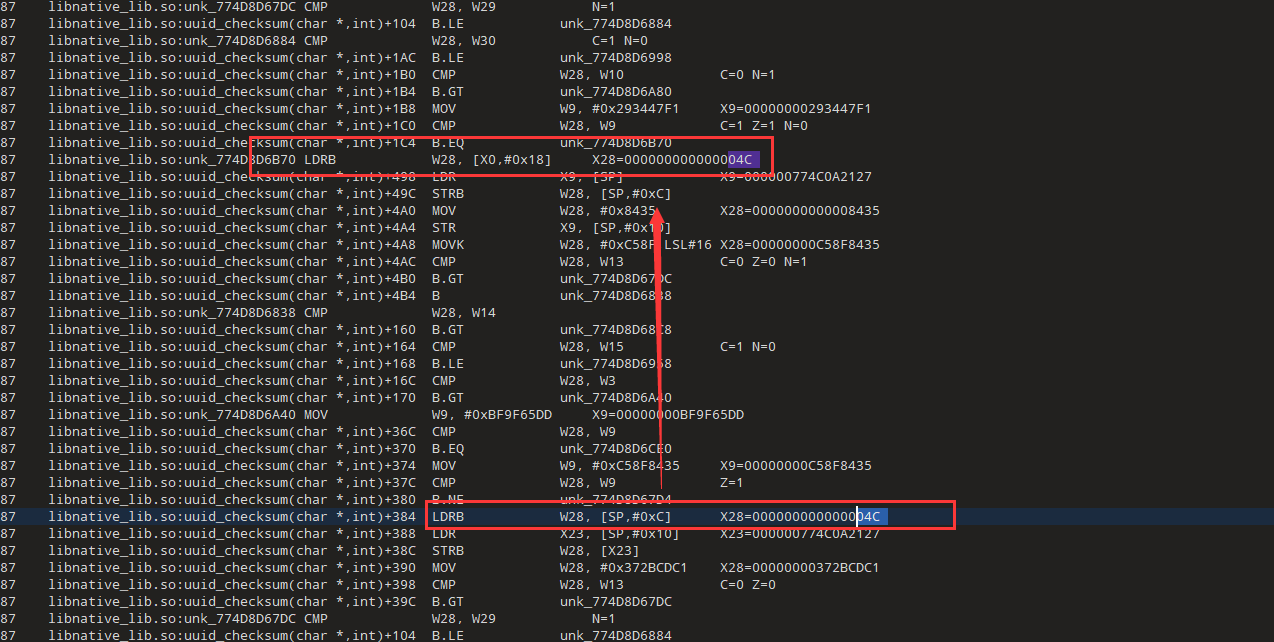
直接搜的04c,然后定位到下面LDRB W28, [SP,#0xC] ,再搜索[SP,#0xC],找到上面的位置,X28=X0+0x18,而x0就是我们字符串的首地址,0x18是偏移,刚好是0x17的后一位
现在我们分析最后两位来源,由于最开始我们的循环长度-2了,所以最后两位不在这个循环里了
尝试用之前赋值指令搜索,没有找到
libnative_lib.so:uuid_checksum(char *,int)+5F0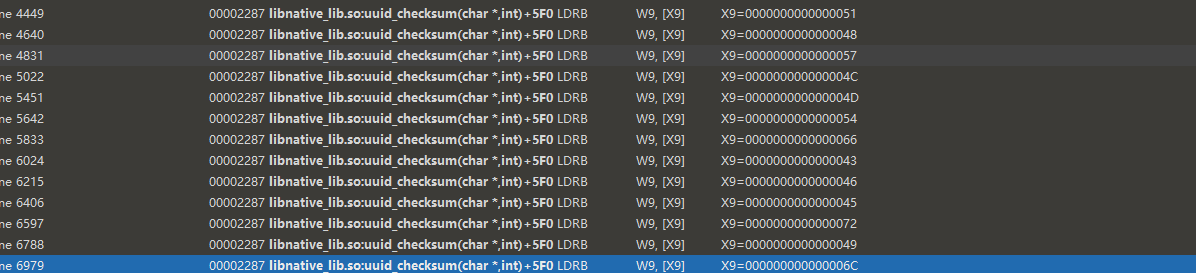
直接搜000000774C0A2110+0x22,也不行
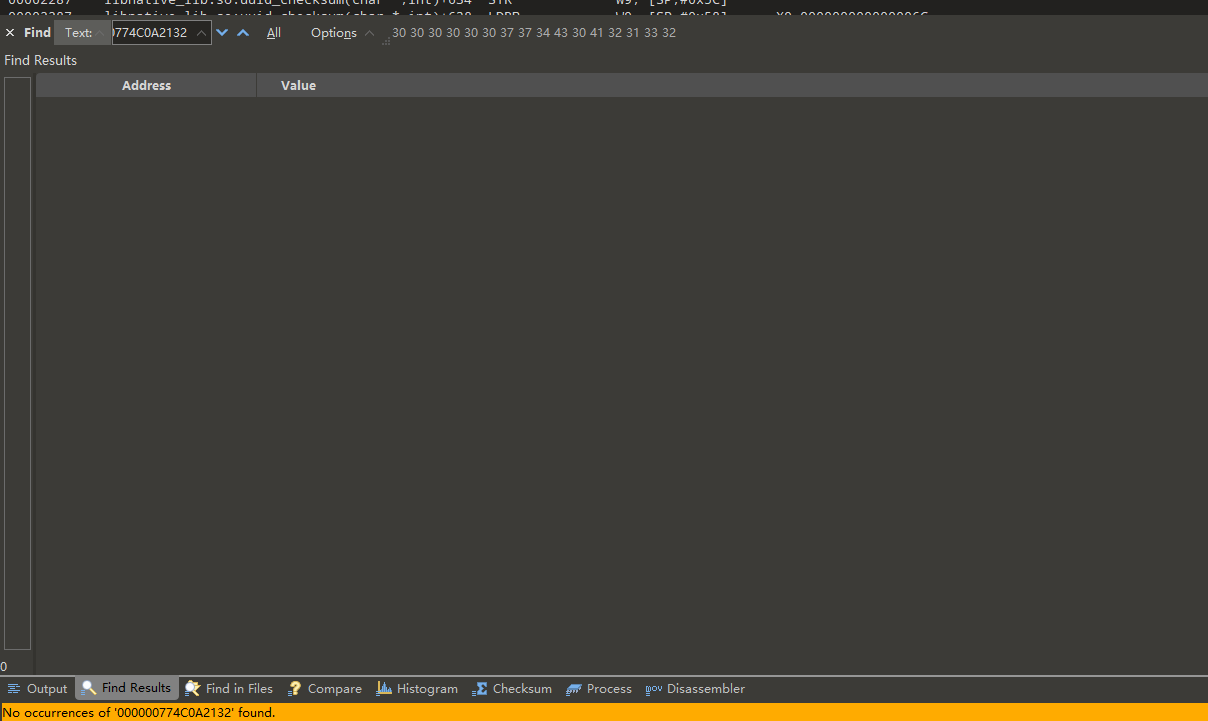
使用[x0,寻址方式找到了
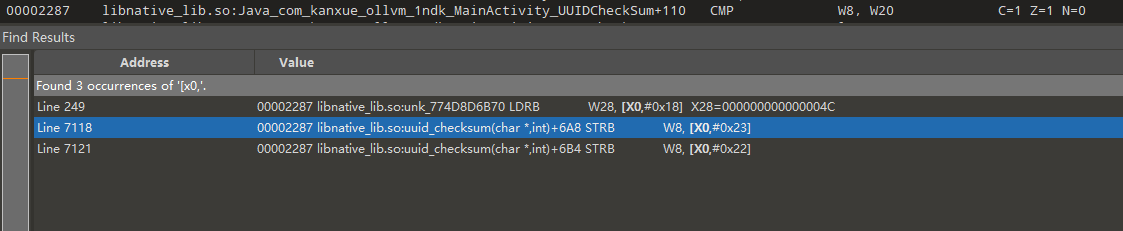
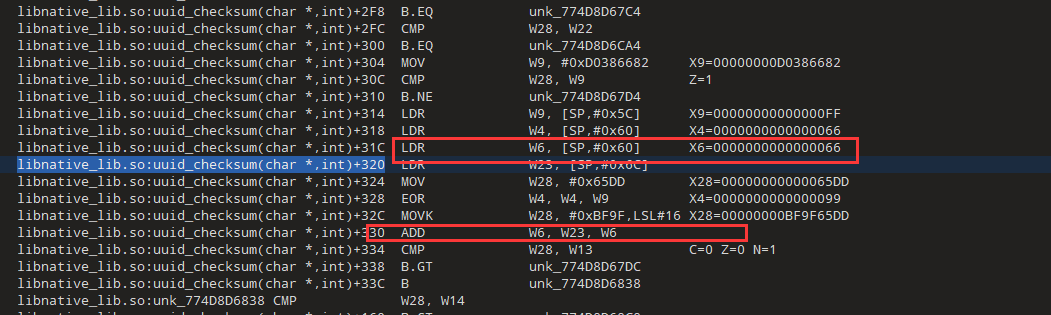
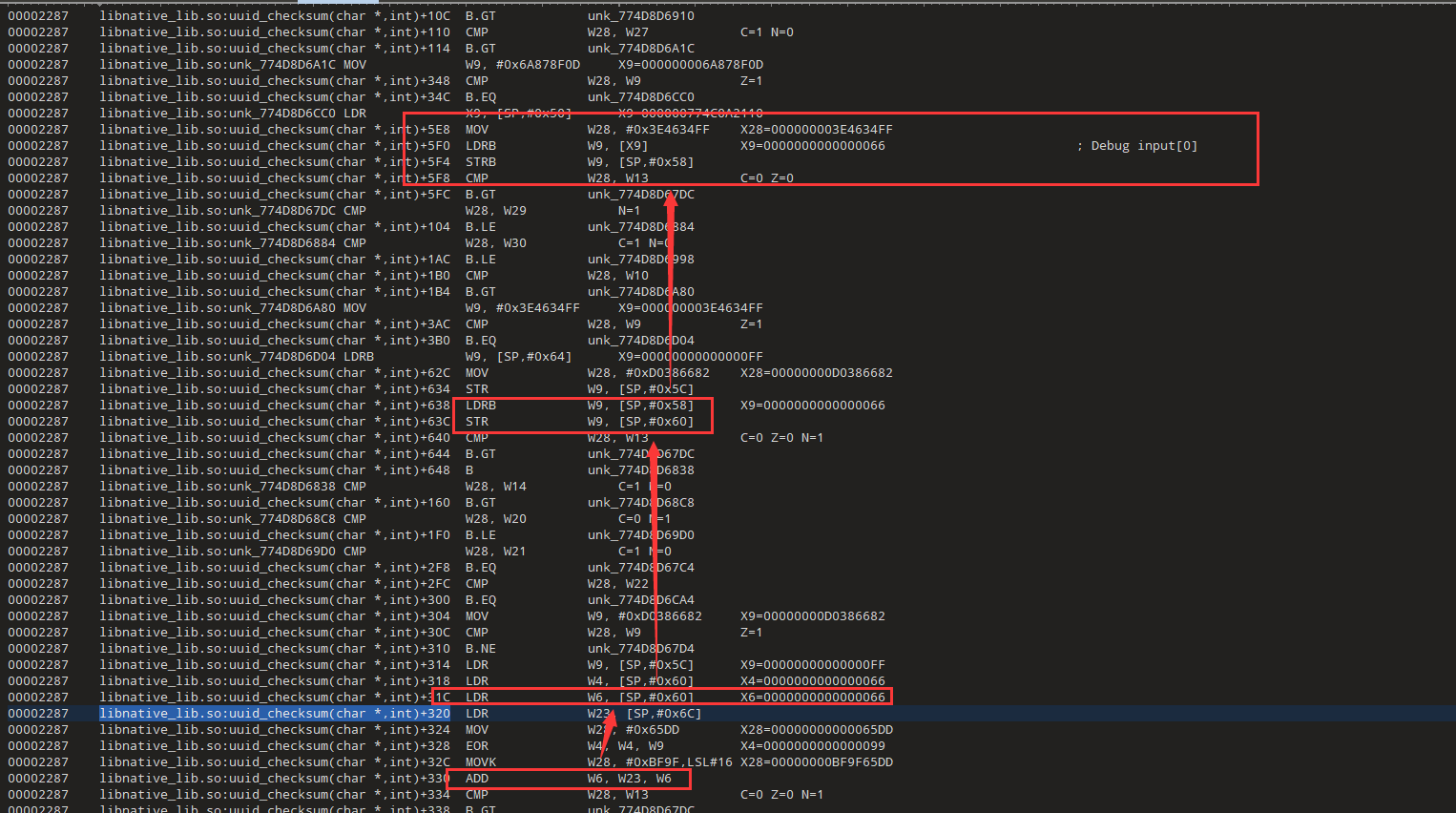
我们现在要找到X9的来源和6的来源,继续往上分析

我们看一下ida,发现这里最后两位的索引表偏移是0x1288,和trace中直接赋值X9的地址有点相似
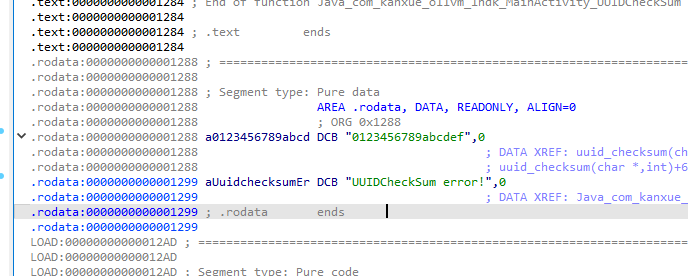
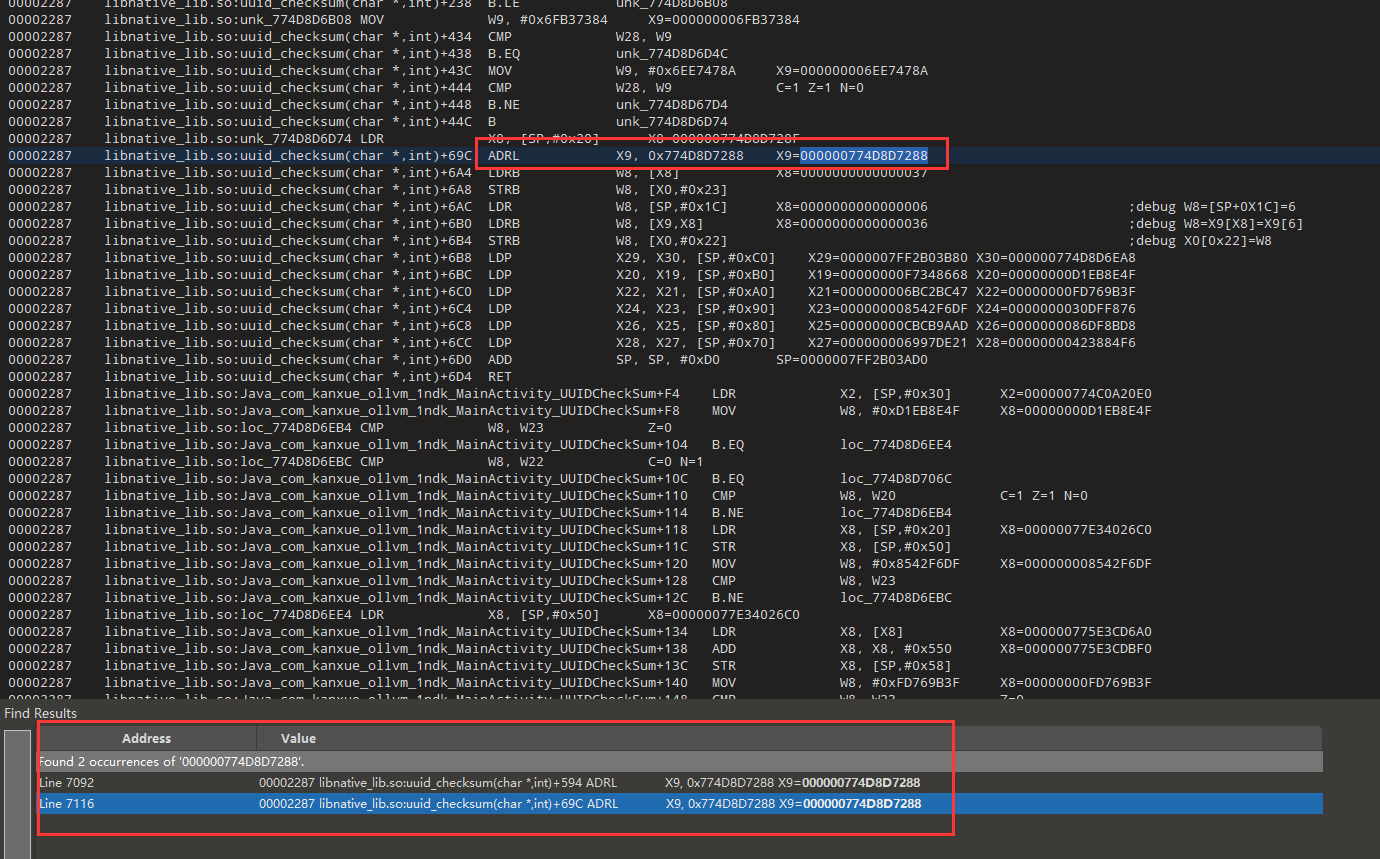
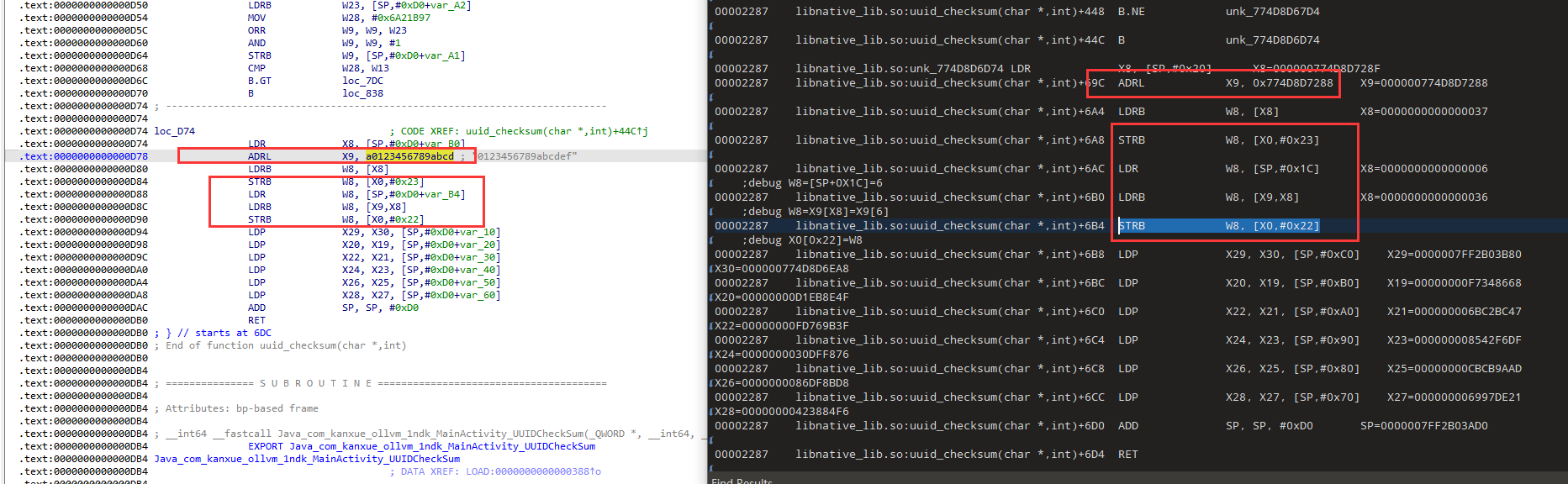
现在找一下这个索引的来源W23=W28 - W23 = 0000000000000A16-0000000000000A10=6
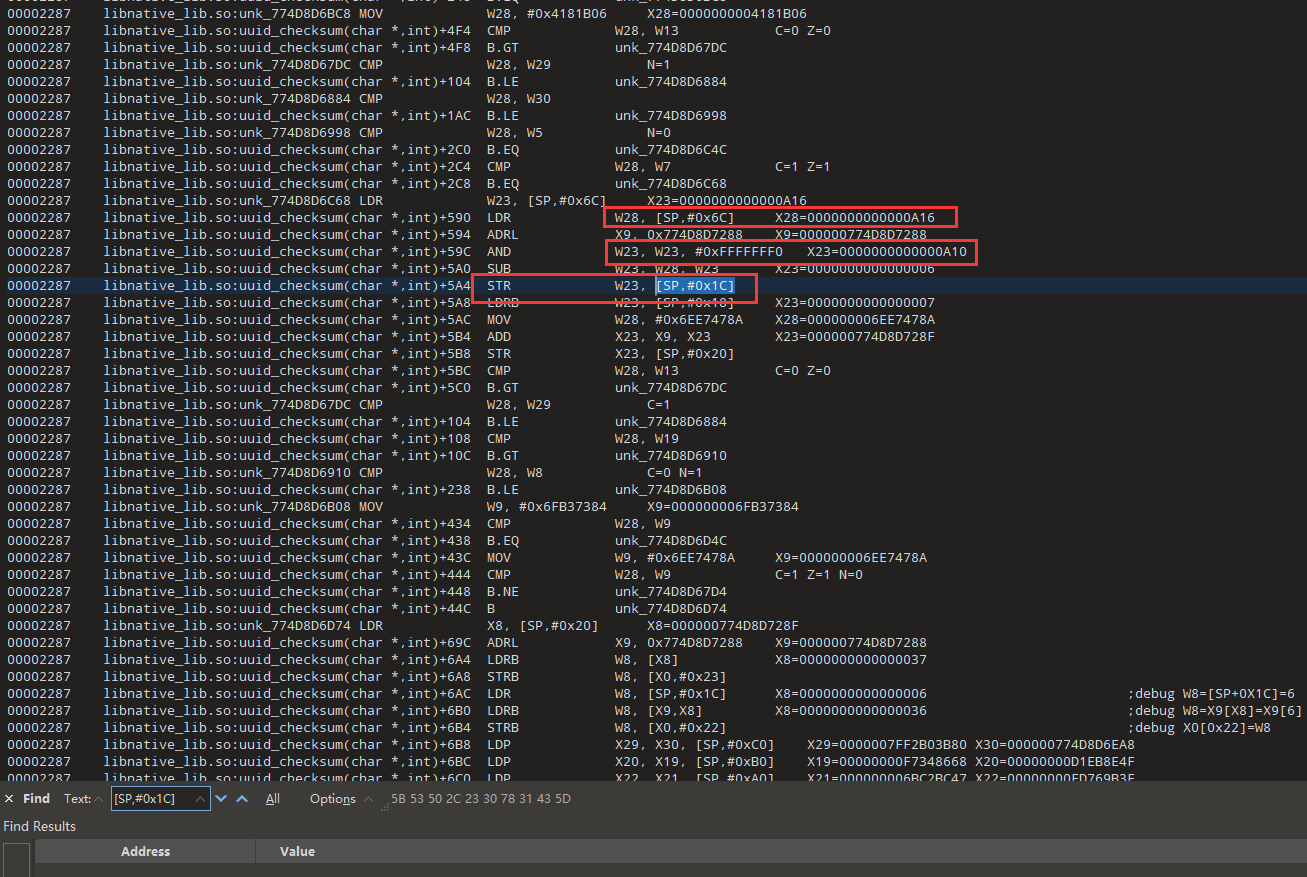
所以我们还得看看这个W28和W23怎么来的
W23=W28&0xFFFFFFF0,所以现在我们只需要关注W28就行了
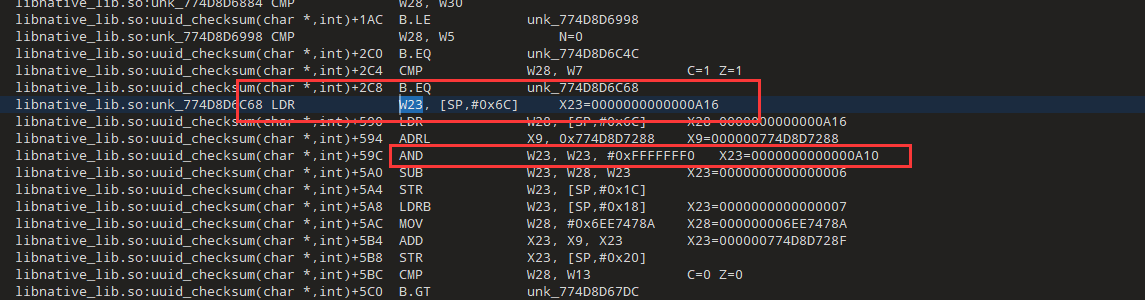
0xA16=0x9AA+0x6c
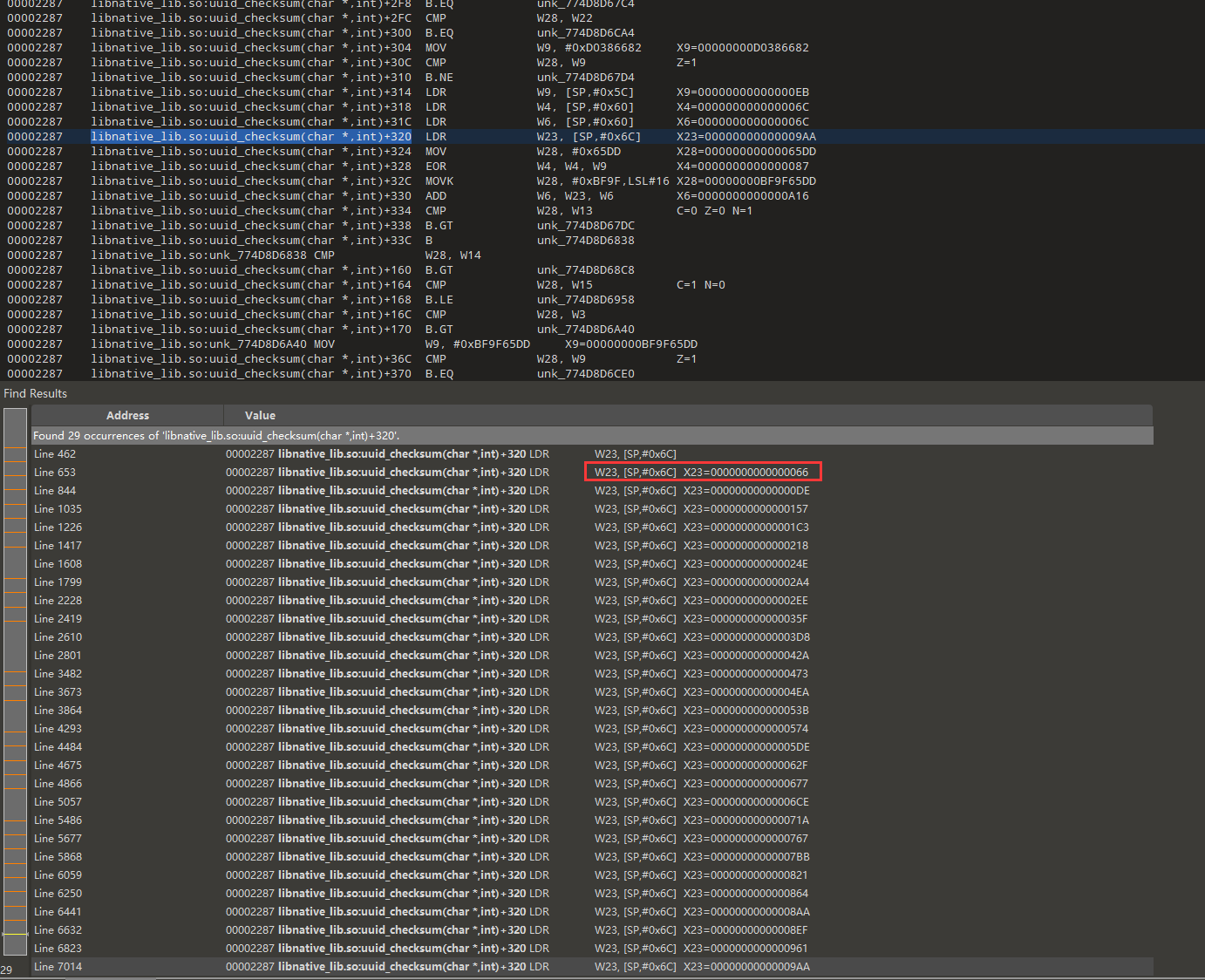
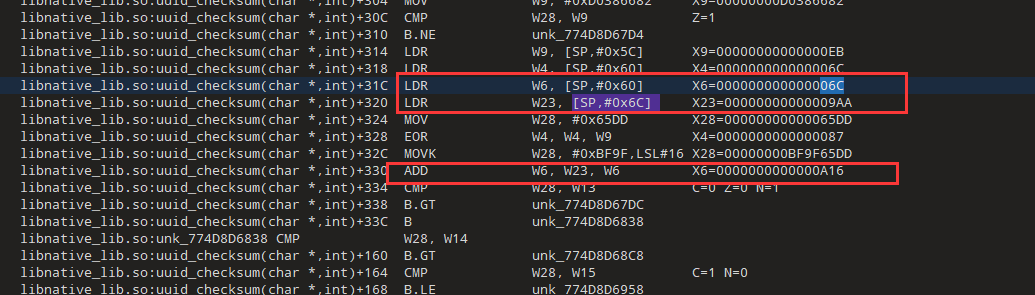
看样子是一个累加的过程,x23从0开始,然后加上0x66,而这个0x66是我们输入的第一个字符
我们现在先写个还原算法,前面的分析都是正确的
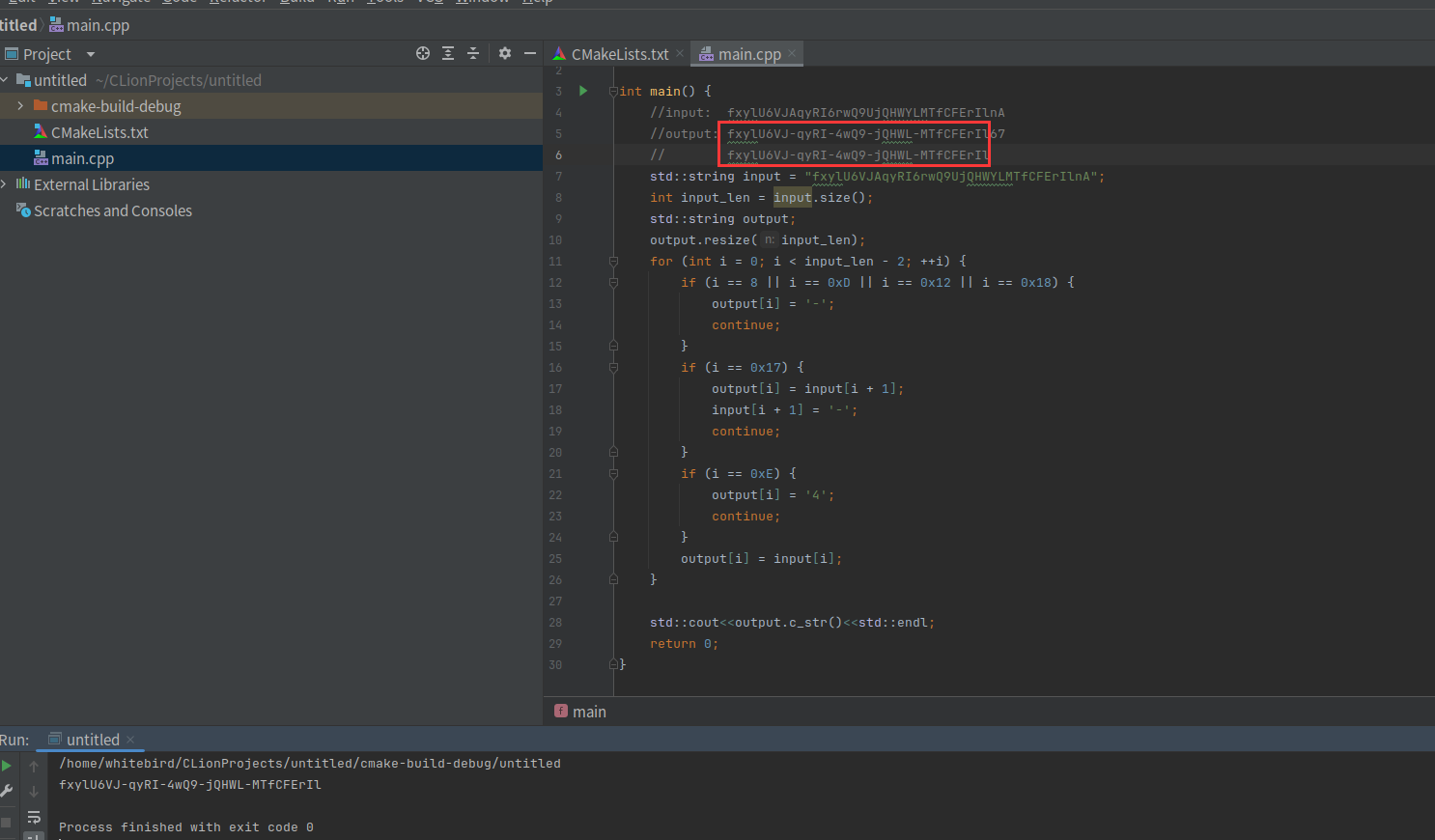
计算一下x23累加的过程
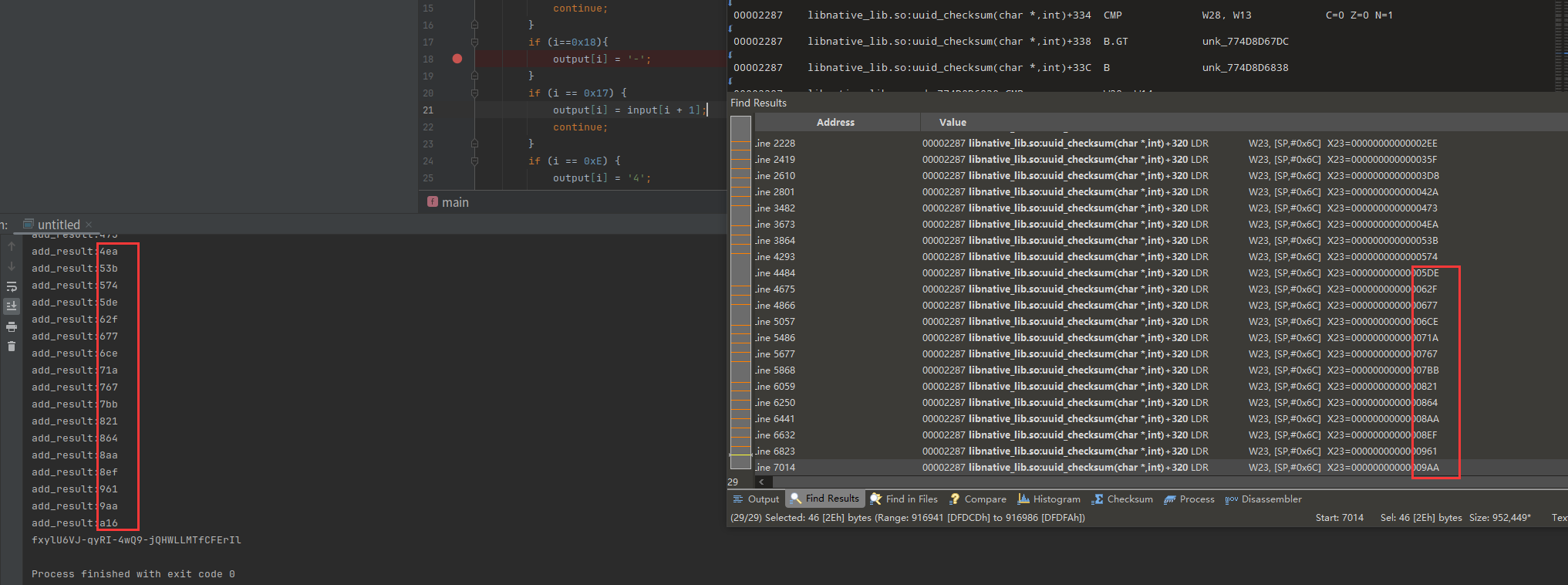
#include <iostream>
int main() {
//input: fxylU6VJAqyRI6rwQ9UjQHWYLMTfCFErIlnA
//output: fxylU6VJ-qyRI-4wQ9-jQHWL-MTfCFErIl67
// fxylU6VJ-qyRI-4wQ9-jQHWL-MTfCFErIl
std::string input = "fxylU6VJAqyRI6rwQ9UjQHWYLMTfCFErIlnA";
std::string table = "0123456789abcdef";
int input_len = input.size();
std::string output;
output.resize(input_len);
int add_result=0;
for (int i = 0; i < input_len - 2; ++i) {
if (i == 8 || i == 0xD || i == 0x12) {
output[i] = '-';
continue;
}
if (i == 0x17) {
output[i] = input[i + 1];
continue;
}
if (i == 0xE) {
output[i] = '4';
continue;
}
output[i] = input[i];
if (i==0x18){
output[i] = '-';
}
add_result += input[i];
//std::cout<<"add_result:"<< std::hex <<add_result<<std::endl;
}
output[0x22]=table[add_result-(add_result&0xFFFFFFF0)];
std::cout<<output.c_str()<<std::endl;
return 0;
}倒数第二位复现完了,我们继续分析最后一位
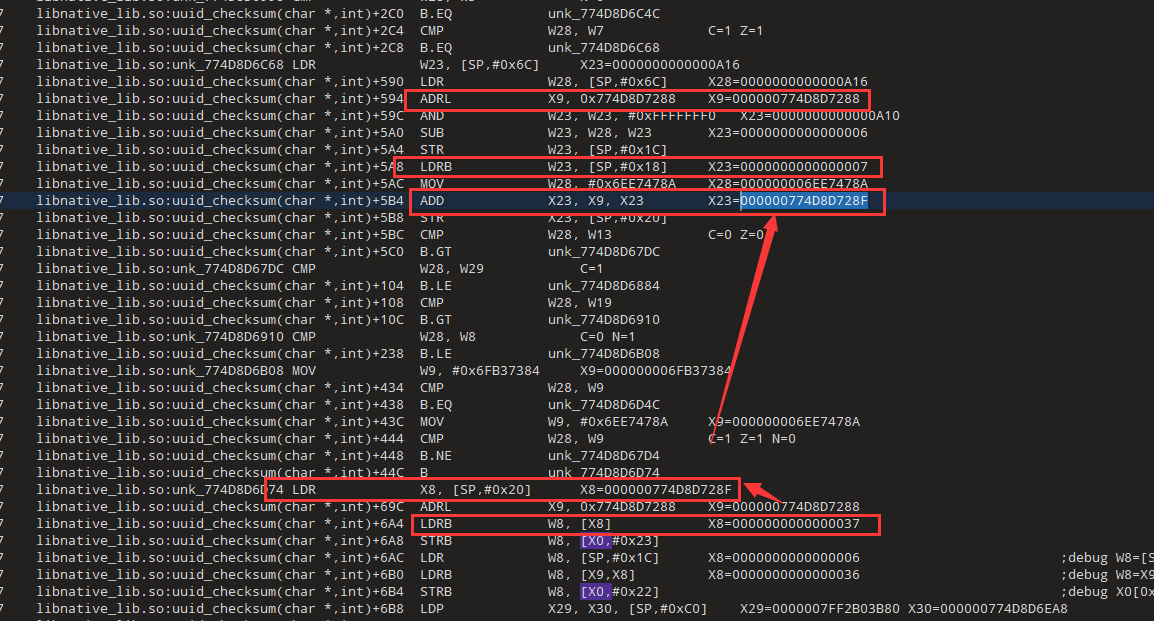
和上面类似,但是这里x23取值是7,x9还是table,我们继续跟x23来源
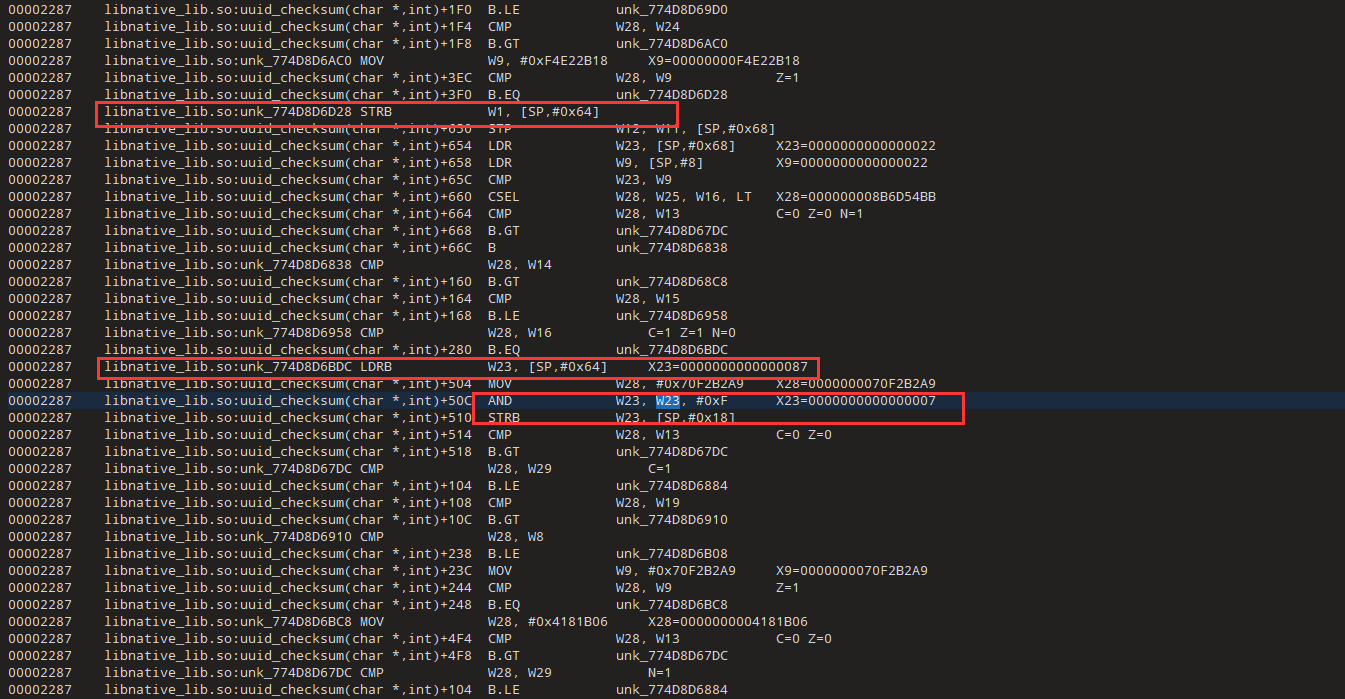
x23=x23&0xF=0x87&0xF=7,跟一下0x87的来源,也就是跟W1
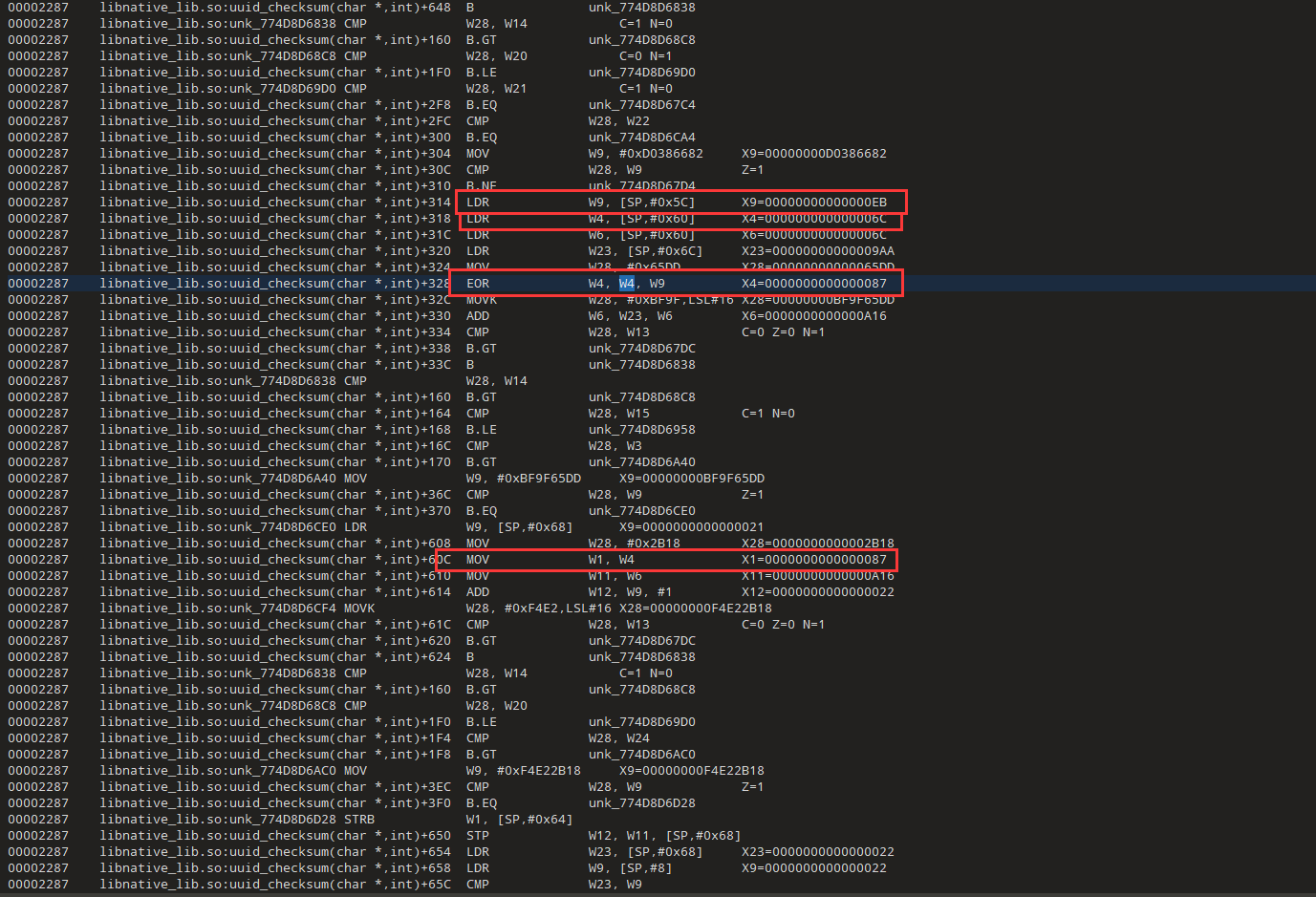
W1=W4=W4^W9=0xEB^0x6c
搜搜一下libnative_lib.so:uuid_checksum(char *,int)+328,类似上面的add,这里是xor
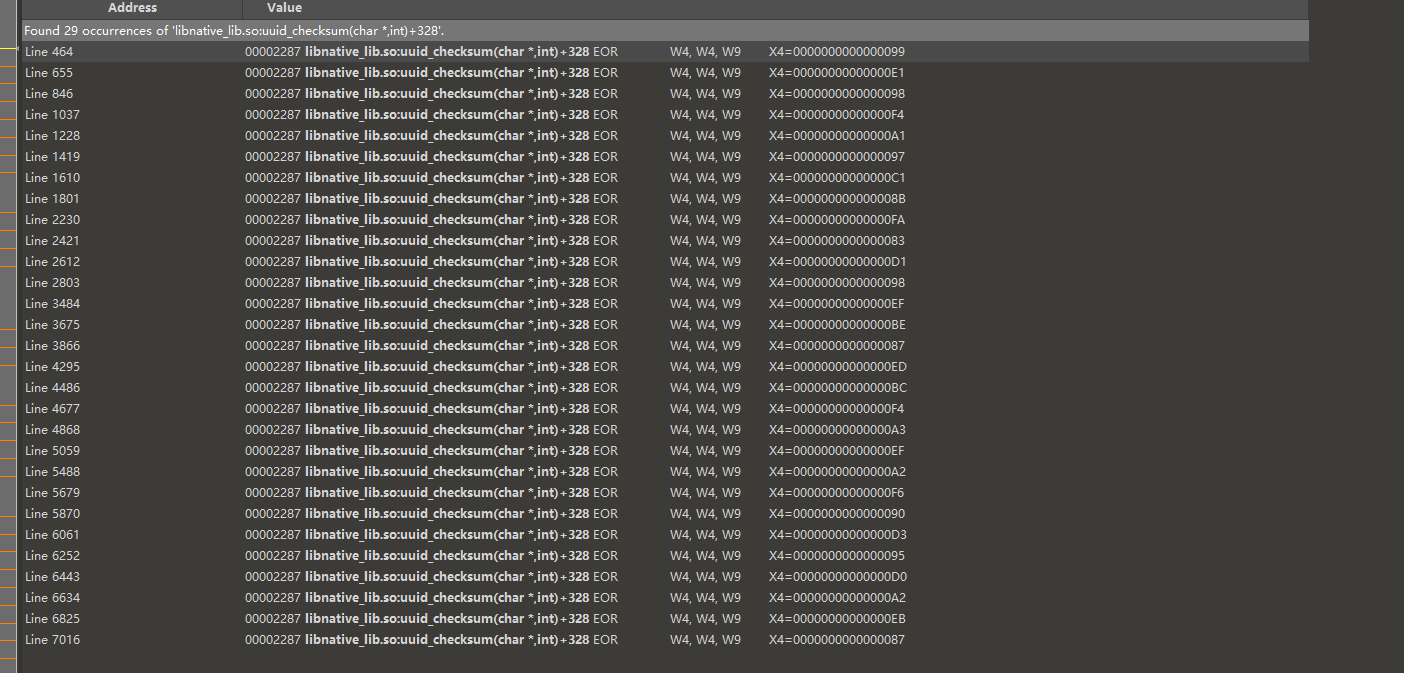
默认初始值0xff,我们第一个字符就是0x66
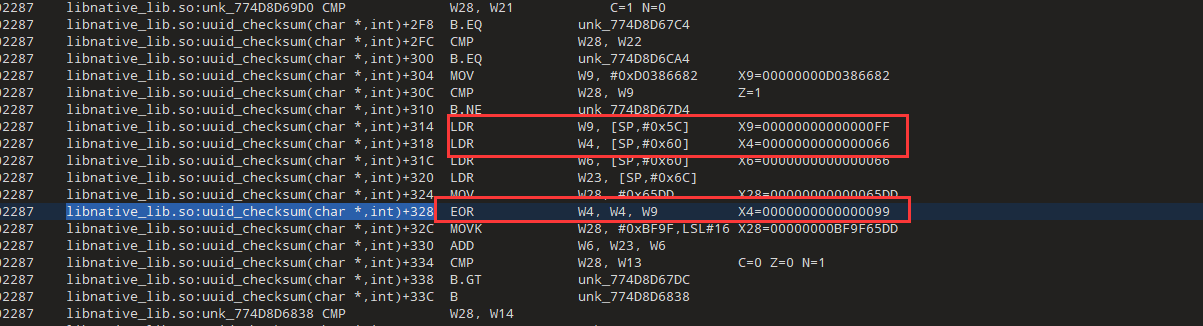
#include <iostream>
int main() {
//input: fxylU6VJAqyRI6rwQ9UjQHWYLMTfCFErIlnA
//output: fxylU6VJ-qyRI-4wQ9-jQHWL-MTfCFErIl67
// fxylU6VJ-qyRI-4wQ9-jQHWL-MTfCFErIl
std::string input = "fxylU6VJAqyRI6rwQ9UjQHWYLMTfCFErIlnA";
std::string table = "0123456789abcdef";
int input_len = input.size();
std::string output;
output.resize(input_len);
int add_result=0;
int xor_result=0xff;
for (int i = 0; i < input_len - 2; ++i) {
if (i == 8 || i == 0xD || i == 0x12) {
output[i] = '-';
continue;
}
if (i == 0x17) {
output[i] = input[i + 1];
continue;
}
if (i == 0xE) {
output[i] = '4';
continue;
}
output[i] = input[i];
if (i == 0x18){
output[i] = '-';
}
add_result += input[i];
xor_result ^= input[i];
//std::cout<<std::hex<<i<<" xor_result:"<< std::hex <<xor_result<<std::endl;
}
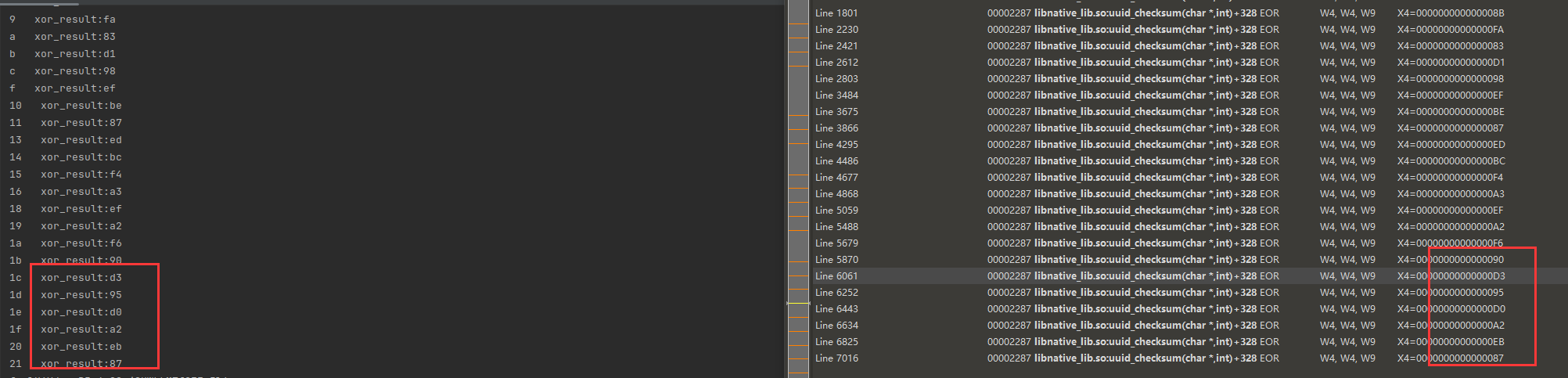
output[0x22]=table[add_result-(add_result&0xFFFFFFF0)];
output[0x23]=table[xor_result&0xf];
std::cout<<output.c_str()<<std::endl;
return 0;
}
我们现在去app多拿几组数据做验证
input: dOYWGxKmig8YJgr9jqMSEk9t2VyWhKObkbgt output: dOYWGxKm-g8YJ-49jq-SEk92-VyWhKObkb54
input: 43ddQZ4xR2taRGOxmFdlUsk3yGw2tDHgNGHZ output: 43ddQZ4x-2taR-4xmF-lUsky-Gw2tDHgNGe5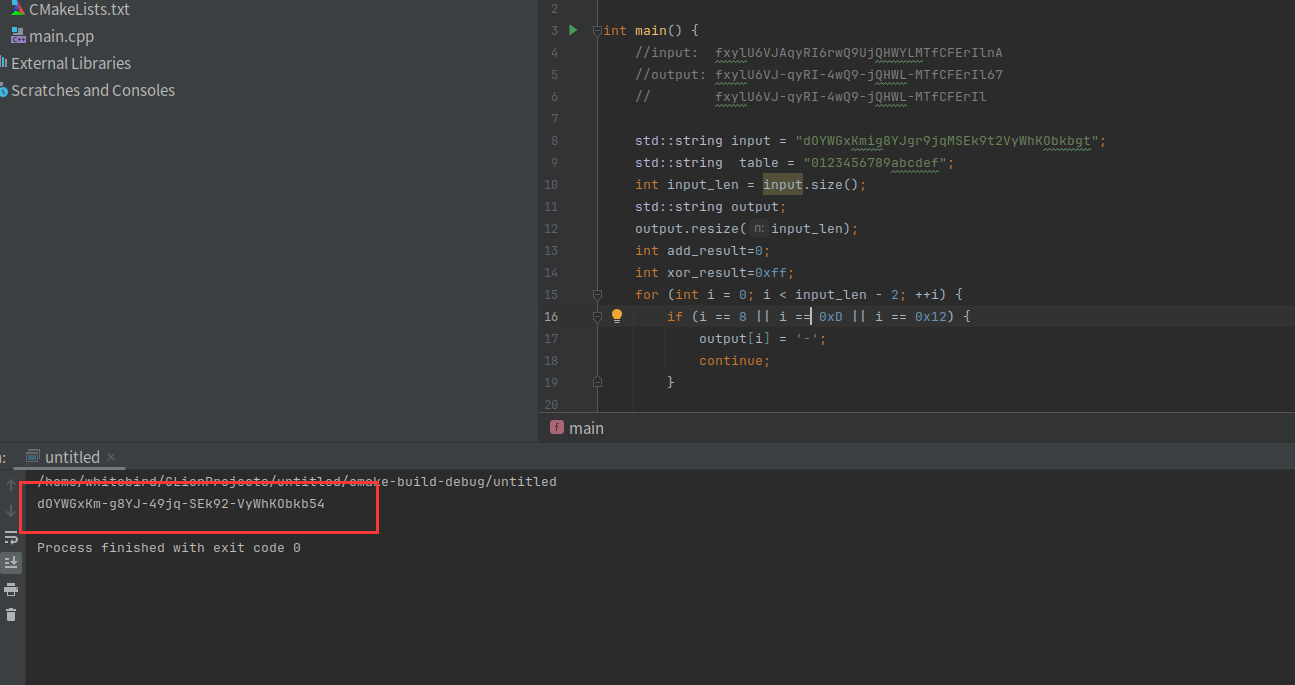
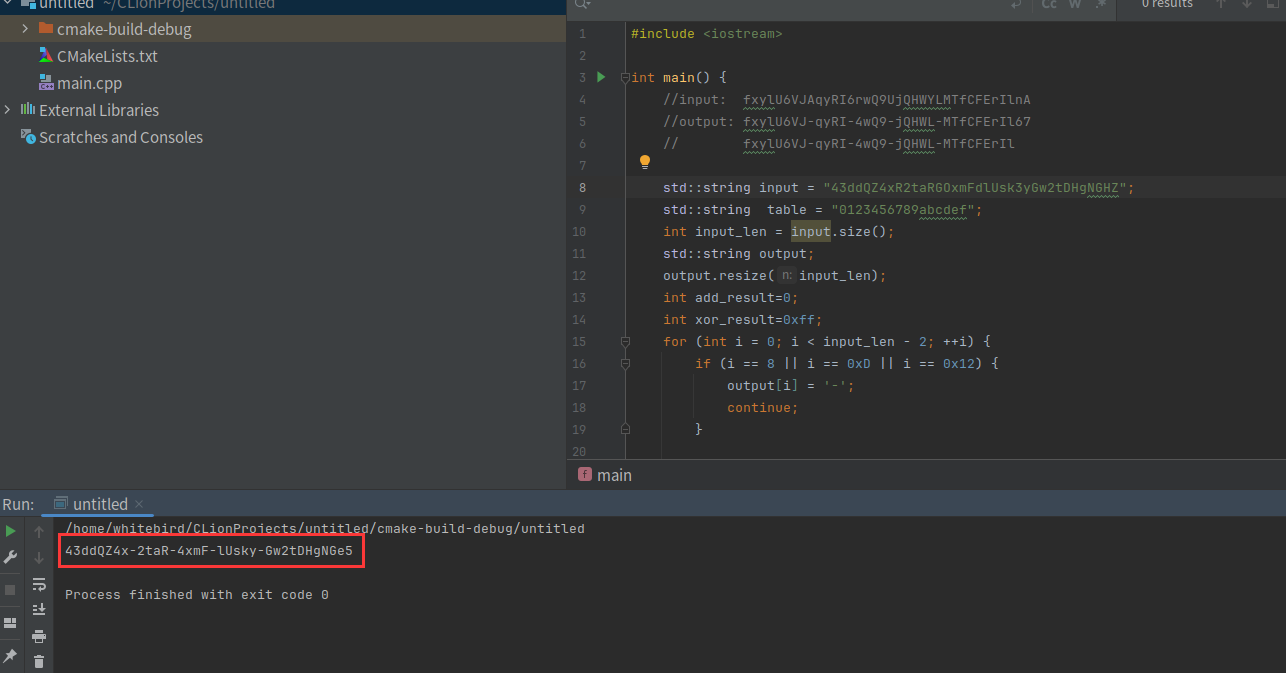
所以我们的算法还原正确。
26、利用unicorn分析OLLVM混淆的算法
unicorn相当于是一个cpu的模拟器,可以用来执行so中的代码段,一般不要直接使用apk中的so文件,直接使用是需要修复上下文的,这样会比较复杂。最好是直接从内存中直接dump一个so出来。然后就可以直接执行so里面的代码段。
我们先把apk跑起来,还是上一节的demo,然后从内存中把so给dump出来
用了这个项目https://github.com/lasting-yang/frida_dump/
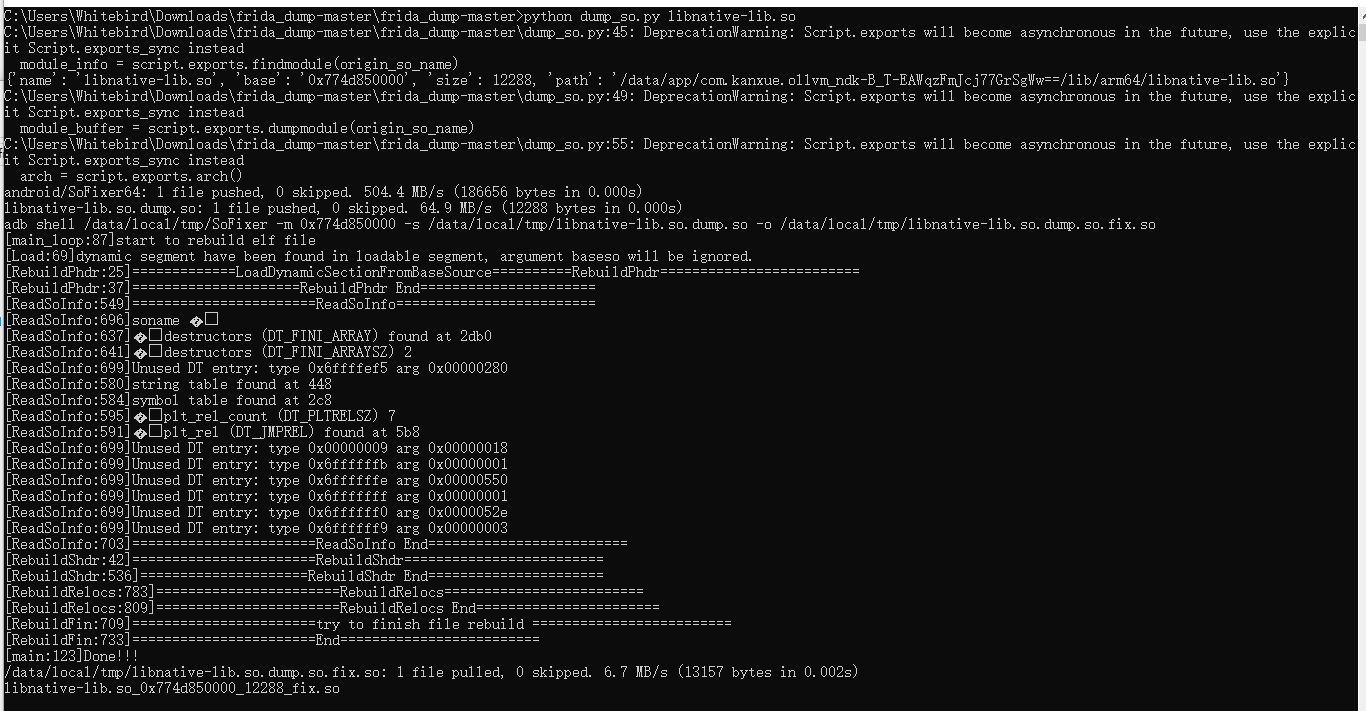
此时的so已经被pull到当前目录下了
现在创建一个目录,里面存放脚本和dump下来的so
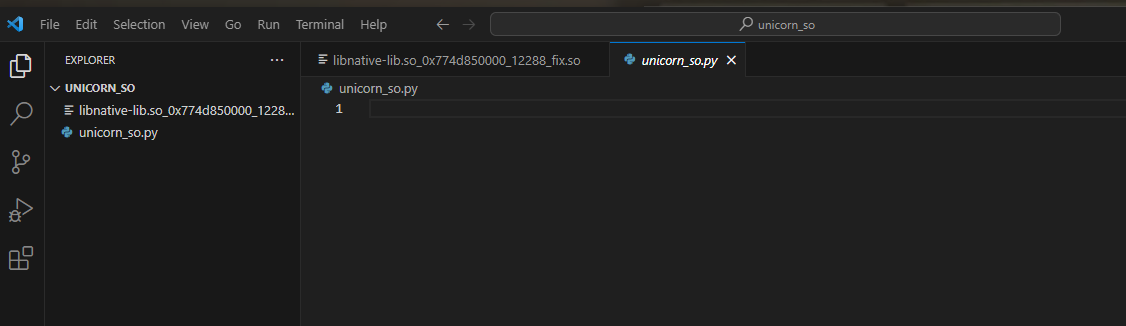
我们需要安装unicorn
pip install unicorn
import unicorn
import binascii
import string
if __name__ =="__main__":
uc = unicorn.Uc(unicorn.UC_ARCH_ARM64, unicorn.UC_MODE_ARM)
# libnative-lib.so_0x774d850000_12288_fix.so
#申请内存用来存放代码段
code_base = 0x774d850000
code_size = 8 * 0x1000 * 0x1000
uc.mem_map(code_base, code_size)
#申请内存用来当堆栈
stack_addr = code_base + code_size
stack_size = 0x1000 * 0x1000
stack_top = stack_addr + stack_size - 8
uc.mem_map(stack_addr, stack_size)
#申请内存用来存放参数
param_addr = stack_addr + stack_size
param_size = 0x1000 * 0x1000
uc.mem_map(param_addr, param_size)
with open("libnative-lib.so_0x774d850000_12288_fix.so", "rb") as f:
so_data = f.read()
#把dump的so写入到我们申请的内存中
uc.mem_write(code_base, so_data)
#要调用的函数起始位置与结束位置
start_addr = code_base + 0x6DC
end_addr = code_base + 0xDB0
#input: dOYWGxKmig8YJgr9jqMSEk9t2VyWhKObkbgt output: dOYWGxKm-g8YJ-49jq-SEk92-VyWhKObkb54
input_str = "dOYWGxKmig8YJgr9jqMSEk9t2VyWhKObkbgt"
print(input_str, end=" -> ")
#写入参数
input_bytes = str.encode(input_str)
uc.mem_write(param_addr, input_bytes)
#设置参数0,也就是给x0寄存器赋值,是input的地址
uc.reg_write(unicorn.arm64_const.UC_ARM64_REG_X0, param_addr)
#设置参数1,也就是给x1寄存器赋值,是input的长度
uc.reg_write(unicorn.arm64_const.UC_ARM64_REG_X1, len(input_str))
#设置堆栈的栈顶,也就是sp寄存器
uc.reg_write(unicorn.arm64_const.UC_ARM64_REG_SP, stack_top)
#开始调用函数
uc.emu_start(start_addr, end_addr)
#把结果再读取出来
result = uc.mem_read(param_addr, len(input_str))
#解码打印
print(result.decode())
pass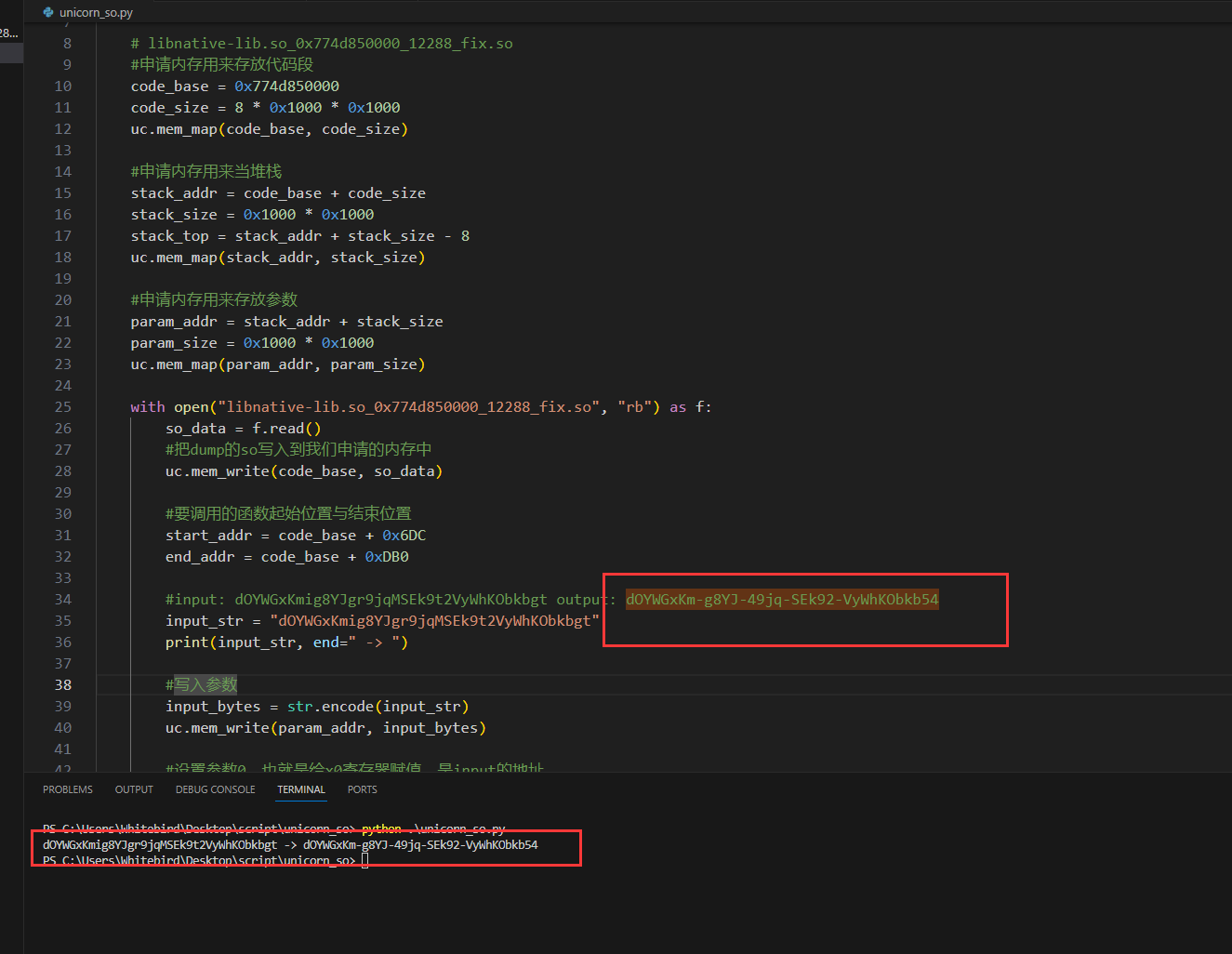
得到的结果和logcat里生成的结果是一样的,调用成功
现在我们装一个工具**capstone**

capstone是一个反汇编引擎 ,最重要功能是把二进制转化为汇编语言
trace实现代码如下
import unicorn
import binascii
import string
from capstone import *
reg_name = {
unicorn.arm64_const.UC_ARM64_REG_X0: "X0",
unicorn.arm64_const.UC_ARM64_REG_X1: "X1",
unicorn.arm64_const.UC_ARM64_REG_X2: "X2",
unicorn.arm64_const.UC_ARM64_REG_X3: "X3",
unicorn.arm64_const.UC_ARM64_REG_X4: "X4",
unicorn.arm64_const.UC_ARM64_REG_X5: "X5",
unicorn.arm64_const.UC_ARM64_REG_X6: "X6",
unicorn.arm64_const.UC_ARM64_REG_X7: "X7",
unicorn.arm64_const.UC_ARM64_REG_X8: "X8",
unicorn.arm64_const.UC_ARM64_REG_X9: "X9",
unicorn.arm64_const.UC_ARM64_REG_X10: "X10",
unicorn.arm64_const.UC_ARM64_REG_X11: "X11",
unicorn.arm64_const.UC_ARM64_REG_X12: "X12",
unicorn.arm64_const.UC_ARM64_REG_X13: "X13",
unicorn.arm64_const.UC_ARM64_REG_X14: "X14",
unicorn.arm64_const.UC_ARM64_REG_X15: "X15",
unicorn.arm64_const.UC_ARM64_REG_X16: "X16",
unicorn.arm64_const.UC_ARM64_REG_X17: "X17",
unicorn.arm64_const.UC_ARM64_REG_X18: "X18",
unicorn.arm64_const.UC_ARM64_REG_X19: "X19",
unicorn.arm64_const.UC_ARM64_REG_X20: "X20",
unicorn.arm64_const.UC_ARM64_REG_X21: "X21",
unicorn.arm64_const.UC_ARM64_REG_X22: "X22",
unicorn.arm64_const.UC_ARM64_REG_X23: "X23",
unicorn.arm64_const.UC_ARM64_REG_X24: "X24",
unicorn.arm64_const.UC_ARM64_REG_X25: "X25",
unicorn.arm64_const.UC_ARM64_REG_X26: "X26",
unicorn.arm64_const.UC_ARM64_REG_X27: "X27",
unicorn.arm64_const.UC_ARM64_REG_X28: "X28"
}
md =Cs(CS_ARCH_ARM64, CS_MODE_ARM)
md.detail=True
all_regs = None
def hook_code(uc: unicorn.Uc, address, size, user_data):
global all_regs
if(all_regs is None):
all_regs={}
#遍历每个寄存器
for reg_index in range(unicorn.arm64_const.UC_ARM64_REG_X0, unicorn.arm64_const.UC_ARM64_REG_X28):
reg_value = uc.reg_read(reg_index)
#对每个寄存器进行赋值
all_regs[reg_index] = reg_value
if (reg_value != 0):
#如果寄存器值不为0,就打印出来
print("%s=0x%x" % (reg_name[reg_index], reg_value), end=" ")
print("")
else:
is_changed = False
#遍历每个寄存器
for reg_index in range(unicorn.arm64_const.UC_ARM64_REG_X0, unicorn.arm64_const.UC_ARM64_REG_X28):
reg_value = uc.reg_read(reg_index)
#判断寄存器原来的值和现在的值是否相同,不同进入循环
if (all_regs[reg_index] != reg_value):
is_changed = True
#把新的值赋值给原来的寄存器
all_regs[reg_index] = reg_value
print("")
#打印寄存器中新的值
print("%s=0x%x" % (reg_name[reg_index], reg_value), end=" ")
print("")
if is_changed:
print("")
inst_code = uc.mem_read(address,size)
for insn in md.disasm(inst_code, size):
print("0x%x:\t%s\t%s" % (address, insn.mnemonic, insn.op_str))
#print(hex(address),size,binascii.b2a_hex(inst_code))
pass
if __name__ =="__main__":
uc = unicorn.Uc(unicorn.UC_ARCH_ARM64, unicorn.UC_MODE_ARM)
# libnative-lib.so_0x774d850000_12288_fix.so
#申请内存用来存放代码段
code_base = 0x774d850000
code_size = 8 * 0x1000 * 0x1000
uc.mem_map(code_base, code_size)
#申请内存用来当堆栈
stack_addr = code_base + code_size
stack_size = 0x1000 * 0x1000
stack_top = stack_addr + stack_size - 8
uc.mem_map(stack_addr, stack_size)
#申请内存用来存放参数
param_addr = stack_addr + stack_size
param_size = 0x1000 * 0x1000
uc.mem_map(param_addr, param_size)
uc.hook_add(unicorn.UC_HOOK_CODE,hook_code)
uc.hook_add(unicorn.UC_HOOK_CODE, hook_code)
with open("libnative-lib.so_0x774d850000_12288_fix.so", "rb") as f:
so_data = f.read()
#把dump的so写入到我们申请的内存中
uc.mem_write(code_base, so_data)
#要调用的函数起始位置与结束位置
start_addr = code_base + 0x6DC
end_addr = code_base + 0xDB0
#input: dOYWGxKmig8YJgr9jqMSEk9t2VyWhKObkbgt output: dOYWGxKm-g8YJ-49jq-SEk92-VyWhKObkb54
input_str = "dOYWGxKmig8YJgr9jqMSEk9t2VyWhKObkbgt"
#print(input_str, end=" -> ")
#写入参数
input_bytes = str.encode(input_str)
uc.mem_write(param_addr, input_bytes)
#设置参数0,也就是给x0寄存器赋值,是input的地址
uc.reg_write(unicorn.arm64_const.UC_ARM64_REG_X0, param_addr)
#设置参数1,也就是给x1寄存器赋值,是input的长度
uc.reg_write(unicorn.arm64_const.UC_ARM64_REG_X1, len(input_str))
#设置堆栈的栈顶,也就是sp寄存器
uc.reg_write(unicorn.arm64_const.UC_ARM64_REG_SP, stack_top)
#开始调用函数
uc.emu_start(start_addr, end_addr)
#把结果再读取出来
result = uc.mem_read(param_addr, len(input_str))
#解码打印
#print(result.decode())
uc.mem_unmap(param_addr, param_size)
uc.mem_unmap(stack_addr, stack_size)
uc.mem_unmap(code_base, code_size)
pass得到执行的汇编代码和对应的寄存器值
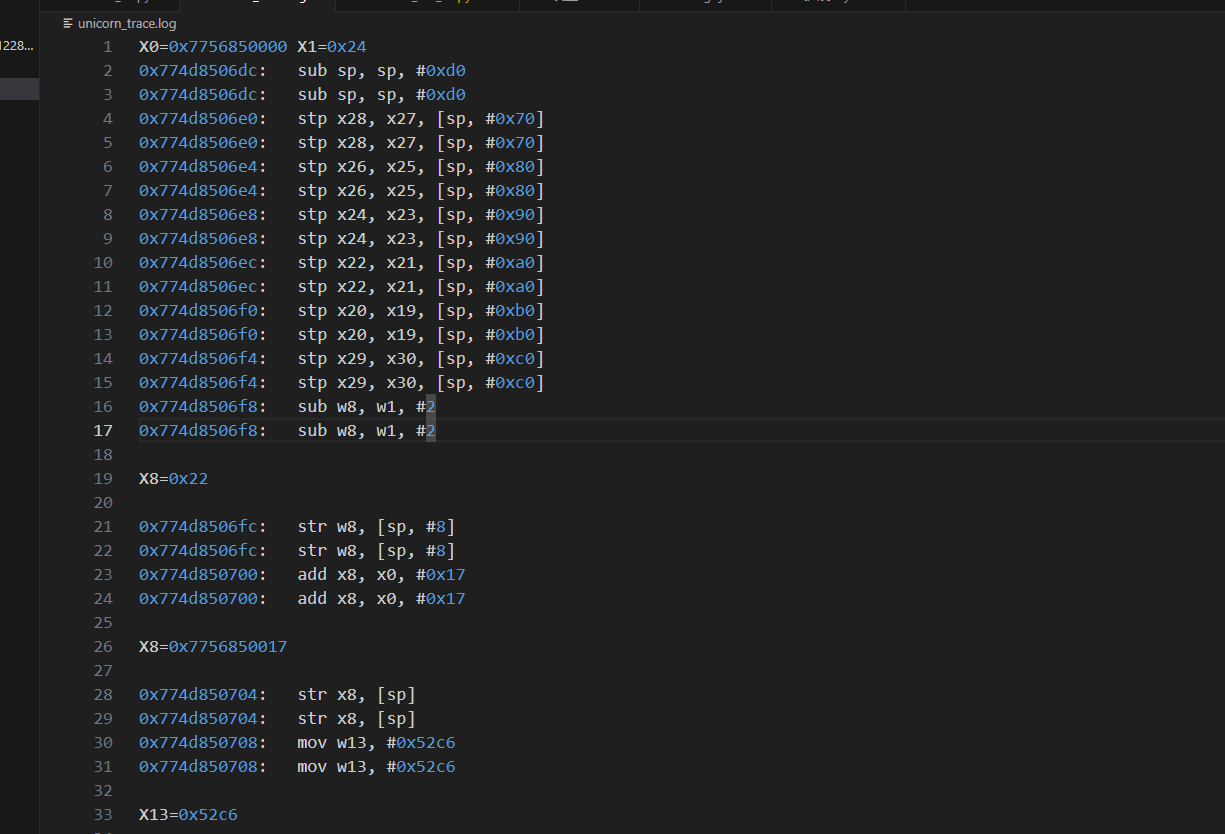
剩下的分析过程和之前的类似,就不展开了。
27、总结
到此LLVM与OLLVM的基础知识已经具备,回过头来思考仍有许多不足,需要加强的地方:
1、开发OLLVM-Pass,在IR层做处理时对于LLVM操作IR的API不熟悉
2、尝试阅读理解OLLVM自带的字符串加密Pass
3、深入学习unicorn和capstone
4、阅读一些网上关于去混淆的文章,总结去混淆的经验和技巧
这些问题会在后面的学习过程中逐步解决并写成文章。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 767778848@qq.com